生數科技發表了其最新的AI視頻生成模型:Vidu Q1,可以根據文字描述或圖片,自動生成高品質、1080P 分辨率的視頻,還能同時添加智能生成的音效。Q1相比之前的Vidu 2.0版支持多種動畫風格、鏡頭轉場效果,甚至能模擬「電影級運鏡」可直接生成用於動漫、短劇、電商、品牌廣告的視頻內容。實現「即生成、即商用」。在多個行業權威評測中排名第一,最重要的是每秒視頻價格僅為0.3元,比行業平均價格低10倍。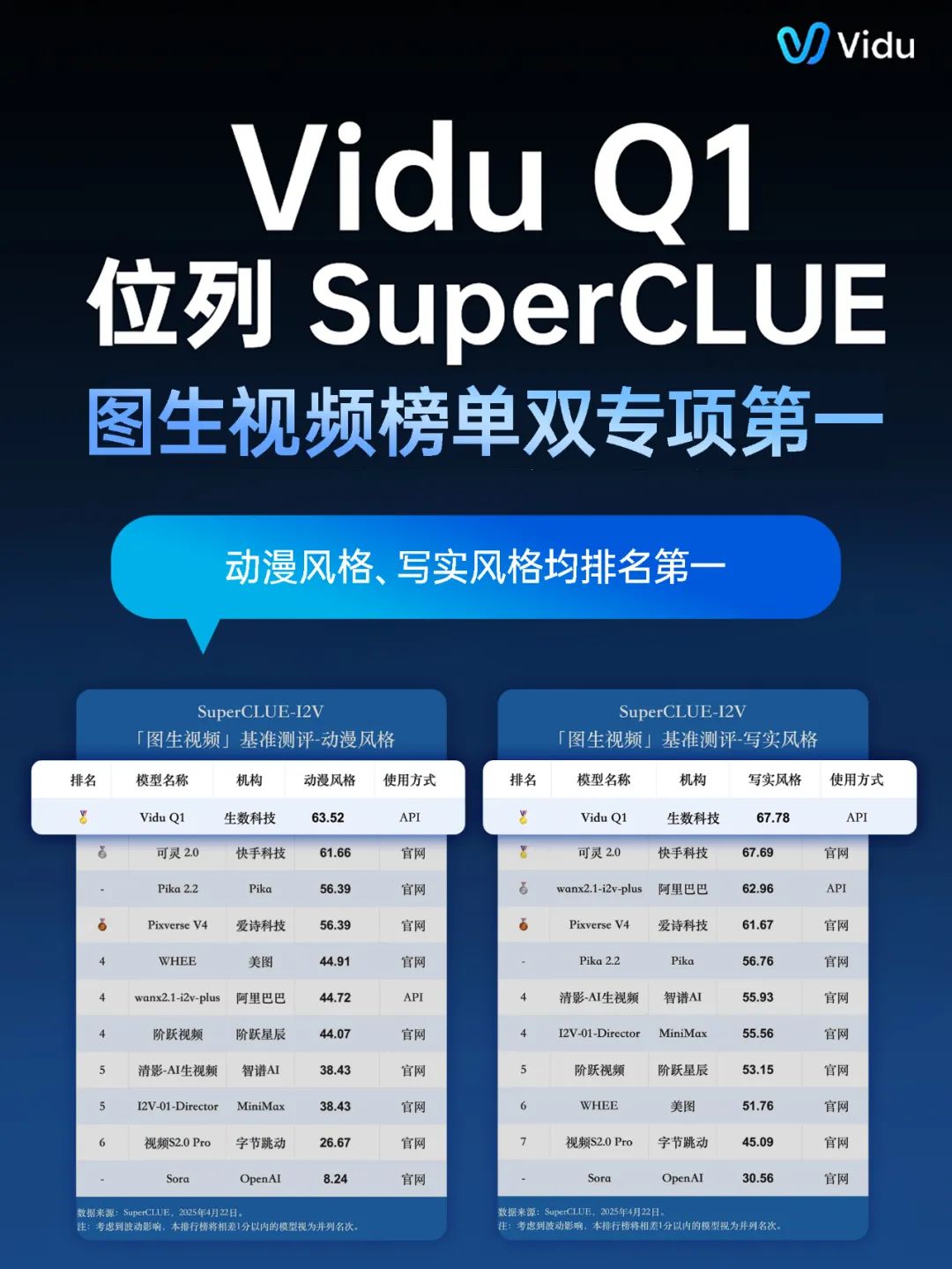
可謂是目前全球效果最強、性價比最高的視頻大模型之一。先看看效果↓主要功能特點:
電影級視覺效果:Vidu Q1 支持生成最長5秒的1080p高清视频,畫質清晰,細節豐富,達到電影級視覺效果。
U-ViT架構:其獨創的U-ViT(Universal Vision Transformer)架構,結合擴散模型和Transformer技術,確保視頻在時空一致性和動態性方面表現出色。
提示理解遵循更強:對提示詞的理解力很強,能自動識別人物動作、光影、位置關係等內容,實現更真實的視覺效果。
無縫轉場:兩張首尾幀圖即可生成自然流暢的場景轉場,首尾幀衔接技術實現電影感鏡頭語言,保持角色和場景的一致性。
多主體一致性:無縫整合多個主體、物體和環境,保持主體、場景、風格一致,特別優化動畫生成,支持多元動畫風格。
多角度與鏡頭控制:支持360度視角視頻生成,精確控制攝像機運動(如變焦、平移、傾斜),增強視覺連續性和敘事效果。
超性價比:每秒視頻價格僅為0.3元,比行業平均價格低10倍,適合商業化使用或高頻率內容創作。
專業音效生成:還支持生成48 kHz高品質背景音樂和音效,支持精準音效控制和多軌道音頻堆疊(最長10秒)。
那麼實際性能到底如何,下面我們進行一些評測,看看真實效果如何↓
01—主要性能評測視頻版簡要評測↓
圖文詳細評測↓
1、首尾幀無縫專場:兩張照片即可生成自然流暢的場景轉場,Q1新的首尾幀工具鏡頭衔接更絲滑、語義理解更準確,保持角色和場景更一致。例如下面這個,一張男孩打籃球的照片,然後進行一個專場,直接過渡到了他夢想實現進入NBA的場景。
還有這個,兩張圖像可以實現人物的變身效果。
申公豹變身!
如果你有耐心,可以連續地使用首尾幀功能實現下面這樣絲滑的效果。
2、電影級視覺效果:Vidu Q1 支持生成最長5秒的1080p高清视频,畫質清晰,細節豐富,達到電影級視覺效果(由於公眾號限制視頻數量,我上傳的是gif圖,對畫面有壓縮,不能反應真實視頻質量)。看看這個畫面,藝術效果直接拉滿的!
提示詞:camera zoom in, figures slowly rise up from the water
提示詞:鏡頭越過飄浮的餘燼向前推進,靠近人物的臉!
Vidu Q1 不僅能聽懂「人話」,連專業鏡頭語言也拿捏得死死的。比如下面的例子,焦點從近處的粉色西裝男子自然切換到他身後穿黑西裝的男子,整個變焦過程流暢自然。
Q1更懂鏡頭語言,在理解提示詞的語義和鏡頭邏輯方面大幅提升,極大降低了「抽不到理想鏡頭」的概率。例如下面視頻,提示詞中包含"男子"、"行人"、"汽車"、"街道"等多個元素,且有複雜的位置關係和光線描述,Q1 不僅精准理解了這些關係,還鏡頭感十足,宛如好萊塢導演的實拍作品。提示詞:鏡頭聚焦於一位身穿皮夾克的男子,他獨自行走在白天的城市街道上。陽光在人行道上投射出逼真的陰影,背景中是汽車和行人,而模糊的畫面則以電影般的照片寫實風格呈現。
3、動漫效果拉滿:Q1相比Vidu 2.0又有了大幅提升,支持更加多元風格的視頻輸出,尤其在動畫風格表現上。先看一個展示↓下面是我的測試:復刻日本動漫《你的名字》經典畫面。
復刻日本動漫《火影忍者》。
此外,在動畫風格表現力上,Q1的人物表現更加生動,高動態表現較為驚艷。比如下面視頻,Vidu Q1不僅很好理解了3D動漫風,而且鏡頭運動能很好體現小狗降落的急速感,以及隨著降落不斷變化的田園景色,非常逼真。
最後看看幾個海外博主做的動漫效果↓
日本博主 @neru_pipipi 日本博主 @Sabitamago 日本博主 @yachimat_manga
02—和其他模型對比動態運鏡能力從眼部特寫到背影俯視,全程運動流暢、語義連貫。即使在宏大的奇幻場景,Vidu Q1的表現也可圈可點。如下面的案例,一隻恐龍在城堡上空快速飛翔,可以看到Runway Gen-4生成的視頻存在崩壞,Veo 2中的恐龍飛翔動作不是很自然,而Vidu Q1不僅運動自然,而且整體鏡頭運動的幅度大且合理。
Runway Gen-4 
Veo 2 
Vidu Q1 
動態運鏡能力:Vidu Q1在畫面逼真度和細節豐富度上優勢更加明顯。如下面的例子,Runway Gen-4中女生運動非常不自然,Veo 2視頻中的女生幾乎沒有運動,相對而言,Vidu不僅很好地理解了運鏡,還能看到卡車里冒出的火光和黑煙,畫面細節非常到位。提示詞:綠色頭髮的女生,走過擁擠車流和人群,遠處的卡車冒出火光和黑煙,鏡頭推進拍攝,定格在女生的臉上。
Runway Gen-4 
Veo 2 
Vidu Q1 
Vidu Q1支持360度視角視頻生成,精確控制攝像機運動(如變焦、平移、傾斜),增強視覺連續性和敘事效果。對提示詞的理解力也很強,能自動識別人物動作、光影、位置關係等內容,實現更真實的視覺效果。即使是大幅度運動,Vidu Q1也能很好遵從,AI視頻生成常見的崩壞程度大幅降低。提示詞:富士膠卷Portra 400H靜態照片,急馳的日产天際線R33 GTR LM JGTC,大幅度運動效果,東京7-11便利店,午夜時分。
動漫多元風格:Vidu Q1更能理解多元動畫風格,且在動畫風格一致性上保持較好。比如我們讓各家生成80、90年代復古風格的可愛動漫女孩。Veo則直接生成了3D風格,Runway Gen-3 Alpha雖然理解了復古動漫風,但畫面比較生硬、呆板,而Vidu Q1對於80、90年代復古風格理解精準,女孩的表情動作也非常自然。
Runway-Gen3 Alpha 
Veo 2 
Vidu Q1 
03—教程+特別玩法:下面我來通過一個簡單的教程,教大家如何利用Vidu Q1的首尾幀實現一些特殊的效果,讓你能玩出花。首先是登錄vidu.cn,選擇圖生視頻。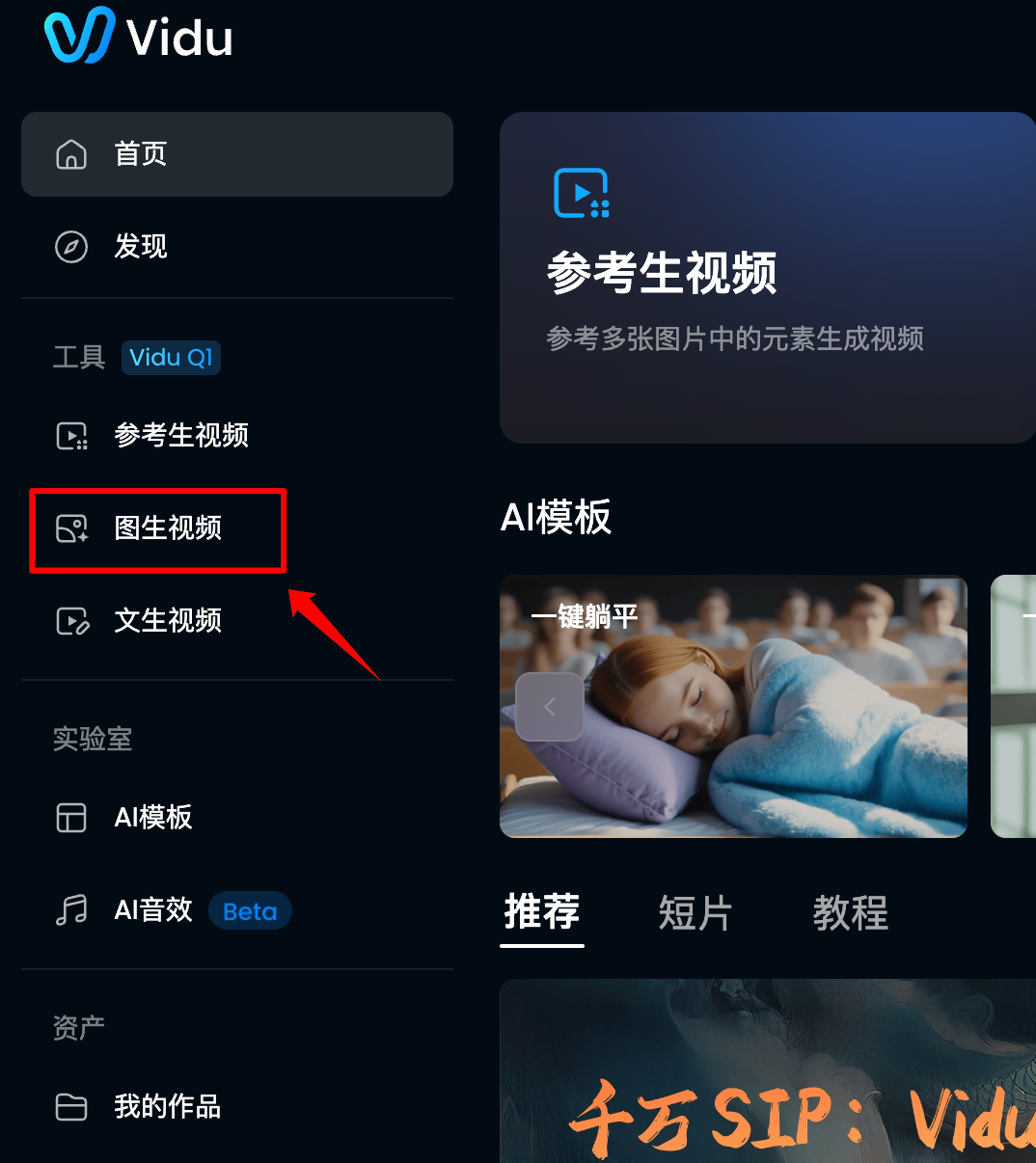
然後是在模型下拉中,選擇Vidu Q1模型。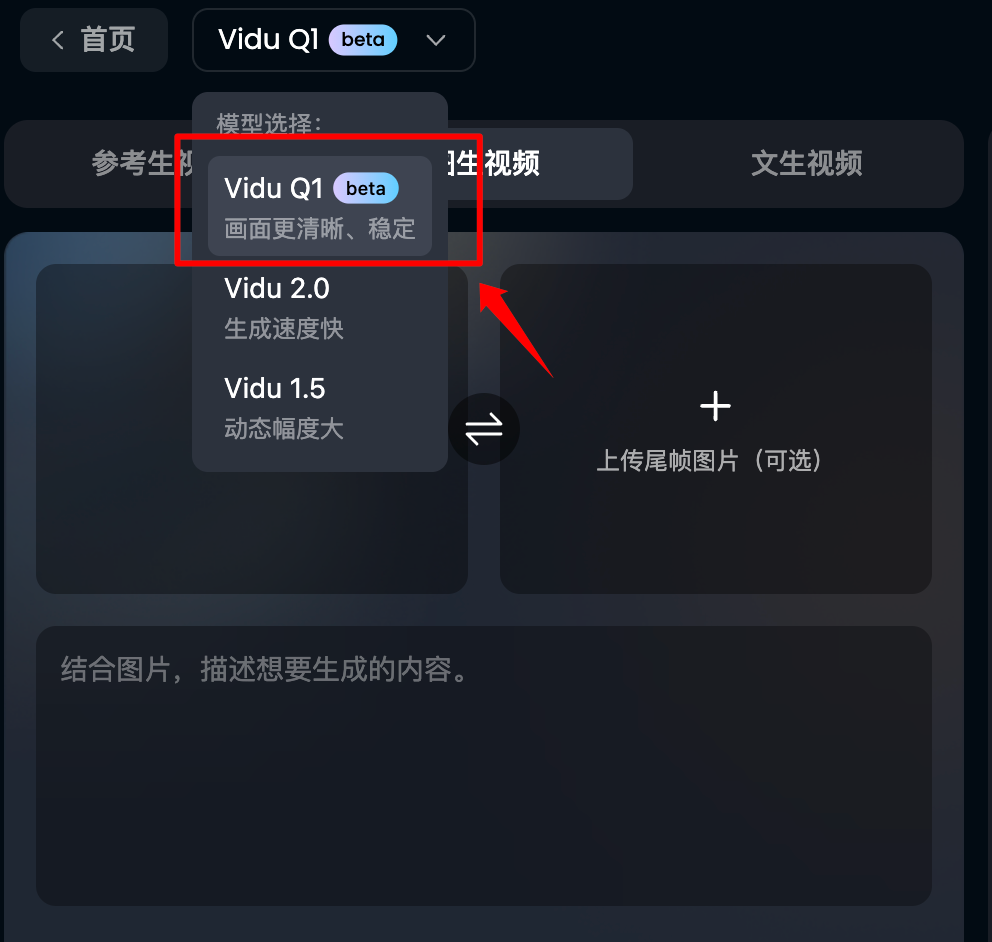
選擇圖生視頻,上傳兩張首尾幀照片,首幀就是你畫面起始的狀態,尾幀就是你最終想實現的效果,中間的過渡我們用提示詞來控制。
下面進入實戰教學...
步驟一:拍攝或者上傳一張起始照片,然後選取想要實現的特殊效果照片作為尾幀(如果是特殊效果的可以直接讓GPT 4o或者其他圖像工具生成)。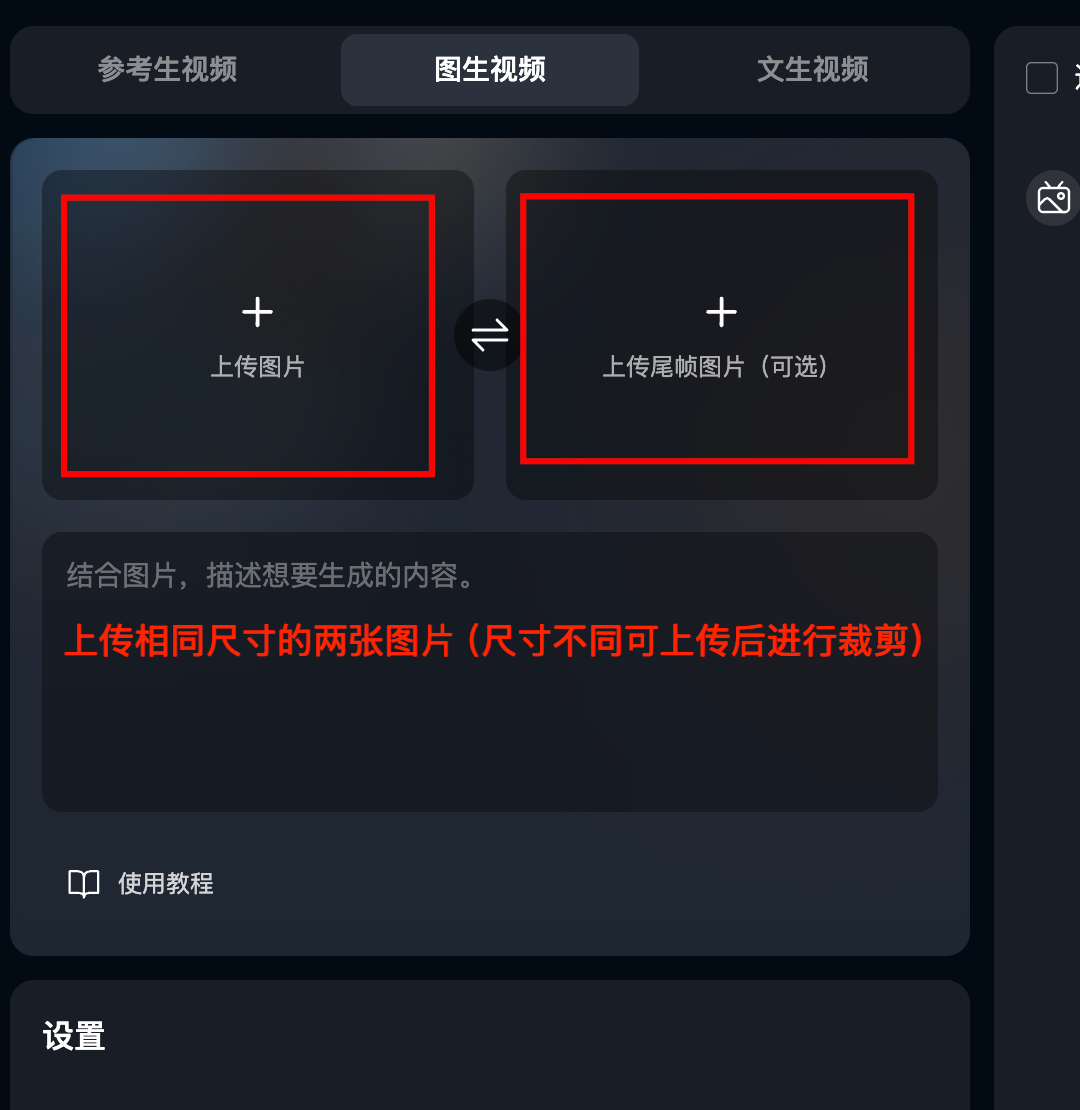
步驟二:輸入提示詞,提示詞不會的也可以問GPT 4o和Deepseek等。
步驟三:設置一些參數,可以設置一些運動幅度大小,一次生成多個抽卡,選一個好的。(這步可以忽略,普通用戶默認即可。)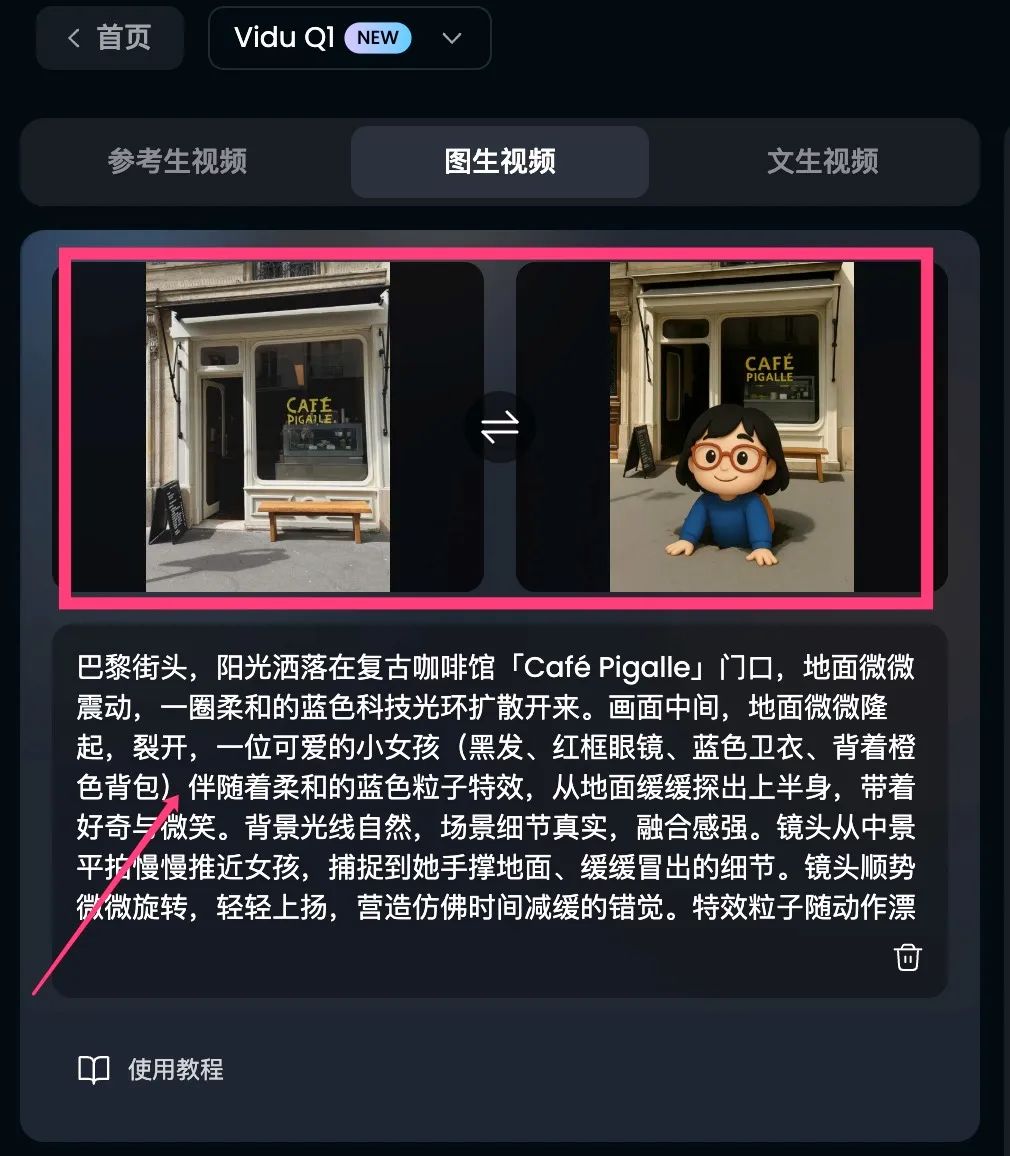
然後點擊生成,等待時間即可...
我們換個照片再試試其他效果↓
提示詞:在陽光灑落的巴黎街頭,一家名為「CAFE PIGALLE」的小咖啡館映入眼簾。畫面前景中,一位未來感十足的小女孩糖果角色通過一個微微漣漪閃爍的能量傳送門登場。她帶著紅色眼鏡,手持咖啡杯,背著橙色背包,但整體呈現出半透明的全息質感,輪廓帶有微微的霓虹藍光,表面隱約閃爍著細緻的電路紋理,充滿柔和的科幻氛圍。女孩周圍漂浮著虛擬的UI界面,慢慢旋轉,顯示出俏皮的數據流和圖標。再試試一個高級選項,高難度動作,運動幅度和鏡頭旋轉的。
提示詞:鏡頭從昏暗車站敞開的地鐵門緩緩前移。畫面無縫過渡到一個從內部視角看去,被霓虹綠能量束環繞的發光黑洞。鏡頭繼續後拉穿過黑洞,進入一個廣闊的未來主義數字世界,其中充滿了閃爍的數據流和網格圖案。流暢無縫的運動,賽博朋克美學,深綠和黑色的色調,電影般的光影,柔和的運動模糊。
04 總結:整體來看,Vidu Q1在高質、首尾幀及動漫風格的表現上非常不錯。Q1顯著提升了視頻質量,提供了更清晰、更穩定的視頻效果。尤其是動漫方面,支持實現誇張但自然的肢體表現(日漫的「動態透視」特徵),重點聚焦於戰鬥、運動、誇張情緒等高表現力畫面,具體如拳頭朝向屏幕的衝擊力、角色情緒爆發等。不過和其他模型一樣,還是需要依賴大量的抽卡,但相比上一代抽卡成功率高了不少。最重要的是Q1價格非常的香,每秒生成價格最低僅需0.3元,比同行低了近10倍,抽卡也不心疼了,可謂真正的「性價比之王」。
另外Vidu還推出了錯峰生成模式,享受非高峰時段的免費視頻生成。啟用後,在服務器高峰時段提交的任務將在需求減少時自動處理。如果服務器已經處於非高峰狀態,視頻將立即生成,並且0積分消耗,可以免費薅羊毛。此次Vidu還發佈了一句話生成專屬音效功能,只需一句話,即可生成最長10秒的專屬音效,AI視頻從此進入「有聲時代」。用戶可以精準控制生成音效的時間,音效可以在10秒內的任意時間點開始生成。這也是目前為止業內商業領域首個支持精細化時間控制的文生音效系統。其次,Vidu的文生音效功能還支持多段音效疊加,並以一個完整的音頻文件輸出。例如,下面的示例中,通過多段音效的疊加,成功還原了火車經過的真實感。亦或者來一段中國風純音樂,古箏、笛子等樂器營造出了古典的山水意境。可以直接給生成的AI視頻進行配音配樂,很方便,讓AI視頻告別無聲時代。
我們的精彩評測

最佳 AI 圖片生成器:FLUX Kontext 讓圖片編輯變得輕鬆
FLUX Kontext 是一款強大的生成式流匹配模型,能簡化圖片編輯流程,支持去水印、風格轉換等多種功能。

最佳AI圖片生成器:FLUX.1 Kontext模型的革新與應用
FLUX.1 Kontext模型的發布標誌著AI圖像生成和編輯的一次重要突破,具備上下文感知的圖像生成能力及多種創新功能。





最佳AI圖片生成器:探索免費的Raphael AI和商湯的秒畫
這篇文章介紹了兩款全年免費的AI畫圖工具:Raphael AI和商湯的秒畫,幫助用戶生成高品質的圖片,無需額外費用。




OpenAI 最新 GPT-4.1 系列模型发布:最佳 AI 图像生成器与编程性能
OpenAI 推出三款新模型 GPT-4.1 系列,性能超越前作,并在多项基准测试中表现优异。

