Introducing GPT-4.1: The Best AI Image Generator with Enhanced Performance
4/16/2025
According to reports from Zhihui Machine, OpenAI's new series of models, GPT-4.1, has arrived as promised early this morning.  This series includes three models: GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano, all accessible via API calls and open to all developers. With these models offering similar or superior performance on many key features while reducing costs and latency, OpenAI plans to deprecate the GPT-4.5 preview version in three months (July 14, 2025), granting developers time for transition. OpenAI has stated that these three models significantly outperform GPT-4o and GPT-4o mini, especially in programming and instruction following tasks. They also come with a larger context window—supporting up to 1 million context tokens—enabling better utilization of these contexts through improved long context comprehension. The knowledge cutoff date has been updated to June 2024. Overall, GPT-4.1 excels in the following industry-standard metrics:
This series includes three models: GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano, all accessible via API calls and open to all developers. With these models offering similar or superior performance on many key features while reducing costs and latency, OpenAI plans to deprecate the GPT-4.5 preview version in three months (July 14, 2025), granting developers time for transition. OpenAI has stated that these three models significantly outperform GPT-4o and GPT-4o mini, especially in programming and instruction following tasks. They also come with a larger context window—supporting up to 1 million context tokens—enabling better utilization of these contexts through improved long context comprehension. The knowledge cutoff date has been updated to June 2024. Overall, GPT-4.1 excels in the following industry-standard metrics:
- Programming: GPT-4.1 scored 54.6% in the SWE-bench Verified test, an improvement of 21.4% over GPT-4o and 26.6% over GPT-4.5, making it a leading programming model.
- Instruction Following: In Scale's MultiChallenge benchmark (a measure of instruction-following abilities), GPT-4.1 scored 38.3%, a 10.5% improvement over GPT-4o.
- Long Context: In the multimodal long context comprehension benchmark Video-MME, GPT-4.1 set a new high score of 72.0% in the long-form no subtitle test, which is 6.7% higher than GPT-4o.
Although the benchmark results are impressive, OpenAI placed significant emphasis on practical utility in training these models. By closely collaborating with the developer community, OpenAI optimized these models for tasks most relevant to developers. Consequently, the GPT-4.1 model series offers excellent performance at a lower cost. These models achieve performance improvements at every point on the latency curve. 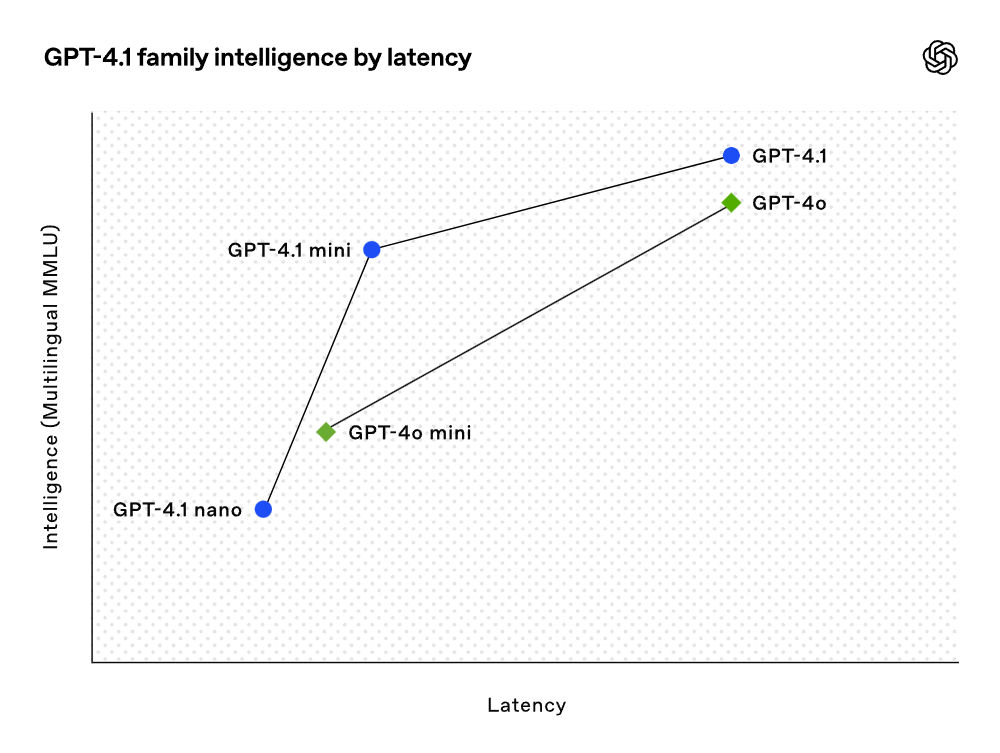
The GPT-4.1 mini has made significant leaps in the performance of smaller models, even surpassing GPT-4o in several benchmarks. This model has demonstrated comparable or even superior performance in intelligent assessments while reducing latency by nearly half and costs by 83%. For tasks requiring low latency, the GPT-4.1 nano is OpenAI's fastest and cheapest model to date. It comes with a 1 million token context window and continues to perform exceptionally well at smaller scales, achieving scores of 80.1% in MMLU tests, 50.3% in GPQA tests, and 9.8% in the Aider multilingual code testing, even outperforming GPT-4o mini. This model is ideal for tasks such as classification or auto-completion. Enhancements in instruction following reliability and long context comprehension also make the GPT-4.1 models more efficient in driving intelligent agents (systems that can independently complete tasks on behalf of users). By leveraging primitives like the Responses API, developers can now build more useful and reliable agents in practical software engineering scenarios that extract insights from large documents, address customer requests with minimal manual operation, and execute other complex tasks. Meanwhile, by improving the efficiency of the reasoning system, OpenAI has been able to reduce the pricing of the GPT-4.1 series. The cost of medium-scale queries for GPT-4.1 is 26% lower than that of GPT-4o, while GPT-4.1 nano is OpenAI's cheapest and fastest model to date. For repeated queries with the same context, OpenAI has increased the immediate caching discount for the new series model from the previous 50% to 75%. Additionally, besides the standard per-token costs, OpenAI now offers long context requests without any additional fees. 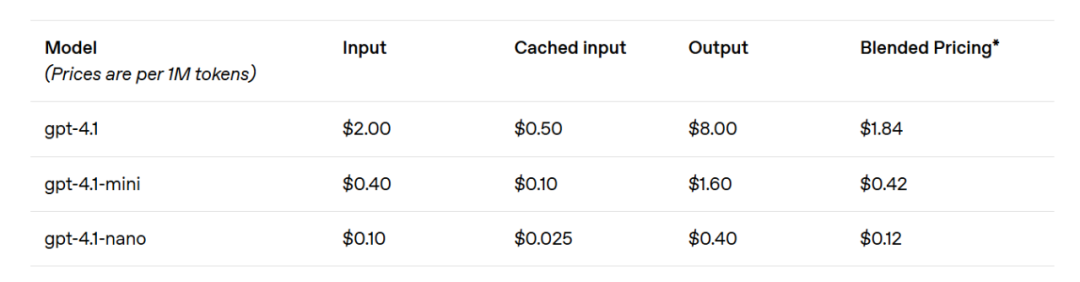
OpenAI CEO Sam Altman stated that GPT-4.1 not only performs exceptionally well in benchmark tests but also focuses on real-world practicality, which should please developers. 
It seems that OpenAI has achieved "4.10 > 4.5" in terms of its model capabilities. 
The programming capabilities of GPT-4.1 significantly outperform GPT-4o across various coding tasks, including agent-driven coding tasks, front-end programming, reducing irrelevant edits, reliable adherence to diff formats, and ensuring tool usage consistency. In the SWE-bench Verified test, which measures real-world software engineering skills, GPT-4.1 completed 54.6% of tasks, while GPT-4o (as of November 20, 2024) completed only 33.2%. This reflects the model's improvements in exploring codebases, completing tasks, and generating functional and test-passing code. 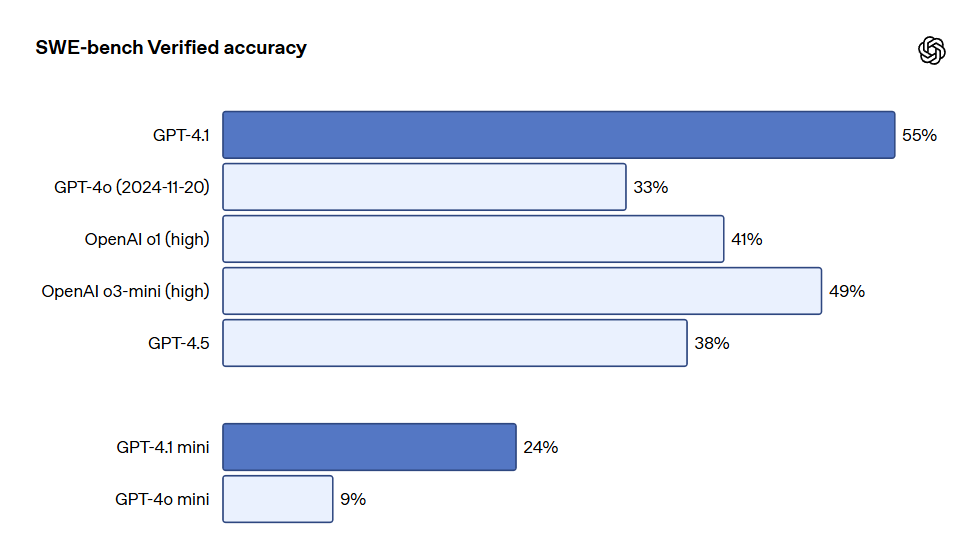
For API developers needing to edit large files, GPT-4.1 is more reliable in handling code diffs across various formats. In the Aider multilingual diff benchmark test, GPT-4.1's score was more than double that of GPT-4o and even surpassed GPT-4.5 by 8%. This assessment measures both coding abilities across multiple programming languages as well as the model's capability to generate changes in both overall and diff formats. OpenAI specifically trained GPT-4.1 to reliably follow diff formats, allowing developers to output only the changed lines without needing to rewrite the entire file, saving costs and reducing latency. Moreover, for developers who prefer to rewrite entire files, OpenAI has increased the output token limits for GPT-4.1 to 32,768 tokens (up from GPT-4o's 16,384 tokens). OpenAI also recommends using predictive outputs to minimize latency in fully rewriting files. 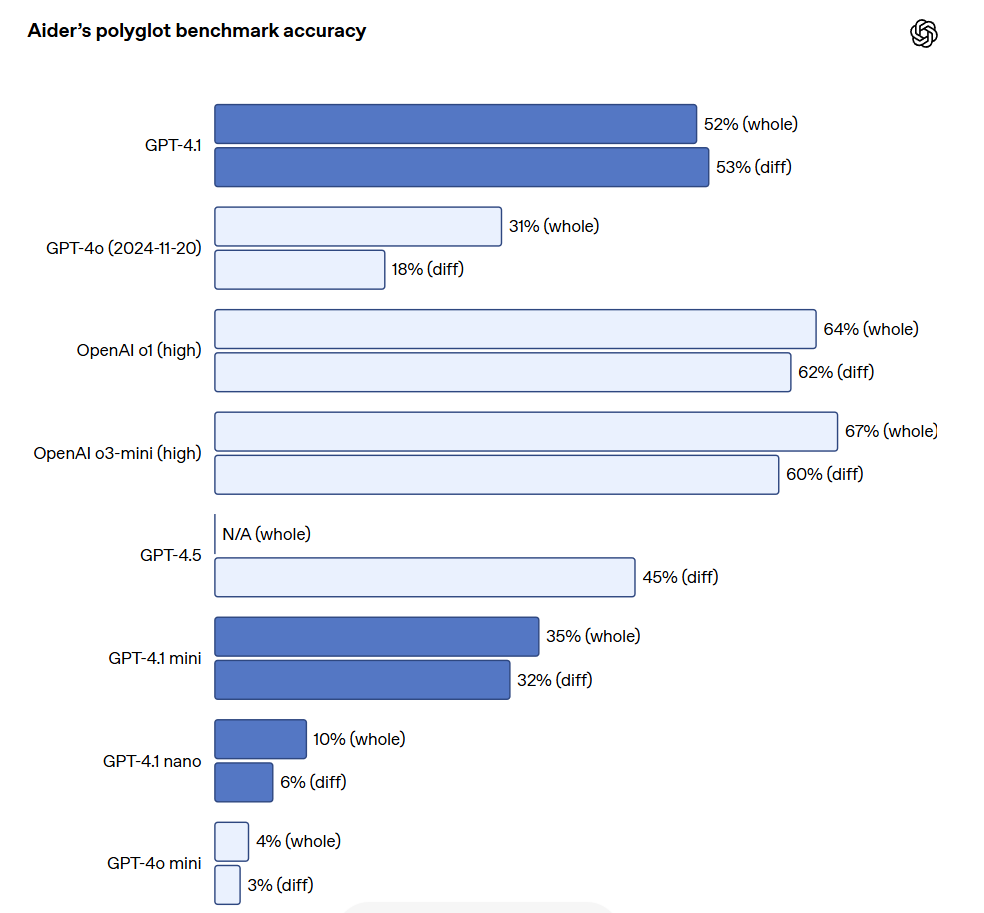
GPT-4.1 also shows a significant improvement in front-end programming, able to create more powerful and visually appealing web applications. In head-to-head comparisons, 80% of paid human graders rated GPT-4.1's websites as more favorable than those created by GPT-4o. 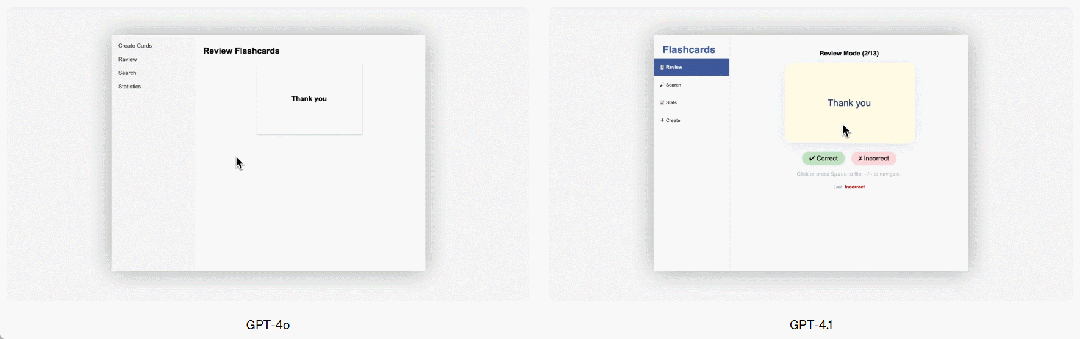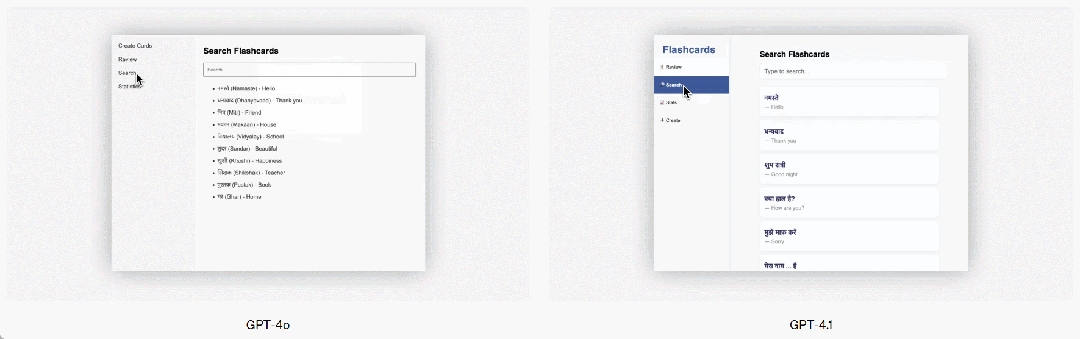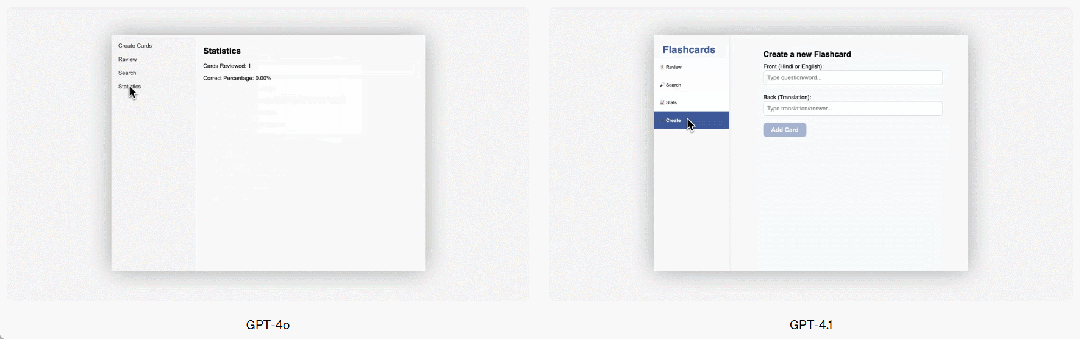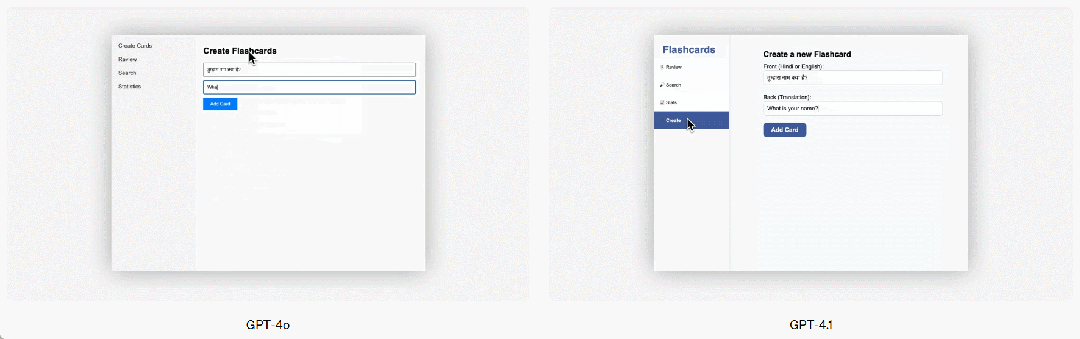
In addition to the aforementioned benchmark tests, GPT-4.1 exhibits better adherence to formats, higher reliability, and a reduction in the frequency of irrelevant edits. In OpenAI's internal assessments, irrelevant edits in code dropped from 9% in GPT-4o to 2% in GPT-4.1.
Instruction Following
GPT-4.1 is more reliable in following instructions and has achieved significant improvements across various instruction-following evaluations. OpenAI developed an internal instruction-following evaluation system to track the model's performance across several dimensions and key instruction execution categories, including:
- Format Following: Providing instructions that specify a custom format for the model’s response, such as XML, YAML, Markdown, etc.
- Negative Instructions: Specifying behaviors the model should avoid, such as "Do not ask users to contact support."
- Ordered Instructions: Providing a sequence of instructions that the model must follow in the given order, such as "First ask for the user's name, then ask for their email address."
- Content Requirements: Outputting content that includes specific information, such as "When writing a nutrition plan, be sure to include protein content."
- Sorting: Sorting the output in a specific way, such as "Sort responses by population."
- Overconfidence: Directing the model to say "I don't know" or similar when the requested information is unavailable or does not belong to the given category, such as "If you don’t know the answer, please provide a support contact email address."
These categories were derived from developer feedback, indicating which instruction following characteristics are most relevant and important to them. In each category, OpenAI categorized prompts into simple, medium, and difficult. GPT-4.1 showed particularly superior performance on challenging prompts. 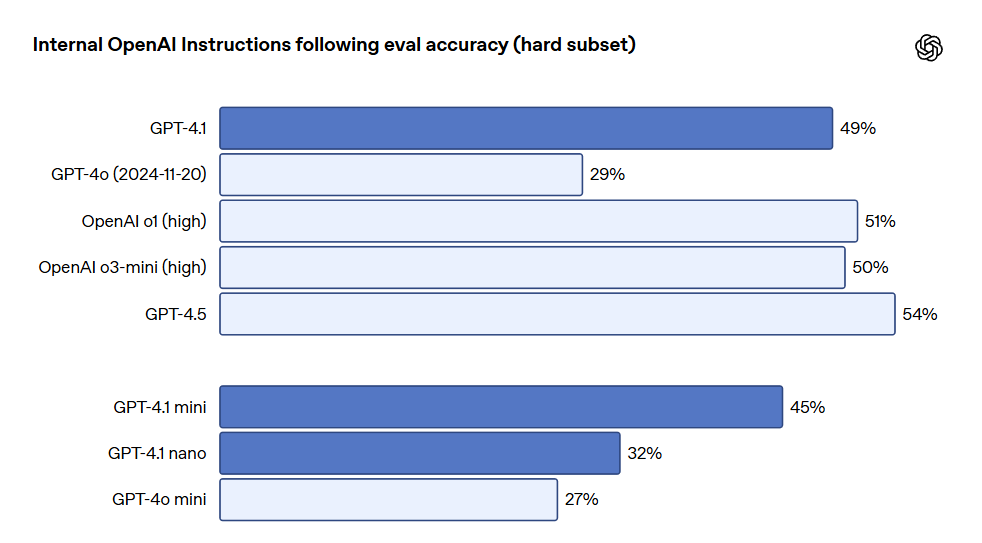
Multi-turn instruction following is crucial for many developers. For models, it's essential to maintain coherence in dialogues and track what users have entered previously. GPT-4.1 has improved in identifying information from past messages in conversations, resulting in more natural dialogues. The Scale MultiChallenge benchmark test serves as an effective measure of this capability, with GPT-4.1's performance improving by 10.5% over GPT-4o. 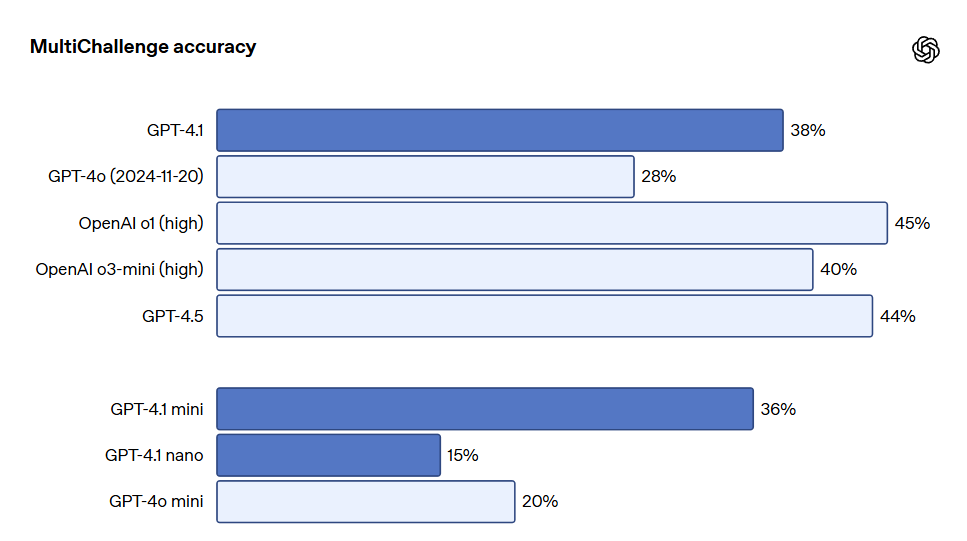
GPT-4.1 also scored 87.4% on IFEval, while GPT-4o scored 81.0%. IFEval uses prompts with verifiable instructions, such as specifying content length or avoiding certain terms or formats. 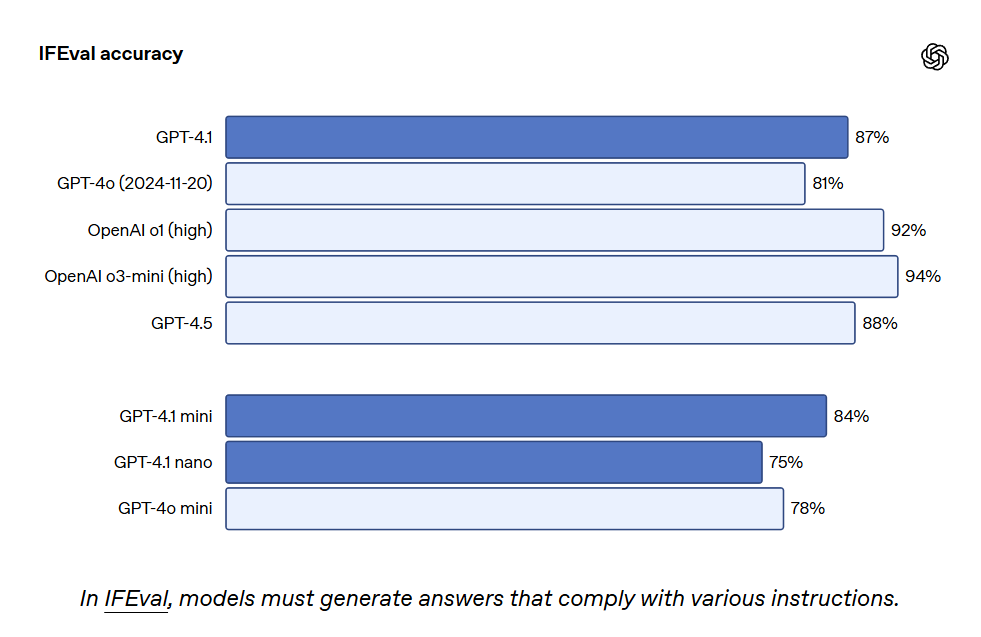
Better instruction-following capabilities enhance the reliability of existing applications and support new applications that were previously limited by low reliability. Early testers noted that GPT-4.1 is more intuitive, prompting OpenAI to suggest being clearer and more specific in prompts.
Long Context
GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano can handle up to 1 million context tokens, whereas the previous GPT-4o model could only handle 128,000 at most. One million tokens corresponds to eight complete React codebases, making long context particularly well-suited for handling large codebases or substantial long documents. GPT-4.1 can reliably manage information with a context length of 1 million tokens and is more adept at paying attention to relevant text while ignoring long and short context distractions than GPT-4o. Long context comprehension is a vital capability in legal, programming, customer support, and numerous other fields. 
OpenAI demonstrated GPT-4.1's ability to continuously and accurately retrieve hidden information (the needle) from various points within the context window. GPT-4.1 can effectively extract details relevant to the current task, to a maximum retrieval capacity of 1 million tokens, regardless of the location of these tokens in the input. However, in the real world, few tasks are as straightforward as retrieving a conspicuous "needle" answer. OpenAI found that users often need the model to retrieve and comprehend multiple pieces of information while understanding the interrelations between these pieces. To showcase this capability, OpenAI has open-sourced a new evaluation: OpenAI-MRCR (Multi-Round Coreference). OpenAI-MRCR tests the model's ability to recognize and eliminate multiple "needles" hidden within the context. The evaluation includes multi-turn synthetic dialogues between users and assistants, where the user requests the assistant to write an article on a specific topic, such as "Write a poem about tapirs" or "Write a blog post about rocks," followed by inserting two, four, or eight identical requests throughout the context. The model must then retrieve the response corresponding to a specific instance (for example, "Give me the third poem about tapirs"). The challenge lies in the similarity of these requests to the remaining context, as the model can be easily misled by subtle differences, such as a short story about tapirs instead of a poem, or a poem about frogs instead of tapirs. OpenAI discovered that GPT-4.1 performs better than GPT-4o with context lengths of up to 128K tokens and maintains strong performance even at lengths of up to 1 million tokens. 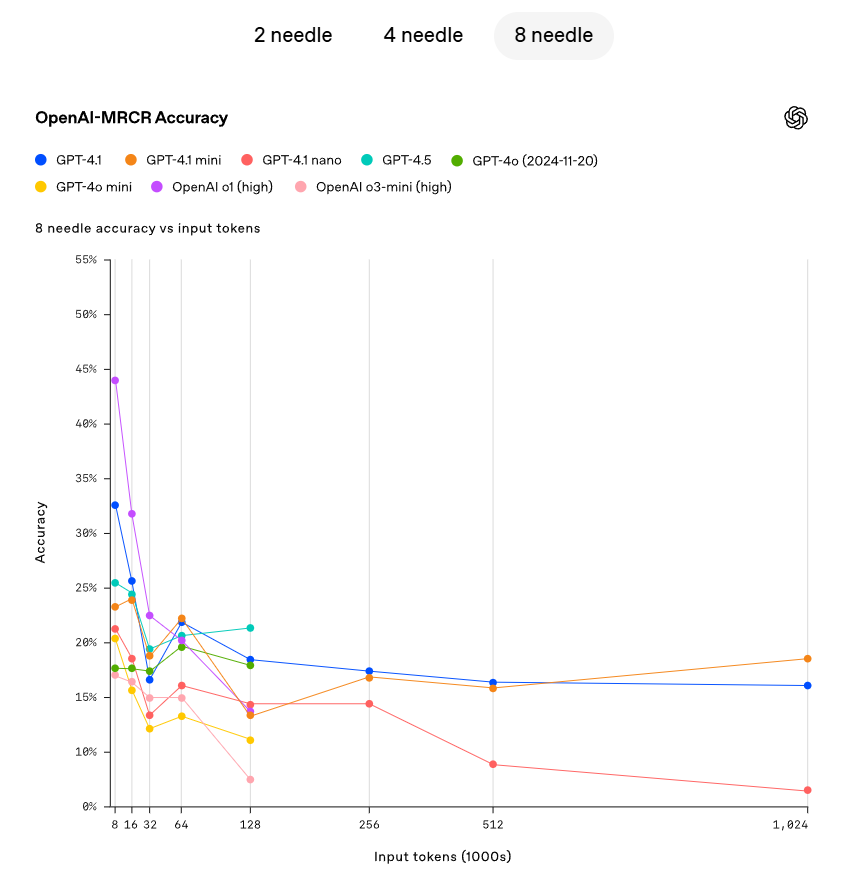
OpenAI also released Graphwalks, a dataset for evaluating multi-hop long-context reasoning. Many developers need to make multiple logical leaps within contexts in long-context use cases, such as jumping between multiple files while writing code or cross-referencing documents when answering complex legal inquiries. Theoretically, models (and even humans) can solve OpenAI-MRCR problems by repeatedly reading prompts, but Graphwalks' design requires reasoning from multiple positions within the context without a sequential resolution. Graphwalks fills the context window with directed graphs composed of hexadecimal hash values and then prompts models to perform a breadth-first search (BFS) starting from random nodes in the graph. It then requires the model to return all nodes at a certain depth. Results show that GPT-4.1 achieved an accuracy of 61.7% in this benchmark test, comparable to the performance of o1, and easily outperformed GPT-4o. 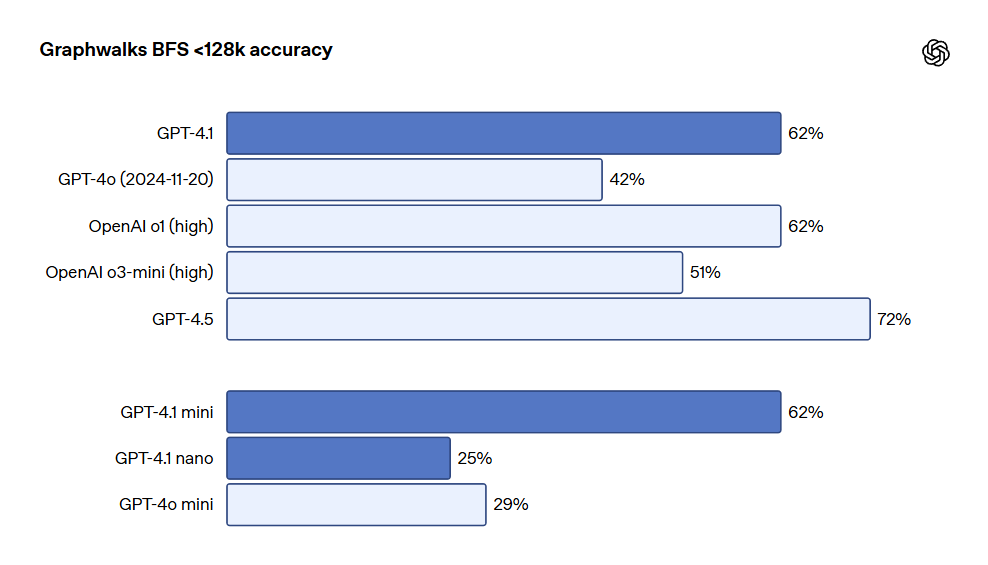
Visual Capability
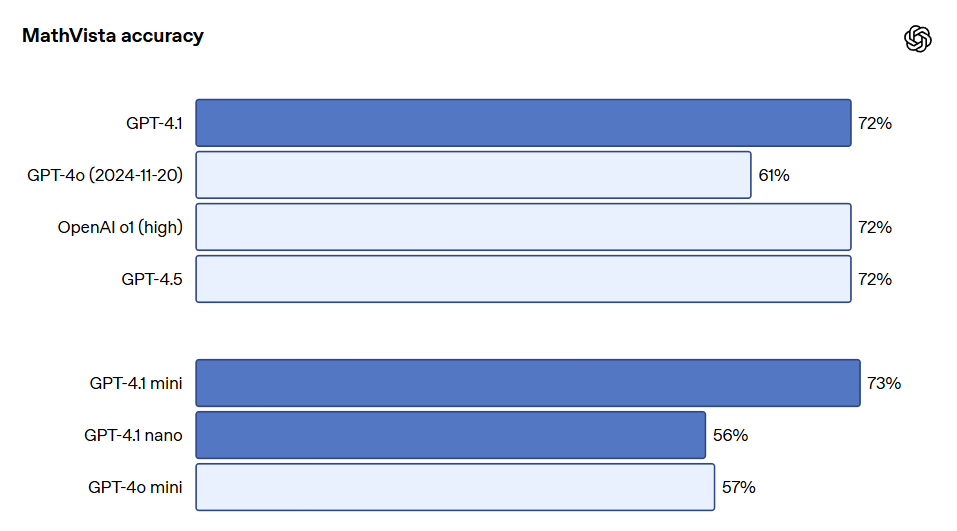
The GPT-4.1 series models are likewise powerful in image comprehension, particularly with significant advancements made in GPT-4.1 mini, which often outperforms GPT-4o in image benchmarking. The following are performance comparisons on benchmarks such as MMMU (answering questions that include charts, diagrams, maps, etc.), MathVista (solving visual mathematics problems), and CharXiv-Reasoning (answering questions about charts in scientific papers). 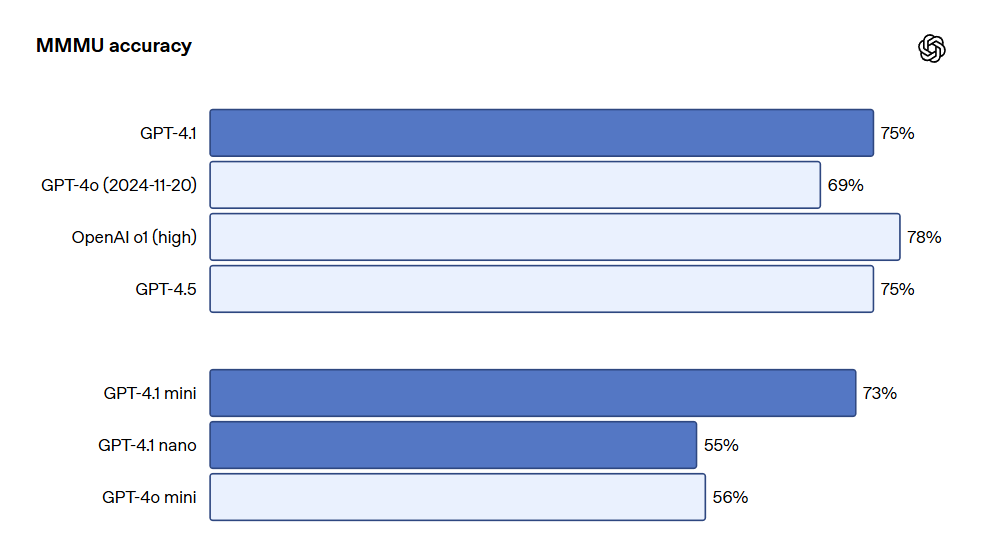
The long-context performance is also essential for multimodal use cases, such as processing long videos. In Video-MME (long video without subtitles), the model answers multiple-choice questions based on 30-60 minute-long unscripted videos. GPT-4.1 achieved optimal performance with a score of 72.0%, higher than GPT-4o's score of 65.3%. 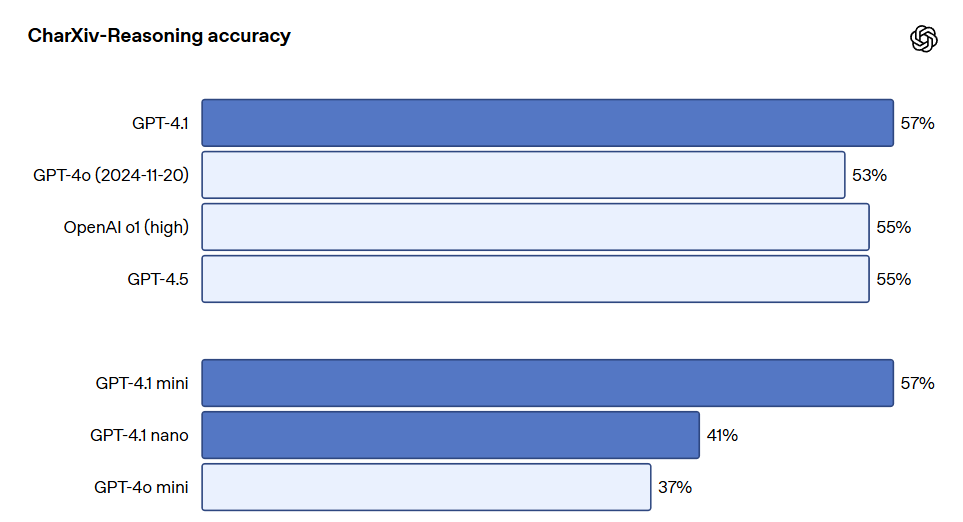
For more testing metrics, please refer to the original OpenAI blog. The blog address: https://openai.com/index/gpt-4-1/ © THE END
Our awesome Reviews

Unleashing Creativity with FLUX Kontext: The Best AI Image Generator for Seamless Edits
This article explores FLUX Kontext, an advanced generative model for AI image editing that retains the integrity of unedited areas while allowing detailed modifications.

Introducing FLUX.1 Kontext: The Best AI Image Generator for Image Creation and Editing
FLUX.1 Kontext model by Black Forest Labs revolutionizes AI image generation and editing with its innovative contextual capabilities.

Best AI Image Generator: Exploring the Power of Qwen3
This article delves into the capabilities of Qwen3, an AI image generation model that offers impressive performance across several configurations.

Discover the Best AI Image Generator: HiDream's Advancements in Image Creation
HiDream's innovative AI image generation models, HiDream-I1 and HiDream-E1, are capturing global interest with their advanced features and capabilities.

Introducing Vidu Q1: The Best AI Image Generator for Stunning Videos
Vidu Q1 is a revolutionary AI model that generates high-quality 1080P videos from text or images, enhancing content creation with smart audio effects.

Best AI Image Generator: Create Stunning Images with GPT-4o
A guide on using GPT-4o to create realistic images with simple prompts, showcasing the ease of AI-driven art generation.

Discover the Best AI Image Generator: Create Stunning Ghibli Style Art with Liblib AI
Explore how to effortlessly create enchanting Ghibli-style AI-generated images using Liblib AI and DeepSeek.

Unlocking Creativity with the Best AI Image Generator: A Look at Free Tools
An insightful review of two free AI image generation tools that offer high quality at no cost.

Introducing the Best AI Image Generator: CatPony - A Stunning Realistic Model
Explore the outstanding CatPony model featuring stunning realism and intricate details, perfect for AI image generation.

Discover the Best AI Image Generator: Create Adorable GPT-4o Figures with Ease
This article introduces two platforms to generate adorable GPT-4o figurines. Follow the easy steps for creating unique custom designs.

Introducing the Best AI Image Generator: FLUX Model's Breakthrough Enhancements
This article reviews the FLUX model and its integration with the nunchaku engine, highlighting its improvements in image generation speed and quality.

Introducing GPT-4.1: The Best AI Image Generator with Enhanced Performance
OpenAI's new GPT-4.1 models offer significant advancements in coding, instruction adherence, and long context processing.

Revolutionizing Photo Editing: Best AI Image Generator - AIEASE Transforms Your Photos in 3 Seconds!
Explore how AIEASE, the revolutionary AI photo editing tool, is transforming photo processing with its impressive features.

Discover the Best AI Image Generator: Unique Animal-Human Hybrid Art
Explore a special big model combining animals and humans, revealing absurdity in reality through a variety of artistic styles.