OpenAI의 새로운 모델 시리즈인 GPT-4.1이 오늘 새벽에 발표되었습니다. 
이 시리즈는 GPT-4.1, GPT-4.1 mini, GPT-4.1 nano의 세 가지 모델로 구성되어 있으며, API 호출을 통해 모든 개발자에게 공개되었습니다. 이 모델들은 많은 주요 기능에서 유사하거나 더 나은 성능을 제공하며, 비용과 지연도 줄어들게 되었습니다. 따라서 OpenAI는 API에서 GPT-4.5의 프리뷰 버전을 3개월 후인 2025년 7월 14일에 사용 중단할 계획입니다. OpenAI는 이 세 가지 모델이 GPT-4o 및 GPT-4o mini를 전반적으로 초월하며, 프로그래밍 및 지시 준수 측면에서 모두 눈에 띄는 개선을 이루었다고 말했습니다. 이 모델들은 100만 개의 컨텍스트 토큰을 지원하는 상당히 큰 컨텍스트 창을 가지고 있으며, 개선된 긴 컨텍스트 이해를 통해 이러한 컨텍스트를 더 잘 활용할 수 있습니다. 지식 마감일도 2024년 6월로 업데이트되었습니다. 전반적으로, GPT-4.1은 다음과 같은 산업 기준 지표에서 뛰어난 성능을 보였습니다:
프로그래밍: GPT-4.1은 SWE-bench Verified 테스트에서 54.6%의 점수를 기록하여 GPT-4o보다 21.4% 향상되었고, GPT-4.5보다 26.6% 향상되어 최고의 프로그래밍 모델이 되었습니다.
지시 준수: Scale의 MultiChallenge 기준 테스트(지시 준수 능력을 측정하는 지표)에서 GPT-4.1은 38.3%의 점수를 기록하여 GPT-4o보다 10.5% 향상되었습니다.
긴 컨텍스트: 멀티모달 긴 컨텍스트 이해 기준 테스트인 Video-MME에서 GPT-4.1은 새로운 최고 기록을 세우며, 긴 비자막 테스트에서 72.0%의 점수를 기록하여 GPT-4o보다 6.7% 향상되었습니다. 비록 기준 테스트 결과가 매우 좋지만, OpenAI는 이 모델들을 훈련할 때 실제 유용성에 중점을 두었습니다. 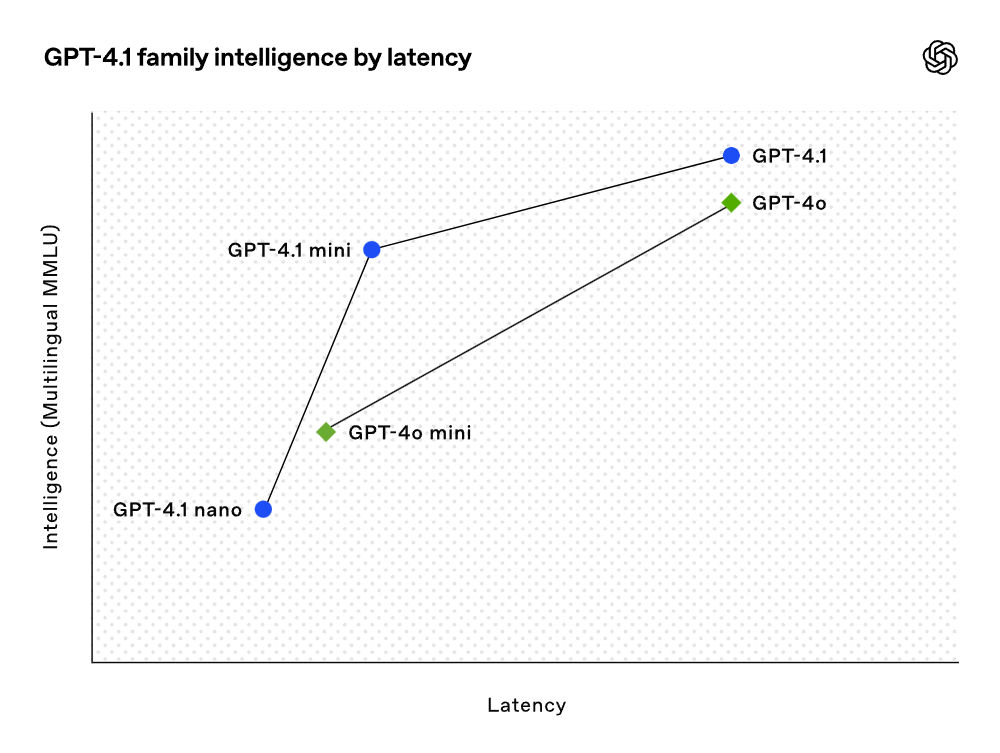
개발자 커뮤니티와의 긴밀한 협업과 파트너십을 통해 OpenAI는 개발자 애플리케이션과 가장 관련이 깊은 작업들을 최적화했습니다. 이로 인해 GPT-4.1 모델 시리즈는 더 낮은 비용으로 뛰어난 성능을 제공합니다. 이 모델들은 지연 곡선의 각 지점에서 성능 향상을 이루었습니다.
GPT-4.1 mini는 소형 모델 성능에서 눈에 띄는 도약을 이루었으며, 여러 기준 테스트에서 GPT-4o를 초과했습니다. 이 모델은 지능형 평가에 있어 GPT-4o와 동등하거나 더 나은 성능을 발휘하면서도 지연을 거의 절반으로 줄이고, 비용은 83%나 낮춰졌습니다. 낮은 지연이 요구되는 작업에 대해서는 GPT-4.1 nano가 OpenAI에서 가장 빠르고 비용이 저렴한 모델입니다. 이 모델은 100만 개의 토큰 컨텍스트 창을 갖추고 있으며, 소규모에서도 뛰어난 성능을 발휘하여 MMLU 테스트에서 80.1%, GPQA 테스트에서 50.3%, Aider 다국어 코딩 테스트에서 9.8%의 점수를 기록했습니다. 이는 GPT-4o mini보다도 더 높은 성과입니다. 이 모델은 분류 또는 자동 완성과 같은 작업에 이상적입니다. 지시 준수의 신뢰성과 긴 컨텍스트 이해에서의 개선 덕분에 GPT-4.1 모델은 사용자 대신 독립적으로 작업을 수행할 수 있는 시스템인 인공지능 에이전트를 더욱 효율적으로 구동할 수 있게 되었습니다. Responses API와 같은 원시 기능을 결합하여, 개발자들은 이제 실질적인 소프트웨어 공학에서 더 유용하고 신뢰할 수 있는 인공지능 에이전트를 구축할 수 있으며, 대규모 문서에서 통찰을 추출하고, 최소한의 수동 작업으로 고객의 요청을 처리하며, 기타 복잡한 작업을 수행할 수 있습니다. 또한 추론 시스템의 효율성을 향상시킴으로써 OpenAI는 GPT-4.1 시리즈의 가격을 낮출 수 있었습니다. GPT-4.1의 중간 규모 쿼리 비용은 GPT-4o보다 26% 낮으며, GPT-4.1 nano는 OpenAI에서 가장 저렴하고 빠른 모델입니다. 동일한 컨텍스트를 반복적으로 전달하는 쿼리에 대해 OpenAI는 새로운 모델 시리즈의 즉시 캐시 할인율을 이전의 50%에서 75%로 높였습니다. 추가로, 표준 토큰 비용 외에도 OpenAI는 긴 컨텍스트 요청을 제공하며, 추가 비용 없이 이용할 수 있습니다. 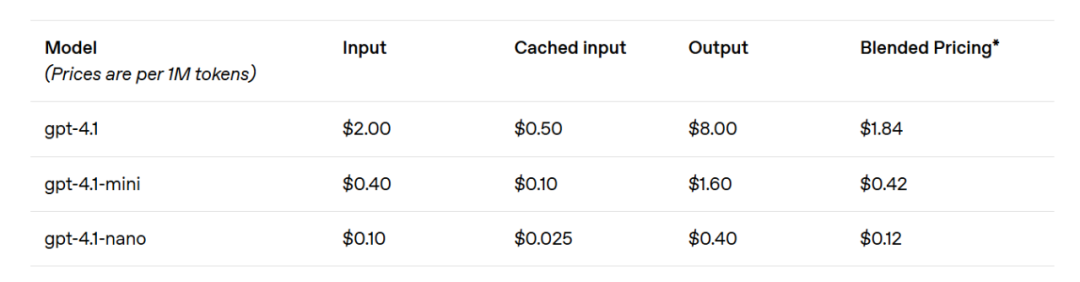
OpenAI CEO인 샘 알트만은 GPT-4.1이 기준 테스트 성적이 우수할 뿐만 아니라 실제 세계에서의 실용성에 중점을 두고 있어 개발자들이 기쁘게 느낄 것이라고 밝혔습니다. 
OpenAI는 자사 모델의 능력이 "4.10 > 4.5"라는 것을 성취한 것으로 보입니다. 
프로그래밍 GPT-4.1은 지능형 에이전트의 코딩 작업, 프론트엔드 프로그래밍, 관련 없는 편집 줄이기, diff 형식 준수 신뢰성 보장, 도구 사용 일관성 유지 등의 다양한 코딩 작업에서 GPT-4o보다 상당히 뛰어난 성과를 나타냈습니다. 현실 세계의 소프트웨어 공학 기술을 측정하는 SWE-bench Verified 테스트에서 GPT-4.1은 54.6%의 작업을 완료했으며, GPT-4o는 33.2%의 작업을 완료했습니다. 이는 이 모델이 코드베이스를 탐색하고 작업을 수행하며 실행 가능하고 테스트를 통과하는 코드를 생성하는 능력이 향상되었음을 반영합니다. 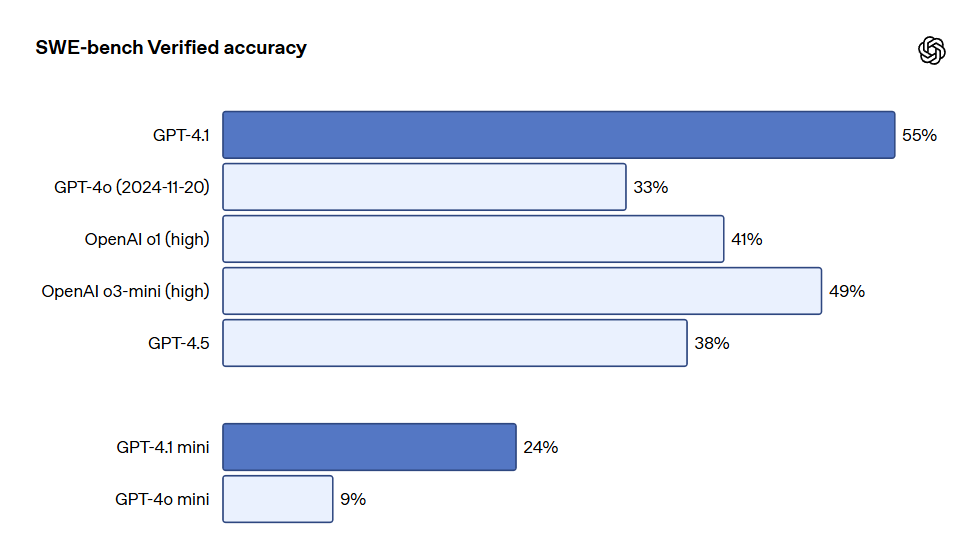
대규모 파일을 수정해야 하는 API 개발자에게 GPT-4.1은 다양한 형식의 코드 diff를 처리하는 데 더 신뢰할 수 있습니다. Aider의 다국어 차이 기준 테스트에서 GPT-4.1의 점수는 GPT-4o의 두 배 이상이며, GPT-4.5보다도 8% 높은 성과를 보였습니다. 이 평가는 다양한 프로그래밍 언어 간의 코딩 능력과 모델이 전반적 및 diff 형식에서 변경 사항을 생성하는 능력을 모두 측정합니다. OpenAI는 GPT-4.1을 더 신뢰성 있게 diff 형식을 준수하도록 특별히 훈련하여, 개발자들이 전체 파일을 재작성하지 않고 변경된 행만 출력할 수 있도록 하여 비용과 지연을 절약하고 있습니다. 한편 전체 파일을 재작성하고자 하는 개발자를 위해 OpenAI는 GPT-4.1의 출력 토큰 제한을 32,768개(이전의 GPT-4o의 16,384개보다 증가)로 늘렸습니다. 또한 OpenAI는 전체 파일 재작성의 지연을 줄이기 위해 예측 출력을 사용할 것을 권장하고 있습니다. 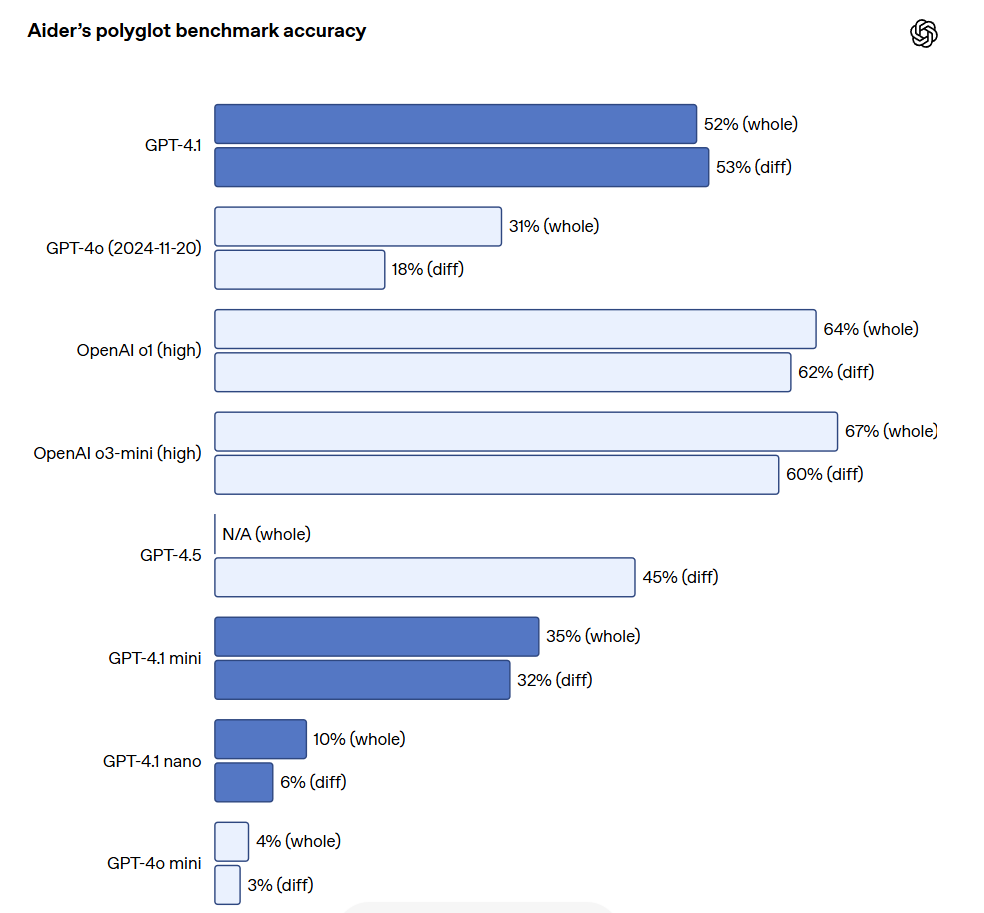
GPT-4.1은 또한 프론트엔드 프로그래밍 면에서도 GPT-4o보다 크게 향상되어, 더 강력하고 더 아름다운 웹 애플리케이션을 만들 수 있습니다. 비교 테스트에서 유료 인공지능 평가자의 80%가 GPT-4.1의 웹사이트가 GPT-4o의 웹사이트보다 더 인기 있다고 평가했습니다. 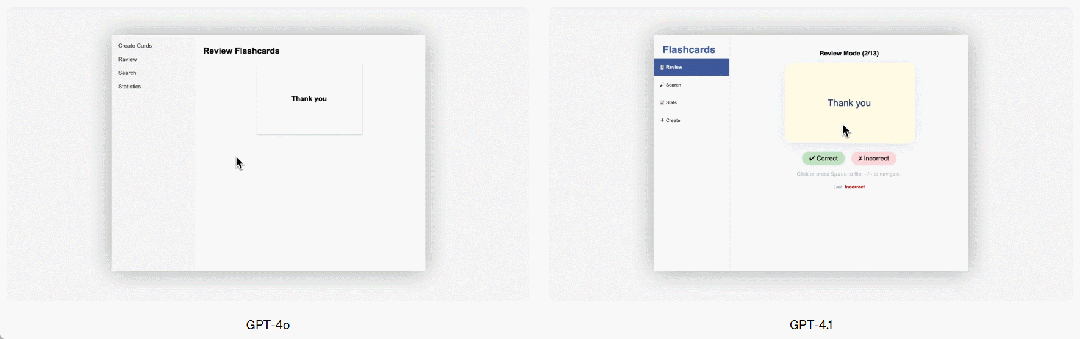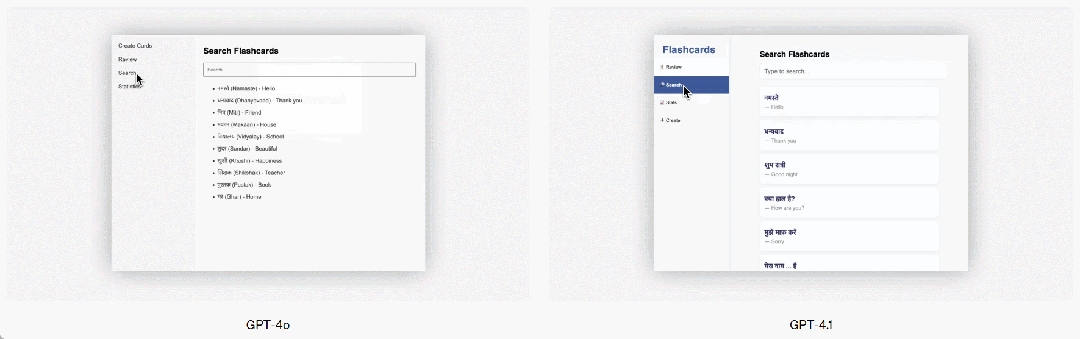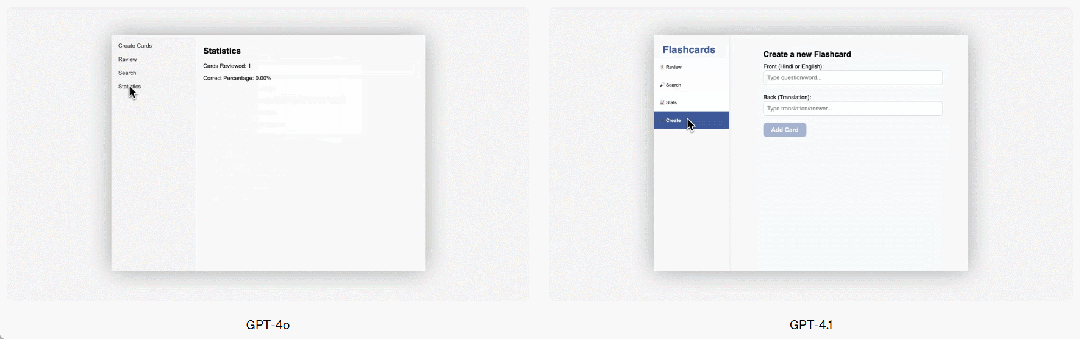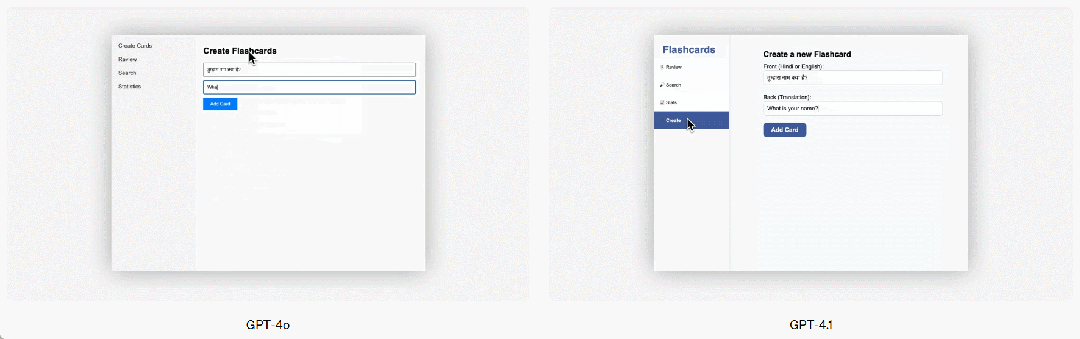
앞서 언급한 기준 테스트 외에도 GPT-4.1은 포맷 준수에서 더 나은 성능을 보이었으며, 신뢰성이 더 높고, 관련 없는 편집의 빈도를 줄이는 데 성공했습니다. OpenAI 내부 평가에서 코드의 관련 없는 편집은 GPT-4o의 9%에서 GPT-4.1의 2%로 감소했습니다.
지시 준수 GPT-4.1은 지시를 더 신뢰성 있게 따르며, 다양한 지시 준수 평가에서 눈에 띄는 개선을 실현했습니다. OpenAI는 모델의 여러 차원 및 몇 가지 핵심 지시 실행 범주에서 성능을 추적하기 위해 내부 지시 준수 평가 시스템을 개발했습니다. 이 시스템은 다음과 같은 주요 범주로 나뉩니다: 포맷 준수, 제공되는 지시사항으로 모델 응답의 사용자 지정 포맷 지정(예: XML, YAML, Markdown 등) 지정, 방지해야 할 행동을 지정하는 부정 지시사항(예: "사용자에게 지원팀에 연락하도록 요구하지 마십시오"), 주어진 순서대로 따라야 하는 일련의 지시사항 제공, 특정 정보를 포함하는 콘텐츠 출력 요구(예: "영양 계획 작성 시 단백질 함량을 반드시 포함해야 합니다"), 출력 정렬 요구(예: "응답을 인구 수에 따라 정렬하십시오"), 지나치게 자신감 있는 행동 방지 지시(예: "정보가 없거나 요청이 주어진 카테고리에 해당되지 않을 경우 '모르겠습니다'라고 답변합니다"와 같은 지시). 이러한 카테고리는 개발자 피드백을 기반으로 하여, 어떤 지시 준수가 가장 유관하고 중요한지를 나타냅니다. 각 범주에서 OpenAI는 간단한, 중간 및 어려운 프롬프트로 분류했습니다. GPT-4.1은 특히 어려운 프롬프트에서 GPT-4o보다 뛰어난 성과를 보였습니다. 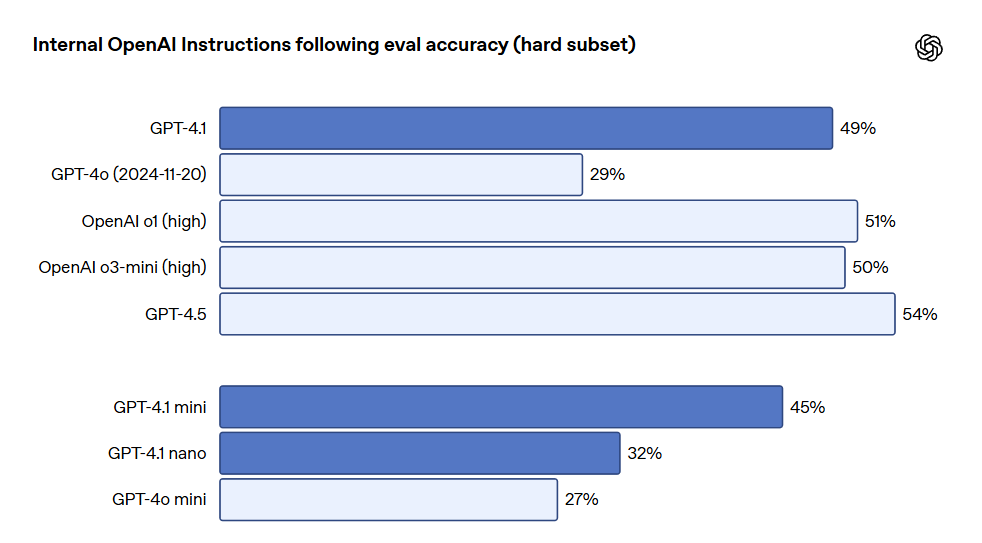
다중 지시 준수는 많은 개발자에게 중요합니다. 모델이 대화에서 일관성을 유지하고 사용자가 이전에 입력한 내용을 추적하는 것은 필수입니다. GPT-4.1은 대화에서의 과거 메시지들로부터 정보를 더 잘 인식할 수 있어 보다 자연스러운 대화를 가능하게 합니다. Scale의 MultiChallenge 기준 테스트는 이러한 능력을 측정하는 유효한 지표로, GPT-4.1은 GPT-4o보다 10.5% 더 높은 성과를 보였습니다. 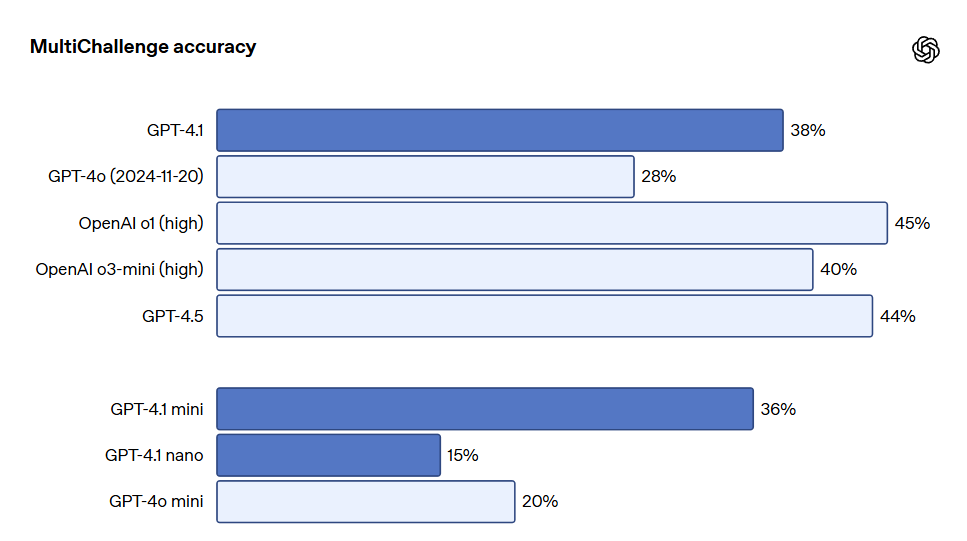
GPT-4.1은 IFEval에서도 87.4%의 점수를 기록했으며, GPT-4o는 81.0%의 점수를 받았습니다. IFEval은 내용 길이 지정 또는 특정 용어 또는 형식 사용 피하기 등 verifiable instructions를 가진 프롬프트를 사용합니다. 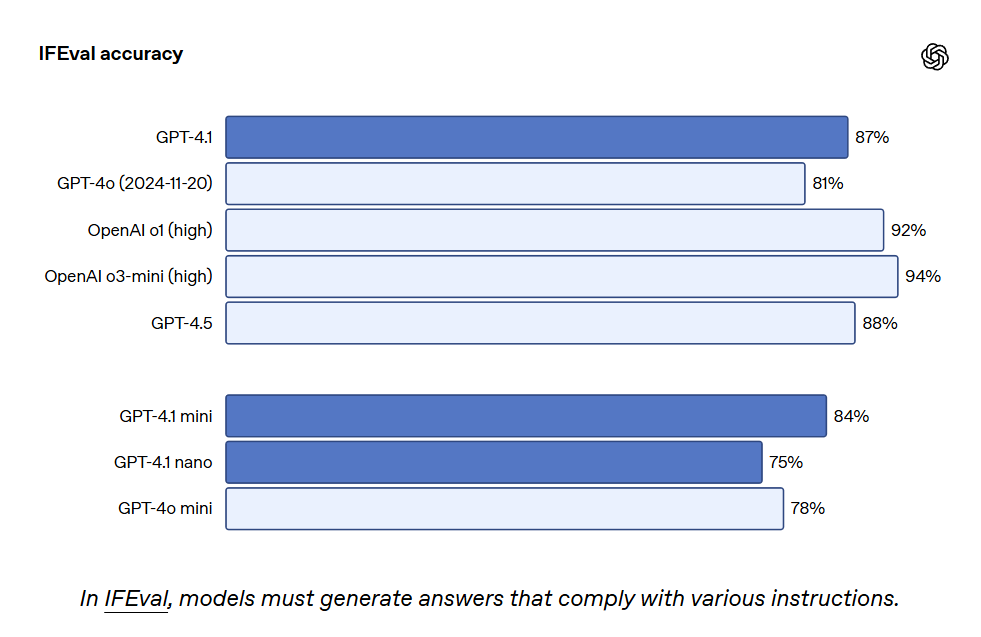
더 나은 지시 준수 능력은 기존 응용 프로그램을 더욱 신뢰하게 만들고, 이전에 신뢰성 저하로 제한된 새로운 응용 프로그램들을 지원합니다. 초기 테스트 참가자들은 GPT-4.1이 더 직관적이라고 언급했으며, OpenAI는 프롬프트에서 더 명확하고 구체적일 것을 권장했습니다.
긴 컨텍스트 GPT-4.1, GPT-4.1 mini 및 GPT-4.1 nano는 최대 100만 개의 컨텍스트 토큰을 처리할 수 있으며, 이전 GPT-4o 모델은 최대 12.8만 개의 토큰까지만 처리할 수 있었습니다. 100만 개의 토큰은 8개의 완전한 React 코드베이스에 해당하므로 긴 컨텍스트는 대규모 코드베이스 또는 많은 길고 긴 문서를 처리하는 데 적합합니다. GPT-4.1은 신뢰성 있게 100만 개의 토큰 길이 정보를 처리할 수 있으며, 관련 텍스트를 주의 깊게 인식하고 긴 컨텍스트 간섭을 무시하는 데 있어 GPT-4o보다 더욱 신뢰성 있는 성과를 보였습니다. 긴 컨텍스트 이해는 법률, 프로그래밍, 고객 지원 및 여러 다른 분야의 응용 프로그램에 있어 필수 능력입니다. 
OpenAI는 GPT-4.1이 컨텍스트 창 내의 각 지점에서 숨겨진 정보를 정확하게 검색할 수 있는 능력을 보여주었습니다. GPT-4.1은 입력 내에서 이러한 토큰들의 위치에 관계없이 모든 위치와 모든 컨텍스트 길이에서 최대 100만 개의 토큰을 정확하게 검색할 수 있습니다. 그러나 현실 세계에서는 사용자가 종종 모델이 여러 정보를 검색하고 이해해야 하며, 이 정보 간의 상호연관성을 이해해야 한다는 사실을 발견했습니다. 이를 보여주기 위해 OpenAI는 새로운 평가를 오픈 소스화했습니다: OpenAI-MRCR(다중 턴 공시). OpenAI-MRCR은 모델이 여러 "needle"을 인식하고 제거하는 능력을 테스트합니다. 이 평가는 사용자와 조수 간의 다중 턴 합성 대화를 포함하며, 사용자는 조수에게 "여우에 대한 시를 써주세요" 또는 "바위에 대한 블로그 글을 써주세요"와 같은 특정 주제에 대한 글 작성을 요청합니다. 그 후, 전체 컨텍스트에 두 개, 네 개 또는 여덟 개의 동일한 요청이 삽입되고, 마지막으로 모델은 특정 인스턴스에 해당하는 응답을 검색해야 합니다(예: "세 번째 여우에 대한 시를 주세요"). 이러한 요청은 다른 요청들과의 유사성 덕분에 미세한 차이로 인해 모델이 쉽게 혼란을 겪을 수 있습니다. 예를 들어, 여우에 대한 짧은 이야기 대신 시 또는 개구리에 대한 시 대신 여우의 시와 같은 경우입니다. OpenAI는 GPT-4.1이 최대 128K 개의 토큰 길이에서 GPT-4o보다 더 나은 성능을 보였으며, 100만 개의 토큰 길이에서도 강력한 성능을 유지할 수 있음을 발견했습니다. 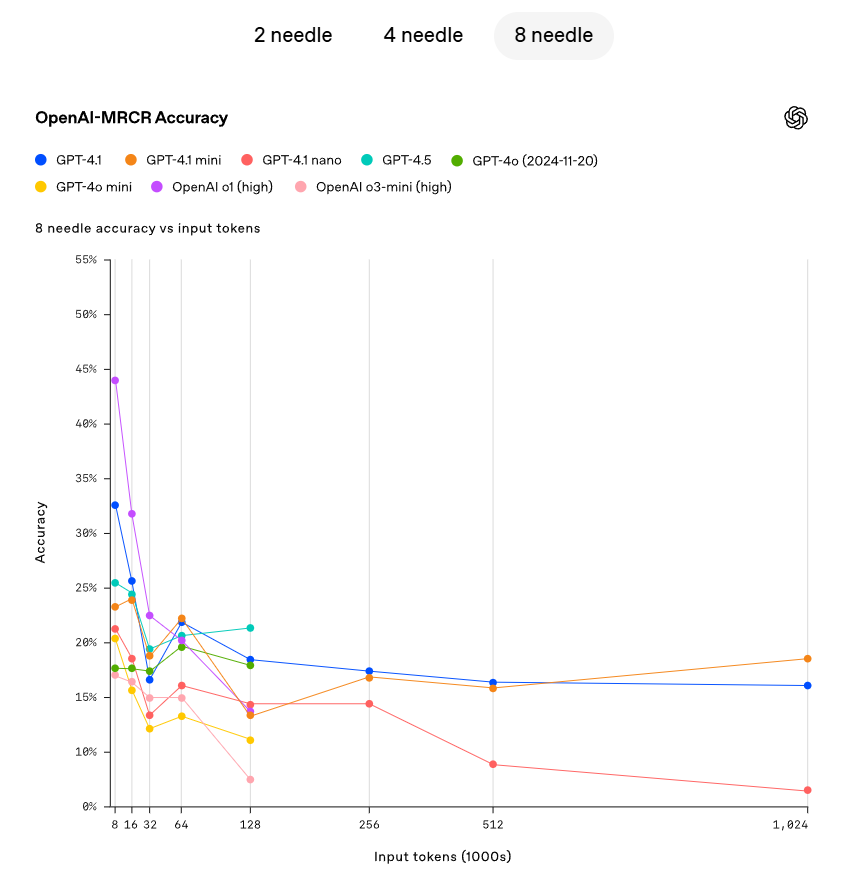
OpenAI는 또한 Graphwalks라는 다중 점프 긴 컨텍스트 추론을 평가하기 위한 데이터 세트를 발표했습니다. 많은 개발자들은 코드 작성 시 여러 파일 간에 이동하거나 복잡한 법적 문제를 해결할 때 문서를 교차 참조하는 등 긴 컨텍스트 사용 사례에서 여러 번의 논리적 점프를 수행해야 합니다. 이론적으로 모델(및 인간)은 OpenAI-MRCR 문제를 반복적으로 풀이하여 해결할 수 있지만, Graphwalks의 설계는 컨텍스트 내 여러 위치에서 추론하는 것을 요구하므로 순차적으로 해결할 수 없습니다. Graphwalks는 16진수 해시 값으로 구성된 유향 그래프로 컨텍스트 창을 채운 후 모델에게 그래프 내의 임의 노드에서 너비 우선 검색(BFS)를 수행하도록 요구합니다. 그 후 특정 깊이의 모든 노드를 반환하도록 요청합니다. 결과적으로 GPT-4.1은 이 기준 테스트에서 61.7%의 정확도를 기록하여 UP의 성능과 비슷하게 나타났으며, GPT-4o를 쉽게 이겼습니다. 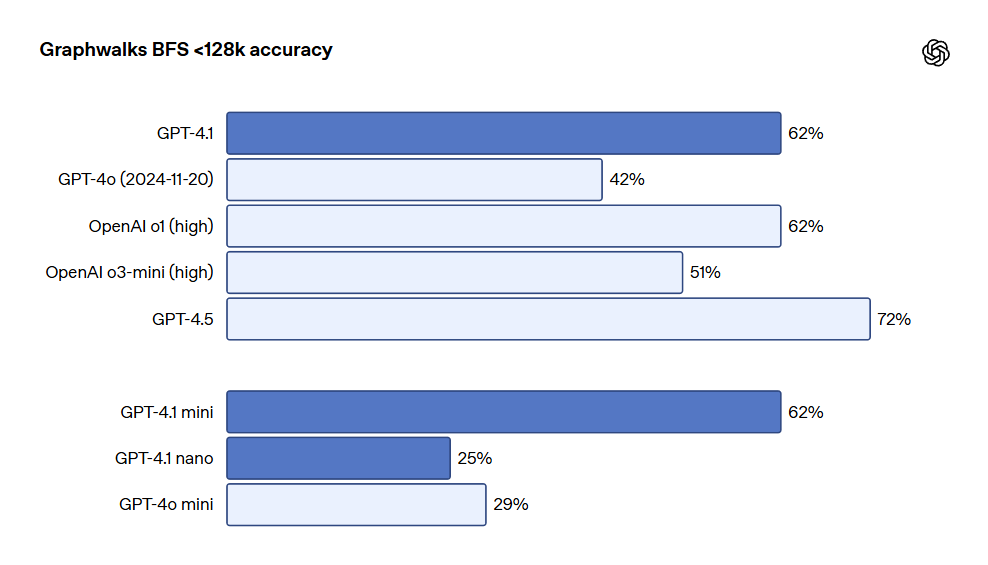
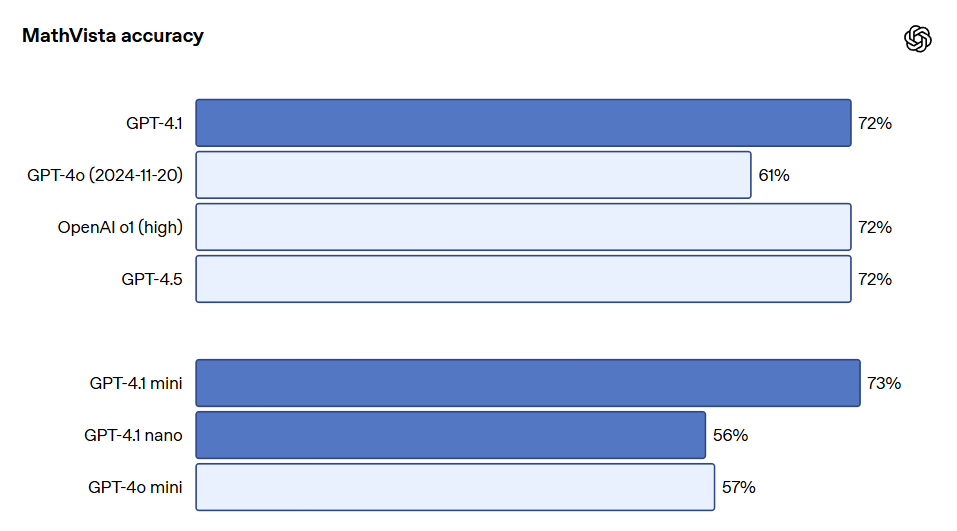
비주얼 GPT-4.1 시리즈 모델은 이미지 이해에 있어서도 매우 강력하며, 특히 GPT-4.1 mini는 이미지 기준 테스트에서 종종 GPT-4o를 초과하는 중요한 비약을 이루었습니다. 아래는 MMMU(차트, 도표, 지도 등에 관한 질문에 대한 응답), MathVista(시각적 수학 문제 해결), CharXiv-Reasoning(과학 논문 내 차트에 관한 질문에 대한 응답) 등 기준에서의 성과 비교입니다. 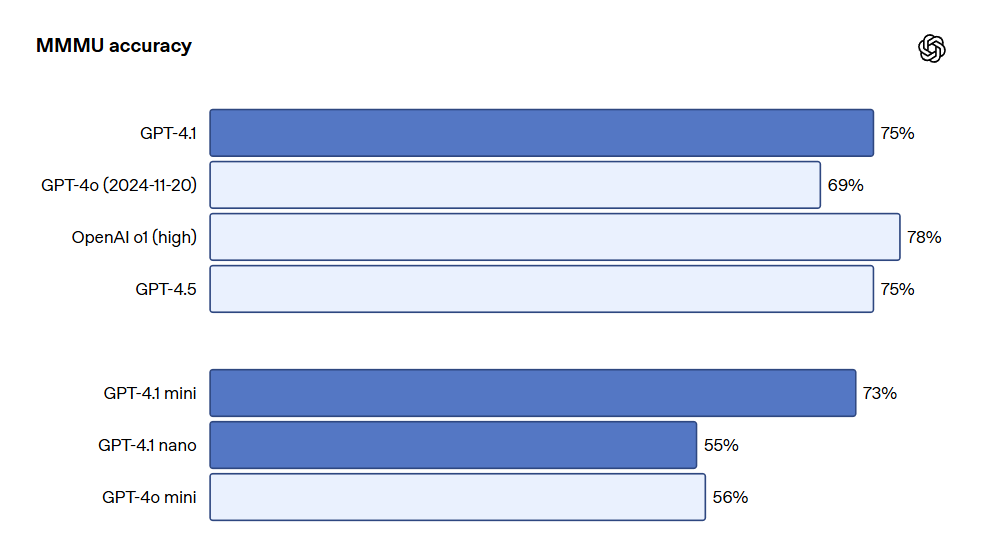
긴 컨텍스트 성능은 멀티모달 사용 사례(예: 긴 비디오 처리)에서도 필수적입니다. Video-MME(긴 비디오 비자막)에서 모델은 30-60분 길이의 비자막 비디오를 기반으로 여러 선택 질문에 답변을 제공합니다. GPT-4.1은 최고의 성과를 내어 72.0%의 점수를 기록하였고, 이는 GPT-4o의 65.3%보다 높은 수치입니다. 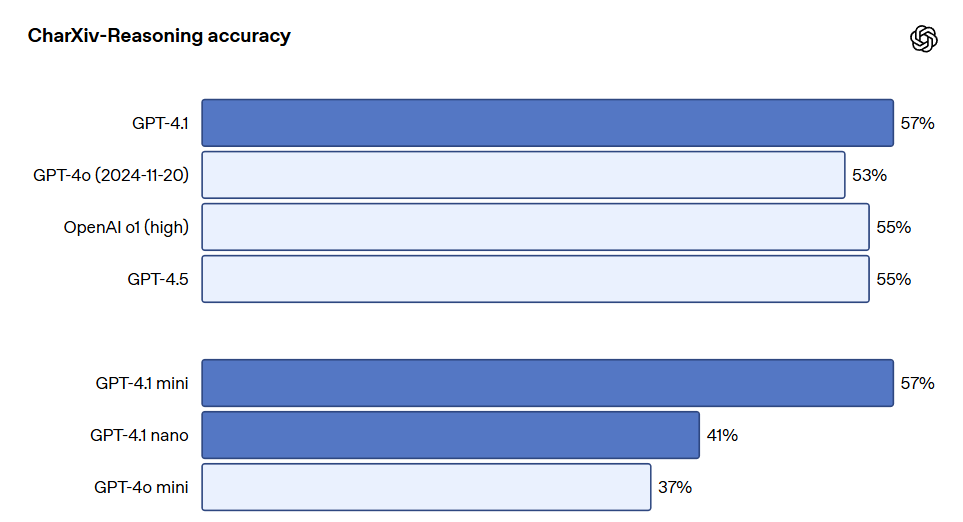
더 많은 테스트 지표에 대해서는 OpenAI 원 블로그를 참조해주세요. 블로그 주소: https://openai.com/index/gpt-4-1/
멋진 리뷰들


Best AI Image Generator: FLUX.1 Kontext 모델의 혁신과 성능
FLUX.1 Kontext 모델은 AI 이미지 생성과 편집의 혁신을 가져오는 새로운 세대의 모델입니다.


최고의 AI 이미지 생성기: Vidu Q1 동영상 생성 모델의 혁신적 발전
Vidu Q1은 텍스트 설명이나 이미지에 따라 고화질의 1080P 비디오를 자동으로 생성하는 최첨단 AI 비디오 생성 모델입니다.


최고의 AI 이미지 생성기: 무료로 고품질 이미지를 생성하는 두 가지 도구
이 글에서는 무료 AI 이미지 생성기인 Raphael AI와 상양의 초단기 그림에 대해 살펴봅니다.






