 Qwen3는 4월 29일 오전에 출시되었습니다. 이번에 Qwen은 8개의 다양한 파라미터 모델을 오픈소스로 공개하였으며, 각각은 같은 크기의 오픈소스 모델 SOTA(최고 성능)를 기록했습니다. 얼마나 강력하냐고요? 4B 파라미터의 소형 모델조차도 Qwen의 이전 세대 72B 모델의 성능에 필적합니다! 이것은 고품질 모델의 개인화된 배포가 드디어 일반 소비자용 그래픽 카드에서도 가능하게 되었음을 의미합니다. 많은 응용 프로그램이 이제 실행될 수 있게 되었습니다. 로컬에서의 배포도 어렵지 않습니다. 본문에서는 두 가지 방법을 소개합니다. 코드에 대한 지식이 필요 없으며, 복잡하지 않습니다. 첫 번째 방법은 다음과 같습니다:
Qwen3는 4월 29일 오전에 출시되었습니다. 이번에 Qwen은 8개의 다양한 파라미터 모델을 오픈소스로 공개하였으며, 각각은 같은 크기의 오픈소스 모델 SOTA(최고 성능)를 기록했습니다. 얼마나 강력하냐고요? 4B 파라미터의 소형 모델조차도 Qwen의 이전 세대 72B 모델의 성능에 필적합니다! 이것은 고품질 모델의 개인화된 배포가 드디어 일반 소비자용 그래픽 카드에서도 가능하게 되었음을 의미합니다. 많은 응용 프로그램이 이제 실행될 수 있게 되었습니다. 로컬에서의 배포도 어렵지 않습니다. 본문에서는 두 가지 방법을 소개합니다. 코드에 대한 지식이 필요 없으며, 복잡하지 않습니다. 첫 번째 방법은 다음과 같습니다:
- Ollama 설치
- Ollama를 다운로드하고 설치합니다: 주소는 ollama.com입니다. 본인 시스템의 버전에 맞는 파일을 다운로드하면 되며, 일반 소프트웨어를 설치하는 것과 같습니다.
- 모델 다운로드
- 설치가 완료되면 위의 URL을 방문해 메뉴에서 "Models" 탭을 클릭하여 "qwen3"의 상세 페이지로 들어가고, 본인 컴퓨터에 맞는 버전을 선택합니다. 저는 30 시리즈 N카드를 사용하기 때문에 8b 버전을 선택했습니다. (후속 글에서는 14b 버전도 테스트할 예정입니다.)
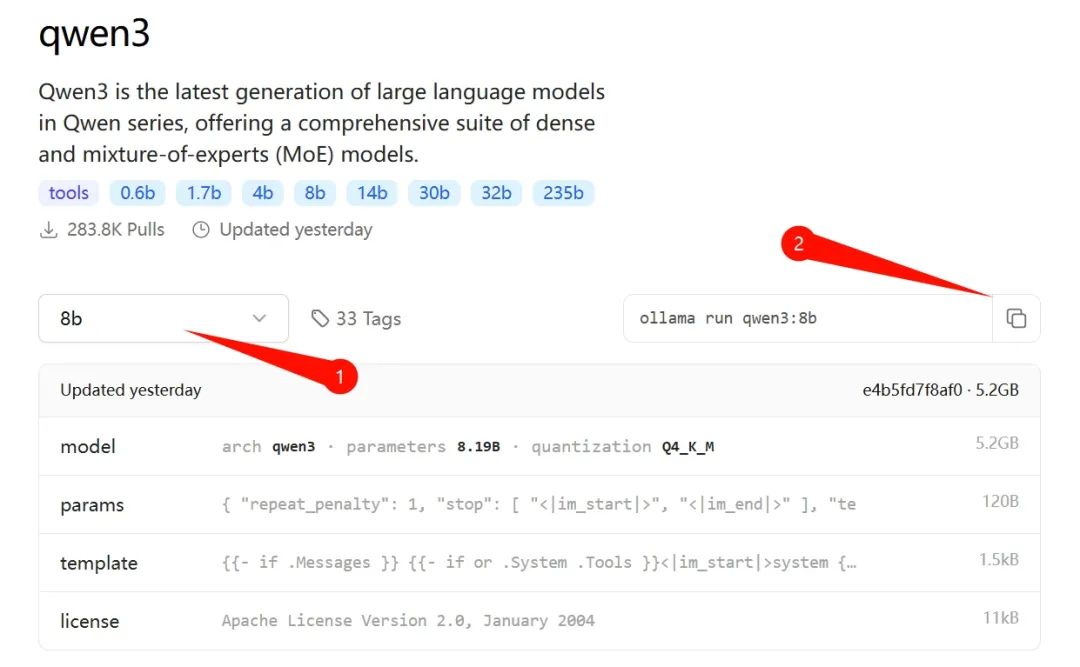
위 그림의 ② 위치에서 명령어를 복사한 후, "Win + R"로 CMD 명령 프롬프트를 열고 붙여넣기 한 다음 엔터를 치면 자동으로 이 버전의 모델이 다운로드됩니다.

8b 버전은 약 5GB 정도 되고, Ollama 본체와 합치면 약 10GB입니다. 기본적으로 C 드라이브에 설치되므로 충분한 공간을 남겨두는 것이 좋습니다.
- 대화 시작
- 다운로드가 완료된 후 자동으로 실행되며, 직접 질문을 통해 대화할 수 있습니다, 아래 그림과 같이:
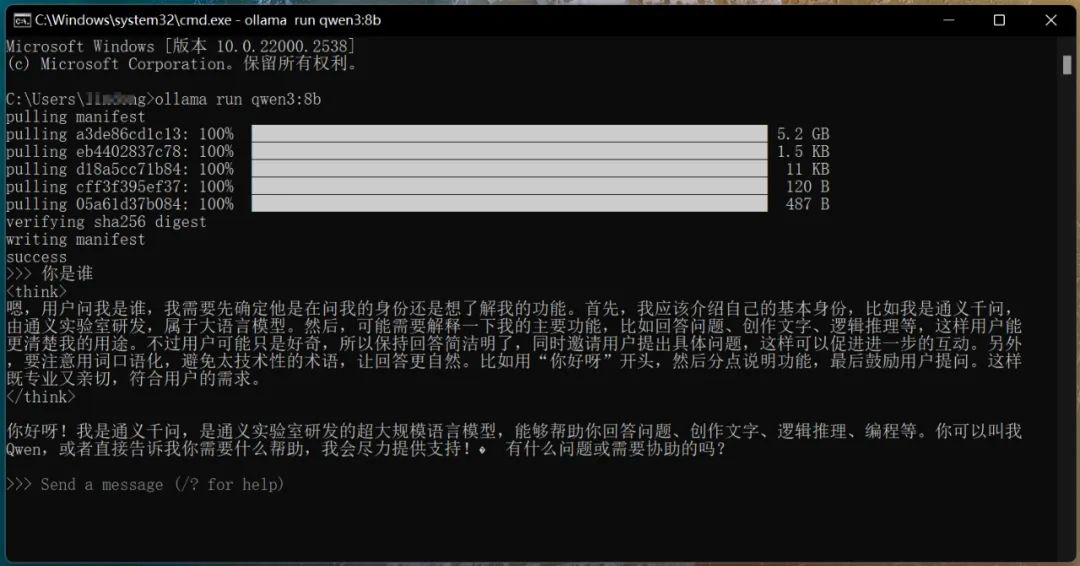
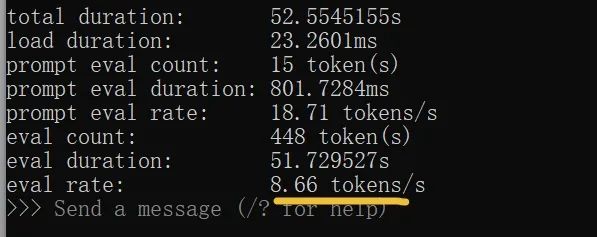
여기서 주의할 점은 CMD 창을 닫은 후 다시 qwen3을 실행하려면 CMD 명령줄에서 다음 명령어를 입력해야 한다는 점입니다: ollama run qwen3. 위 그림에서 볼 수 있듯이, 8b 모델임에도 불구하고 깊은 사고 능력을 갖추고 있습니다. 원래 제 30 시리즈 그래픽 카드로는 힘들 것 같았지만, 출력 속도는 58.96 tokens/s로 달할 수 있었습니다. 이 숫자를 보고 감을 잡기 힘들 수도 있지만, 일반인의 타자 속도의 약 15배 정도로 어마어마한 속도입니다.
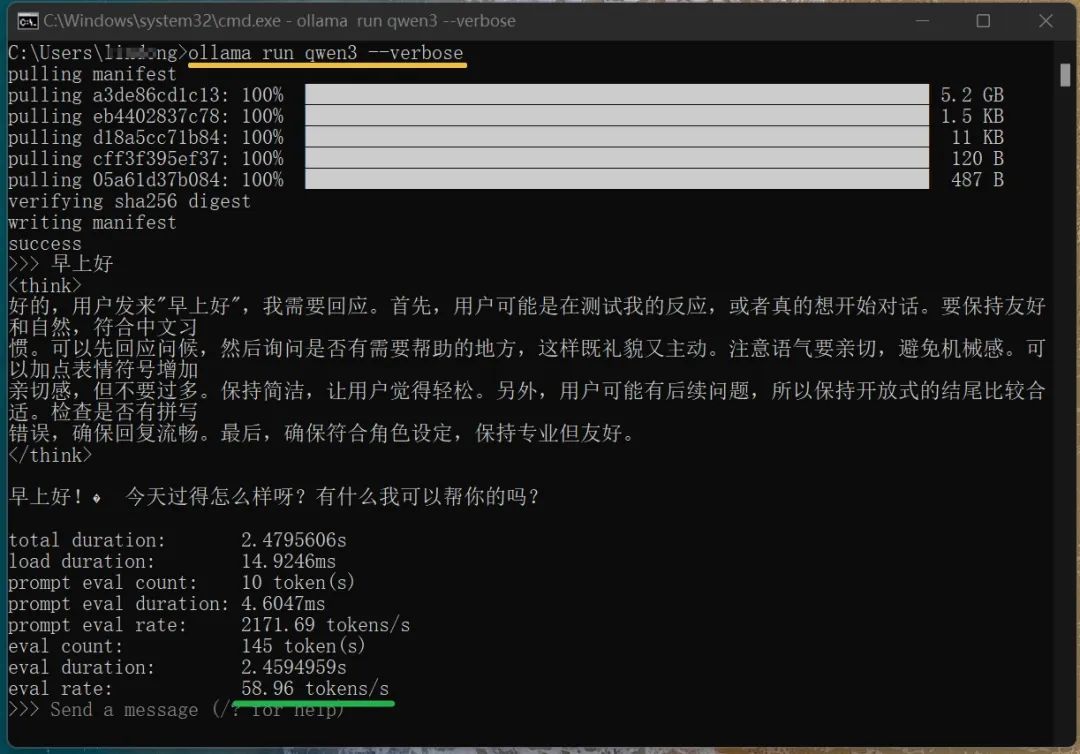
(명령어 ollama run qwen3 --verbose를 입력하여 로컬 모델의 실행 속도를 볼 수 있습니다, 위 그림 참고) 여기까지 오셨다면, 이미 qwen3 모델을 로컬 오프라인으로 실행하는 데 성공한 것입니다. 하지만 이러한 명령줄 방식의 상호작용은 여전히 불편한 느낌이 있습니다. 시각화 도구를 사용해 실행할 수 있다면 더욱 좋을 것입니다. 평소 DeepSeek와 대화하듯이 명확한 대화 창을 갖춘다면 좋겠습니다. 이런 도구는 많습니다. 개인적으로 Ollama Open WebUI를 시도해봤는데, 괜찮은 느낌이었습니다. 설치 방법은 다음과 같습니다:
두 번째 방법: Open WebUI 앞서 Ollama를 설치했으므로, 다음 두 단계를 수행하면 됩니다:
- Docker 설치
- https://www.docker.com/에 방문하여 본인의 컴퓨터 환경에 맞는 버전을 다운로드합니다. 마법의 인터넷이 없을 경우 다운로드 속도가 느릴 수 있습니다. 저는 Windows AMD64 버전을 다운로드했습니다 (이 본 글의 '대화 상자'에서 docker를 보내면 해당 버전을 다운로드할 수 있습니다). x64 아키텍처를 기반으로 한 Windows 컴퓨터에서는 이 버전을 바로 사용하면 됩니다. 애플 컴퓨터의 경우 공식 웹사이트에서 다운로드해야 합니다. 시스템 아키텍처 버전을 확인하려면 "Win + R"을 눌러 "실행" 대화 상자에 "msinfo32"를 입력하고 엔터를 누르면 "시스템 요약"에서 "시스템 타입" 항목을 확인할 수 있습니다. 다운로드 후 일반 소프트웨어와 같게 설치하고 실행합니다. 처음 실행할 때는 다소 느릴 수 있습니다.
- Ollama WebUI 설치
- 먼저 https://github.com/open-webui/open-webui에 접속합니다. 아래의 이미지와 같은 곳에서 명령어를 복사합니다 (오른쪽 아래 화살표 위치).

그런 다음, win+R로 CMD를 열고 위의 명령어를 붙여넣고 엔터를 누르면 자동으로 설치됩니다. 마지막으로 브라우저 주소창에 Ollama WebUI의 주소인 http://localhost:3000을 입력하여 접속합니다. 등록을 요구하는 경우, 안내에 따라 진행하십시오 (시스템 기본 첫 번째 계정은 관리자입니다). 본 기사에서는 Ollama 설치 시 이미 qwen3의 8b 모델을 다운로드했으므로, 왼쪽 상단에서 해당 모델을 선택하고 메시지를 입력하여 대화할 수 있습니다 (아래 이미지 참조):
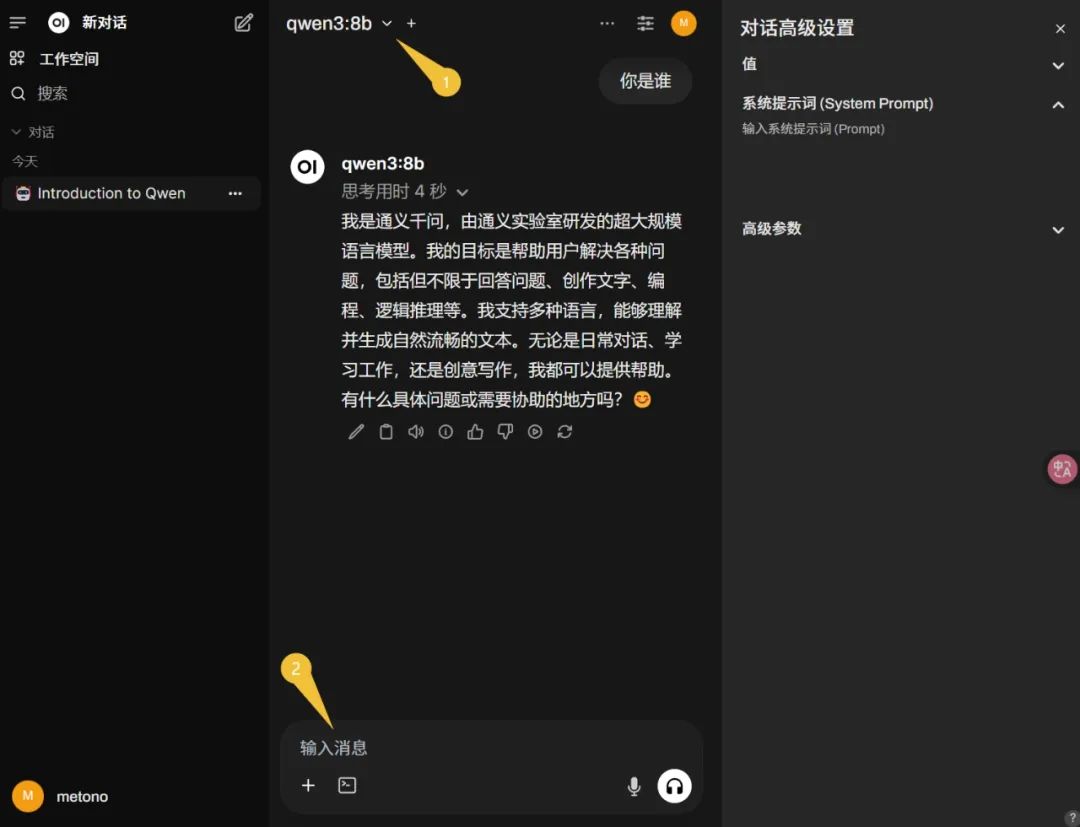
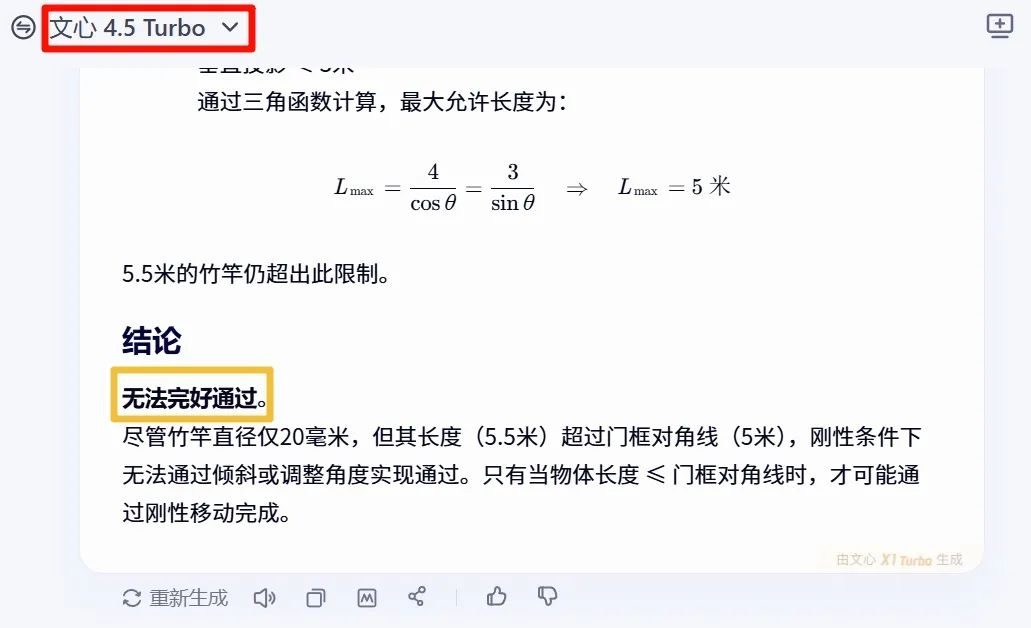
여기까지 두 번째 배포 사용 방법이 완료되었습니다. Qwen3의 품질 효과는 어떤지 확인해보겠습니다. 먼저 "지능"을 시험해보며 질문을 던집니다: "실제 경험에 비추어 5.5미터의 직경 20mm 대나무 막대가 너비 4미터, 높이 3미터의 직사각형 문을 통과할 수 있는가?" 답은 보기만 하세요. 첫 번째로 문심일언의 답변부터 확인해보겠습니다 (그 답은 안 된다고 합니다).
다음으로 Kimi의 답변을 확인해보겠습니다 (답은 여전히 안 된다고 합니다):

그렇다면 qwen3 8b 모델의 답변은 어떨까요?
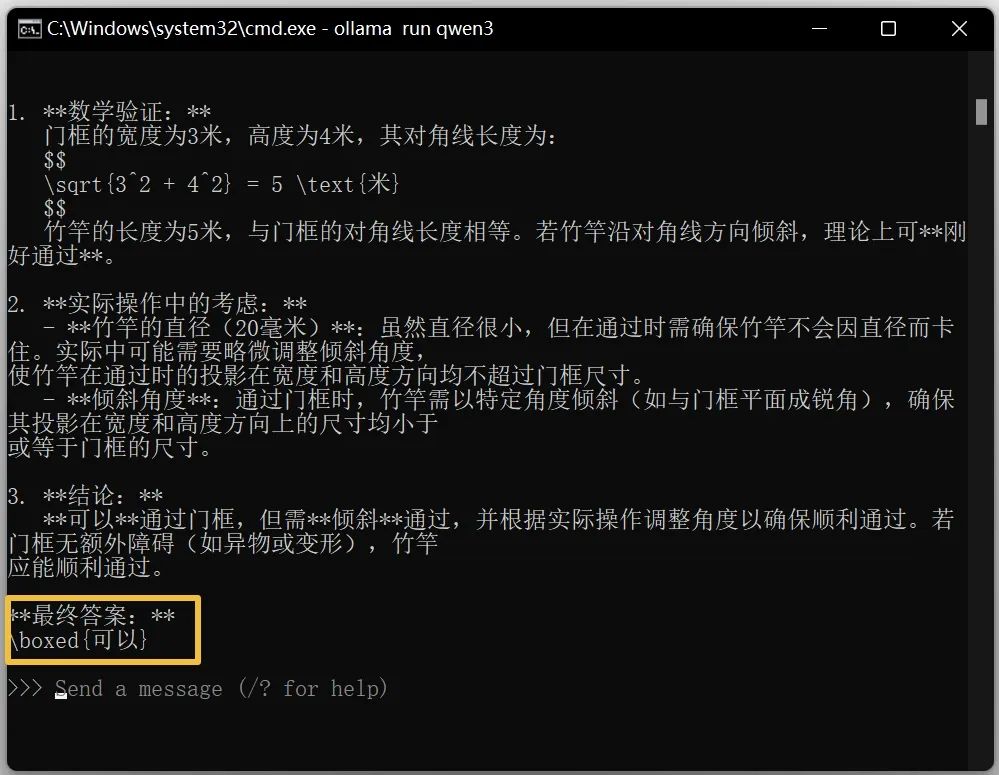
기대를 뛰어넘었네요. 8b를 테스트한 후, 14b 파라미터 모델은 어떤지 확인해보겠습니다. 8GB의 N카드로도 이 파라미터 수치를 돌릴 수 있다니 놀랍습니다! 하지만 출력 속도는 일반적으로 사람의 타자 속도의 약 2배 정도였습니다.
고시를 어떻게 잘 썼는지도 확인해보겠습니다.
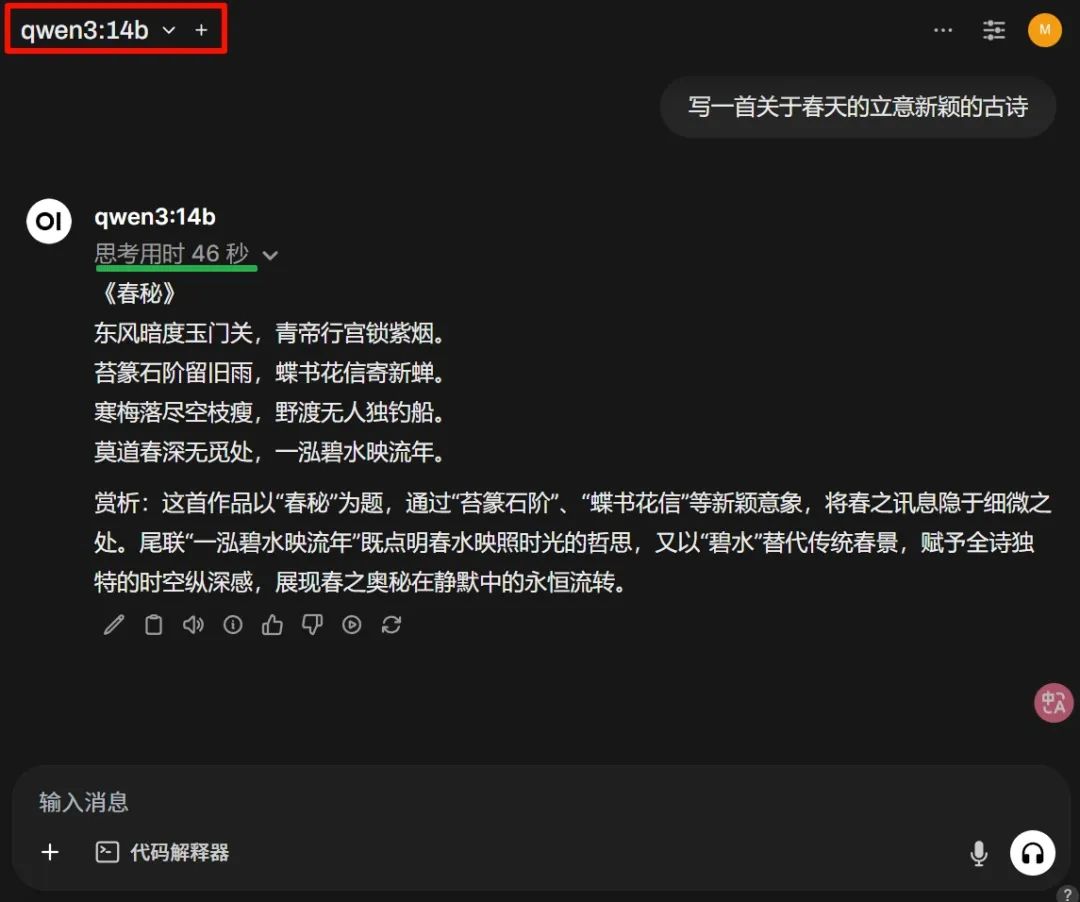
위 그림의 사고 시간은 완전히 수용 가능하며, 이는 8GB 비디오 메모리의 효율성을 보여줍니다. 품질이 가장 중요하겠죠. 전체적으로 직접 테스트한 모델에서 파라미터 수치는 크지 않지만, 성능은 괜찮은 편입니다. 본문 관계상 더 많은 사례를 보여주지는 못했지만, 이 추세라면 대부분의 폐쇄형 대형 언어 모델은 Qwen의 오픈소스에 의해 이길 것으로 예상됩니다. 여러분의 생각은 어떠신가요? 공식 풀 버전을 경험하고 싶다면 chat.qwen.ai를 방문해보세요.
멋진 리뷰들


Best AI Image Generator: FLUX.1 Kontext 모델의 혁신과 성능
FLUX.1 Kontext 모델은 AI 이미지 생성과 편집의 혁신을 가져오는 새로운 세대의 모델입니다.


최고의 AI 이미지 생성기: Vidu Q1 동영상 생성 모델의 혁신적 발전
Vidu Q1은 텍스트 설명이나 이미지에 따라 고화질의 1080P 비디오를 자동으로 생성하는 최첨단 AI 비디오 생성 모델입니다.


최고의 AI 이미지 생성기: 무료로 고품질 이미지를 생성하는 두 가지 도구
이 글에서는 무료 AI 이미지 생성기인 Raphael AI와 상양의 초단기 그림에 대해 살펴봅니다.






