 Qwen3於4月29日凌晨發布。千問這次開源了8款不同參數的模型,每一款均斬獲同尺寸開源模型SOTA(最佳性能)。強到什麼程度?即使是4B參數的小模型,也能匹敵千問上一代72B模型的性能!這就意味著,高質量模型的私有化部署,終於面向普通消費級顯卡敞開大門。很多玩法,都可以跑起來了。本地化部署也不難。本文介紹2種方法,不用懂代碼,不複雜,算是抛磚引玉:
Qwen3於4月29日凌晨發布。千問這次開源了8款不同參數的模型,每一款均斬獲同尺寸開源模型SOTA(最佳性能)。強到什麼程度?即使是4B參數的小模型,也能匹敵千問上一代72B模型的性能!這就意味著,高質量模型的私有化部署,終於面向普通消費級顯卡敞開大門。很多玩法,都可以跑起來了。本地化部署也不難。本文介紹2種方法,不用懂代碼,不複雜,算是抛磚引玉:
第一種:Ollama
- 下載安裝Ollama:地址 ollama.com,根據自己的系統版本下載即可,和安裝普通軟件一樣。
- 下載模型:安裝好後訪問上面網址,在界面菜單欄點擊“Models”標籤,找到“qwen3”進入詳情頁,選擇適合自己電腦條件的版本。我是30系列N卡,選了個8b的(後文附14b版本的測試)。
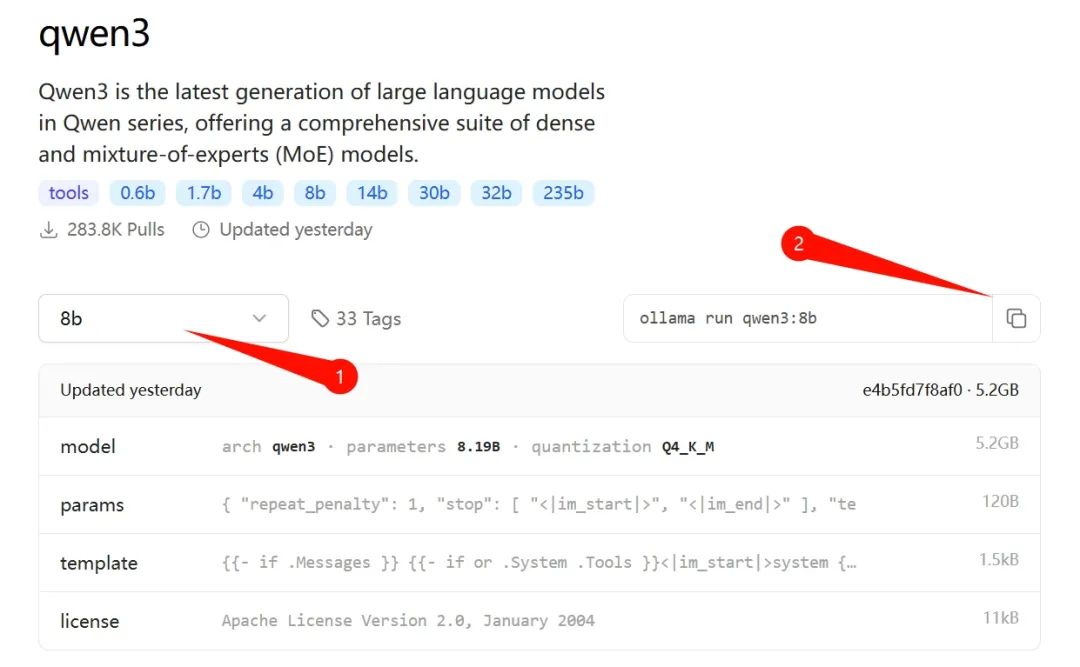
在上圖標識②的地方複製命令後,用“Win + R”打開CMD命令提示符界面,粘貼該命令,回車即可自動下載該版本的模型。

8b版大概5個G左右,加上Ollama本身,大概10G。默認放在C盤,記得留下足夠的空間。
3. 開始對話:下載完畢後自動運行,可直接提問對話,如圖:
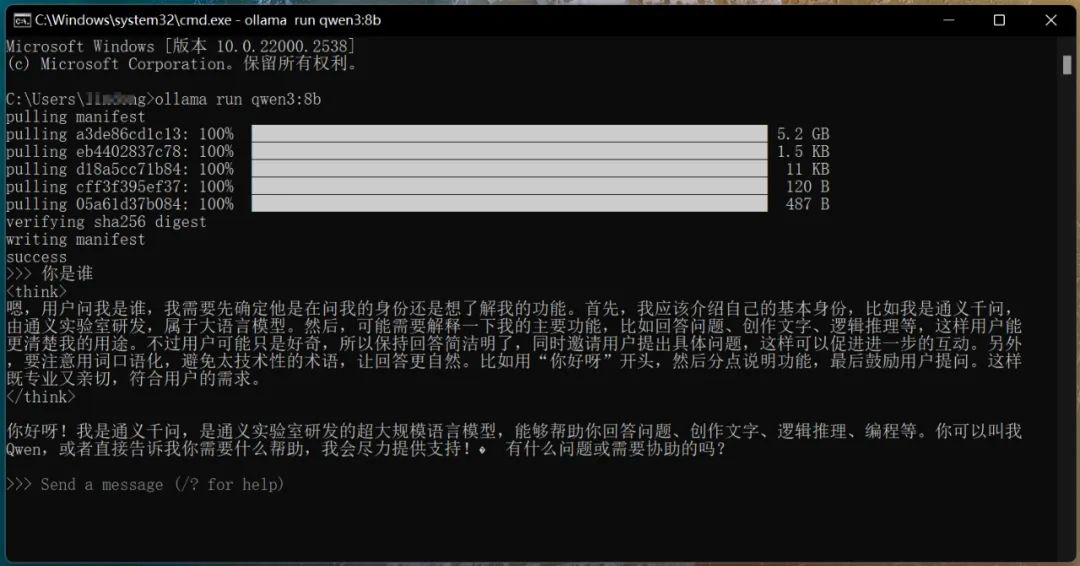
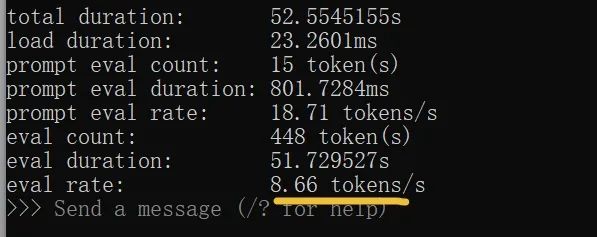
需要提醒一下的是,關閉CMD界面後,如再運行qwen3,需要在CMD命令行中輸入命令:ollama run qwen3。從上圖可看出,雖然是8b模型,但仍具備深度思考能力。原本以為我的30系列顯卡帶不動它,沒想到輸出速度可達到58.96 tokens/s。看這數字可能沒啥感覺,總之是普通人打字速度15倍左右,堪稱飛速。
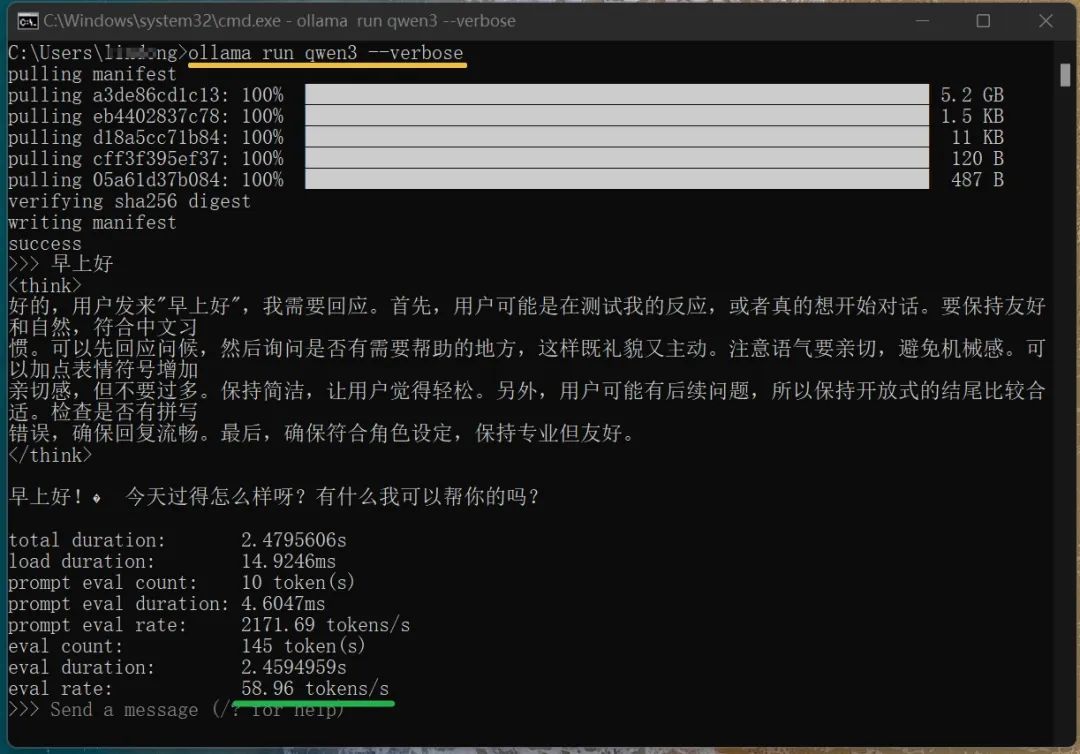
(輸入ollama run qwen3 --verbose 命令對話可查看本地模型運行速度,如上圖)到這裡,你已經完成qwen3模型的本地離線運行。不過,這種命令行的交互方式,感覺還不夠方便。如果能用可視化工具來運行就更好了,就像我們平時跟DeepSeek對話一樣,有清晰的對話窗口。這種工具很多,個人嘗試了一下Ollama Open WebUI,感覺不錯。安裝方法如下:
第二種:Open WebUI
前面已安裝了Ollama,只需再做兩步:
一是安裝Docker
二是安裝Ollama WebUI
-
Docker安裝:訪問 https://www.docker.com/,根據自己的電腦情況下載,沒有魔法上網的話,慢。我下載的是Windows AMD64版本(在本公眾號“對話框”發送docker可下載該版本)。基於x64架構的windows電腦,直接用這個版本即可,如是蘋果電腦請到官网下载。如何查看自己系統架構版本?按 “Win + R” 鍵,在 “運行” 對話框中輸入 “msinfo32” 並按下回車鍵,在 “系統摘要” 部分,看“系統類型”一項。下載後像普通軟件一樣安裝、運行。首次運行的時候可能有些慢。
-
安裝Ollama WebUI:先進入 https://github.com/open-webui/open-webui,找到下圖這個地方,先複製命令行(右下箭頭處)

然後用 win+R 打開CMD界面,粘貼上面的命令,回車,等待自動安裝完畢。最後,在瀏覽器地址欄訪問Ollama WebUI,地址 http://localhost:3000,如提示註冊,按提示進行即可(系統默認第一個賬號為管理員)。由於本文在安裝Ollama的時候已經下載了qwen3的8b模型,所以在界面左上選擇這個模型,即可直接輸入消息進行對話(下圖):
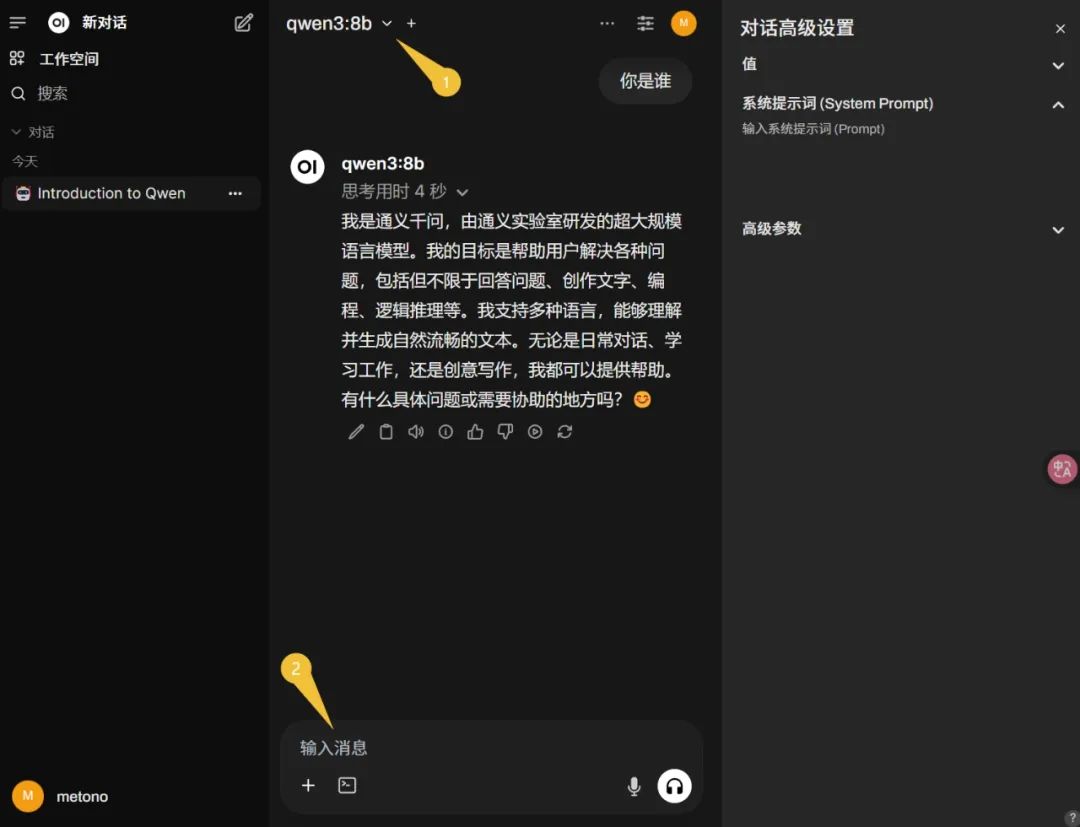
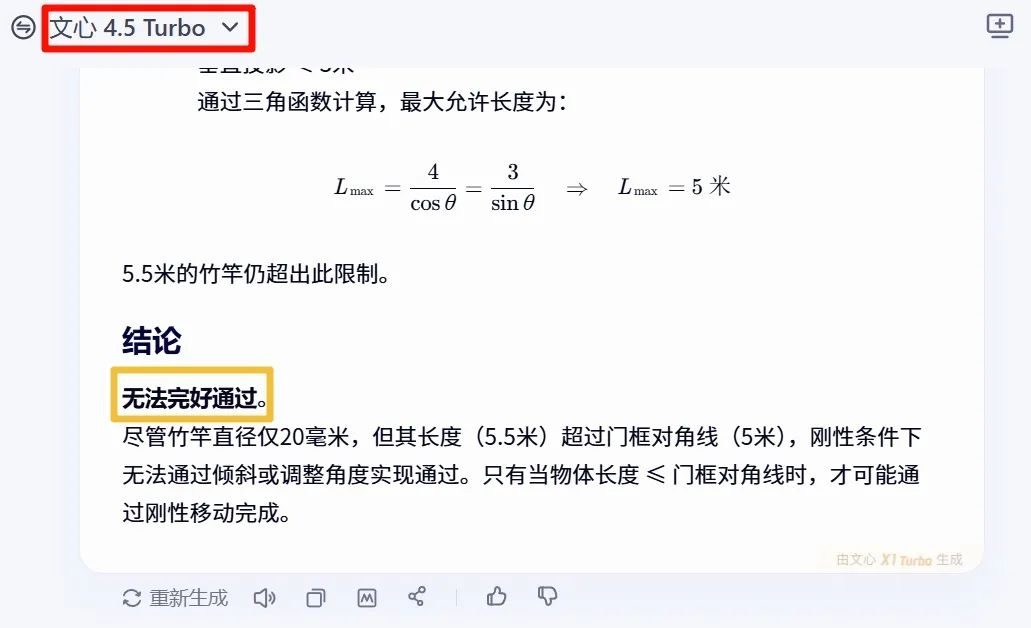
至此,第二種部署使用方案完成。看看Qwen3的質量效果如何,先考一下“智商”,提問:結合現實經驗,一根5.5米直徑20毫米的竹竿,能否完好通過寬4米高3米的矩形門?直接看結論即可。先看文心一言的回答(其答案是不能)
再看Kimi的回答(答案仍是不能):

然後看看qwen3 8b模型的回答:
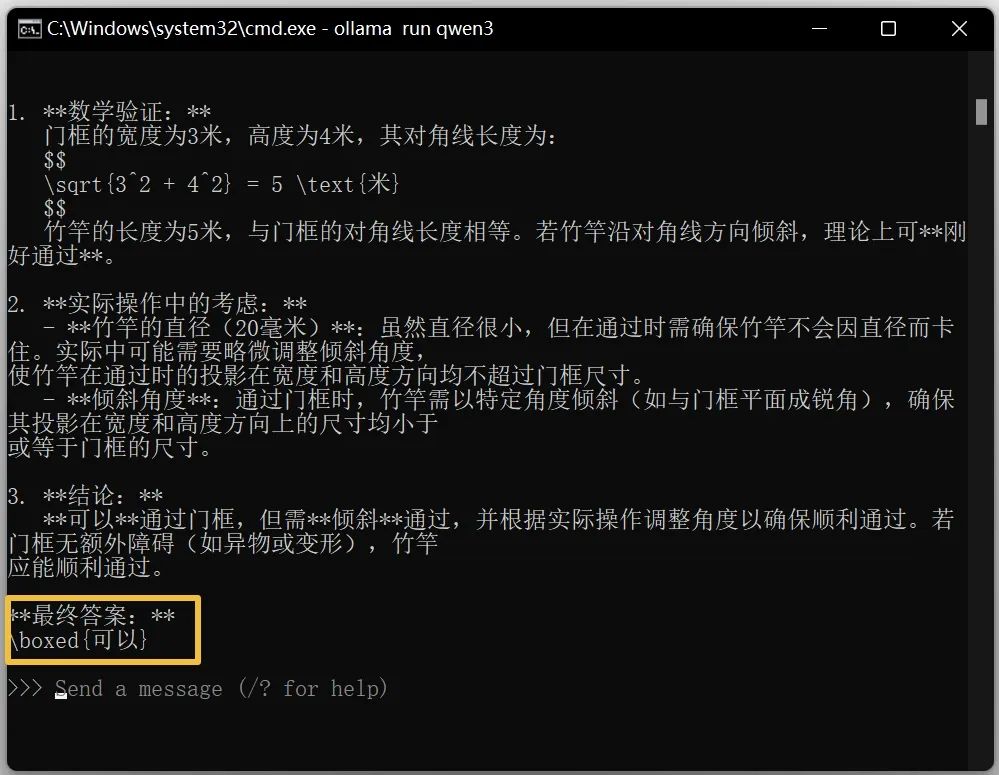
是不是很意外??測試完8b後,再看看14b參數的模型。沒想到8G的N卡也能驅動這個參數量級,有點驚喜!但輸出速度一般,大約為普通人打字速度的2倍:
看看古詩寫得怎麼樣
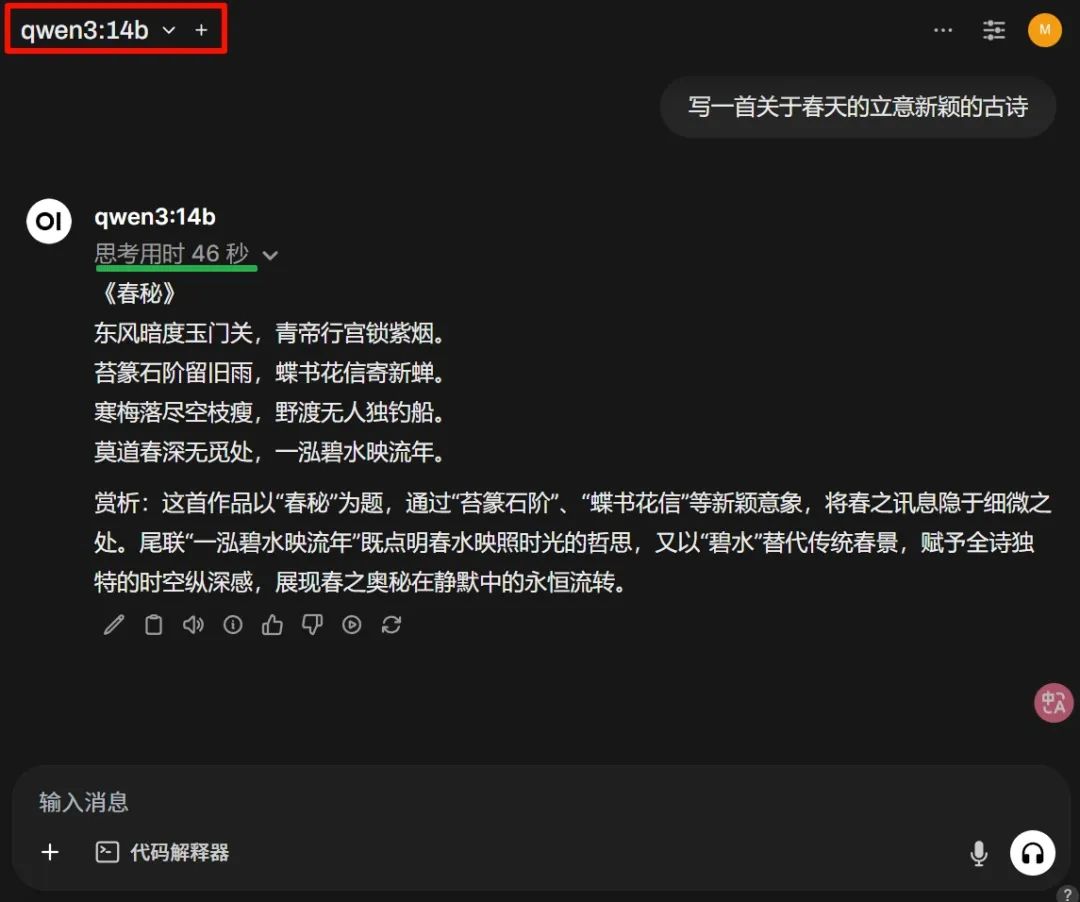
看上圖的思考耗時,完全可以接受。這是8G顯存的效率,還要啥自行車呢。当然,質量是關鍵。整體感覺,雖然本文測試的模型參數不大,但效果還是不錯,篇幅關係,沒有放更多案例。按這個趨勢,大部分的閉環大語言模型估計要被Qwen的開源幹翻。你說呢?如要體驗官方的滿血版,可訪問:chat.qwen.ai。
我們的精彩評測

最佳 AI 圖片生成器:FLUX Kontext 讓圖片編輯變得輕鬆
FLUX Kontext 是一款強大的生成式流匹配模型,能簡化圖片編輯流程,支持去水印、風格轉換等多種功能。

最佳AI圖片生成器:FLUX.1 Kontext模型的革新與應用
FLUX.1 Kontext模型的發布標誌著AI圖像生成和編輯的一次重要突破,具備上下文感知的圖像生成能力及多種創新功能。





最佳AI圖片生成器:探索免費的Raphael AI和商湯的秒畫
這篇文章介紹了兩款全年免費的AI畫圖工具:Raphael AI和商湯的秒畫,幫助用戶生成高品質的圖片,無需額外費用。




OpenAI 最新 GPT-4.1 系列模型发布:最佳 AI 图像生成器与编程性能
OpenAI 推出三款新模型 GPT-4.1 系列,性能超越前作,并在多项基准测试中表现优异。

