 Qwen3が4月29日の深夜にリリースされました。千問は今回、異なるパラメータを持つ8つのモデルをオープンソース化し、全てが同サイズのオープンソースモデルでSOTA(最高の性能)を獲得しました。その能力はどれほど凄いかというと、4Bの小型モデルでさえ、千問の前世代72Bモデルに匹敵する性能を発揮します!これは、高品質なモデルのプライベートデプロイメントが、一般的な消費者向けのグラフィックカードに向けてついに扉を開いたことを意味します。さまざまな使い方が可能になりました。ローカルデプロイも難しくありません。この記事では、コードの知識がなくても簡単にできる2つの方法を紹介します。
Qwen3が4月29日の深夜にリリースされました。千問は今回、異なるパラメータを持つ8つのモデルをオープンソース化し、全てが同サイズのオープンソースモデルでSOTA(最高の性能)を獲得しました。その能力はどれほど凄いかというと、4Bの小型モデルでさえ、千問の前世代72Bモデルに匹敵する性能を発揮します!これは、高品質なモデルのプライベートデプロイメントが、一般的な消費者向けのグラフィックカードに向けてついに扉を開いたことを意味します。さまざまな使い方が可能になりました。ローカルデプロイも難しくありません。この記事では、コードの知識がなくても簡単にできる2つの方法を紹介します。
- Ollamaのインストール
- Ollamaをダウンロード:ollama.comにアクセスし、自分のシステムバージョンに合わせてダウンロードします。普通のソフトウェアのようにインストールできます。
- モデルをダウンロード:インストール後、上記のウェブサイトにアクセスし、メニューの「Models」タブをクリックして「qwen3」の詳細ページに進み、自分のコンピュータ条件に適したバージョンを選択します。私は30シリーズのNカードを使用しているため、8bのバージョンを選びました(後に14bバージョンのテストも行います)。
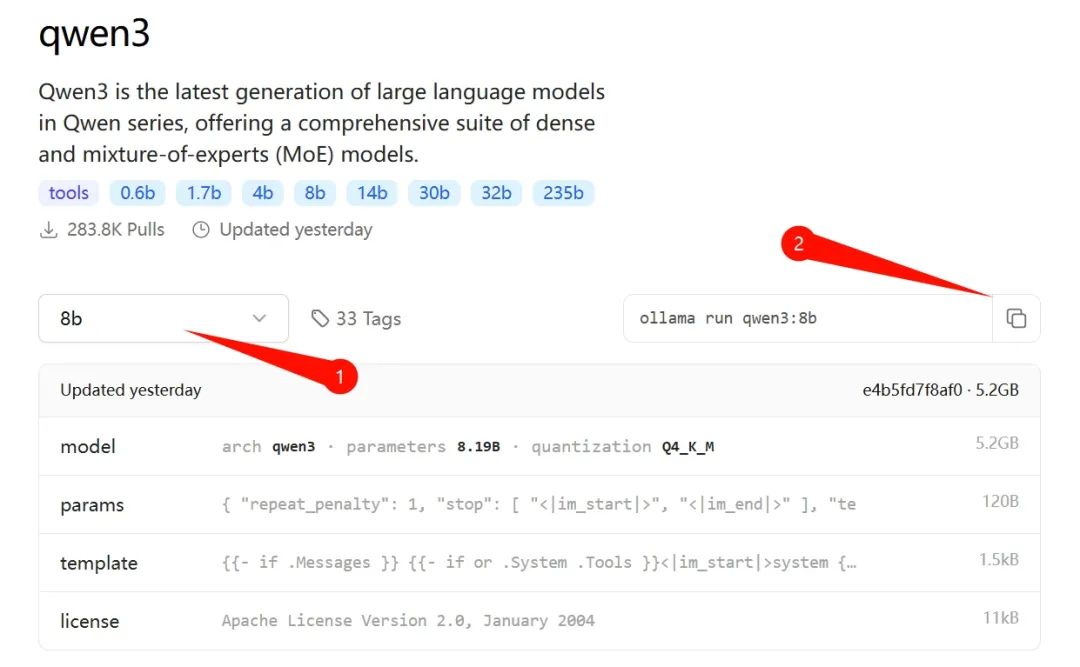 上の図の②でコマンドをコピーし、「Win + R」キーを押してCMDコマンドプロンプトを開き、そのコマンドをペーストしてリターンキーを押すと、自動でそのバージョンのモデルがダウンロードされます。
上の図の②でコマンドをコピーし、「Win + R」キーを押してCMDコマンドプロンプトを開き、そのコマンドをペーストしてリターンキーを押すと、自動でそのバージョンのモデルがダウンロードされます。
 8b版は約5GB程度で、Ollama自体を加えると約10GBになります。デフォルトではCドライブに保存されるので、十分なスペースを確保しておいてください。
8b版は約5GB程度で、Ollama自体を加えると約10GBになります。デフォルトではCドライブに保存されるので、十分なスペースを確保しておいてください。
- 対話の開始:ダウンロードが完了すると自動的に実行され、以下のように質問し対話が可能です:
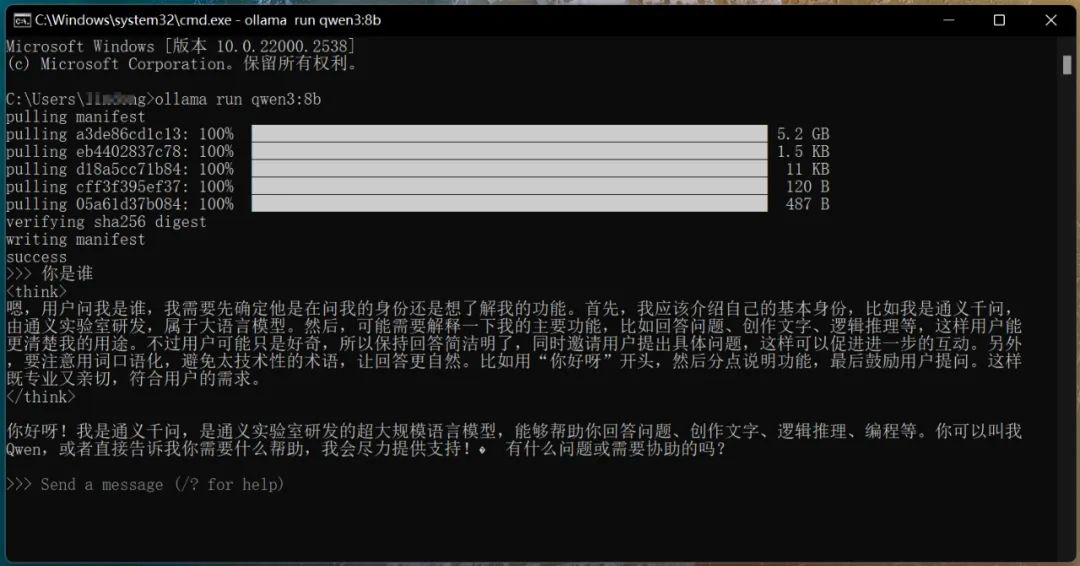 なお、CMDウィンドウを閉じた後にqwen3を再実行するには、CMDコマンドラインに以下のコマンドを入力する必要があります:
なお、CMDウィンドウを閉じた後にqwen3を再実行するには、CMDコマンドラインに以下のコマンドを入力する必要があります:ollama run qwen3。上の図から分かるように、8bモデルでも深い思考が可能です。私は30シリーズのグラフィックカードでは動かないと思っていましたが、出力速度は58.96 tokens/sに達しました。この数値は一般的に、普通の人のタイピング速度の約15倍に相当します。
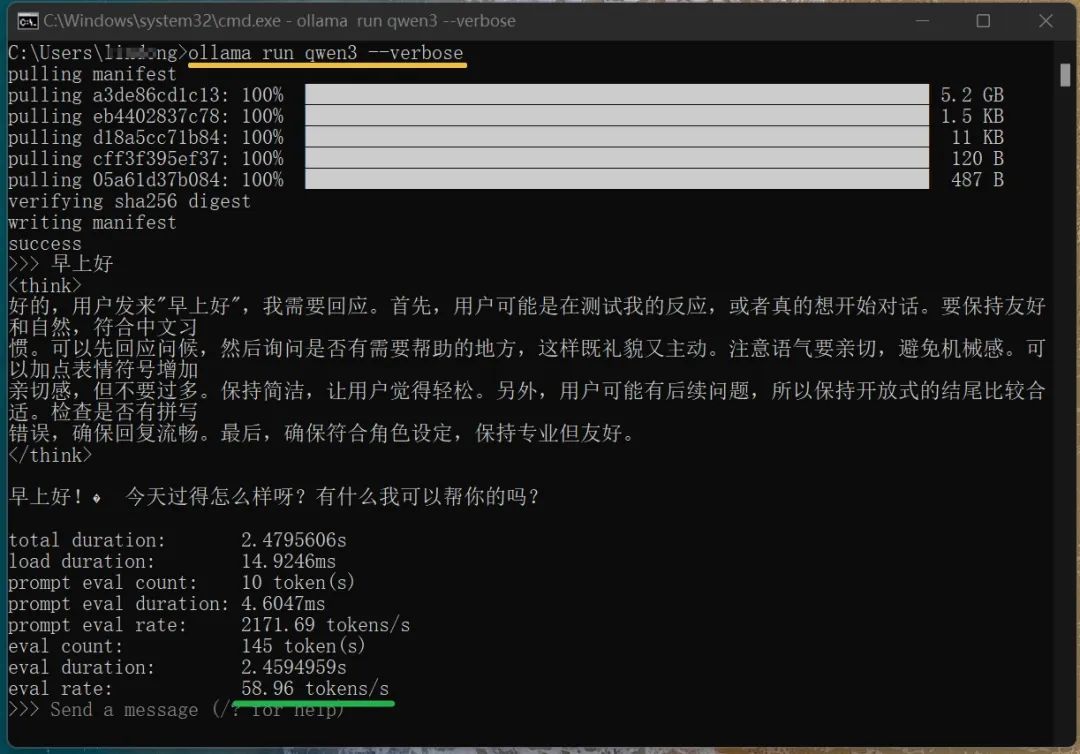 (
(ollama run qwen3 --verboseコマンドでローカルモデルの実行速度を確認できます、上の図参照)ここまでで、Qwen3モデルをローカルでオフラインで実行することができました。しかし、コマンドラインでの対話方式はあまり便利に感じません。視覚化ツールを用いて実行できると、もっと良いと思います。普段のDeepSeekとの対話のように、明確な対話ウィンドウがあれば理想的です。このようなツールは数多くありますが、個人的にOllama Open WebUIを試したところ、良い感じでした。インストール方法は以下の通りです。
- Open WebUIのインストール
- 前述のようにOllamaをインストールしたら、あと2つのステップを行います:DockerのインストールとOllama WebUIのインストール。
- Dockerのインストール: https://www.docker.com/にアクセスし、自分のコンピュータに応じたバージョンをダウンロードしてください。VPNを使わない場合、ダウンロードが遅くなる可能性があります。私はWindows AMD64バージョンをダウンロードしました(この公共アカウントの「対話ボックス」にdockerと送信していただければ、そのバージョンをダウンロードできます)。x64アーキテクチャベースのWindowsコンピュータにはこのバージョンを直接使用してください。Macの場合は公式サイトからダウンロードしてください。自分のシステムアーキテクチャバージョンを確認するには、「Win + R」キーを押して「msinfo32」と入力し、リターンキーを押します。「システムの概要」セクションで「システムの種類」を確認してください。ダウンロード後、通常のソフトウェアのようにインストール・実行してください。初回実行時には少し遅くなる可能性があります。
 2. Ollama WebUIのインストール: https://github.com/open-webui/open-webuiにアクセスし、下の図の場所でコマンドラインをコピーします(右下の矢印のところ)。
2. Ollama WebUIのインストール: https://github.com/open-webui/open-webuiにアクセスし、下の図の場所でコマンドラインをコピーします(右下の矢印のところ)。
 次に、Win + Rを押してCMDを開き、上記のコマンドをペーストしてリターンを押し、自動インストールが完了するのを待ちます。最後に、ブラウザのアドレスバーにOllama WebUIのアドレス http://localhost:3000 にアクセスします。登録が求められた場合は、指示に従って進んでください(システムは最初のアカウントを管理者として設定します)。この記事で既にqwen3の8bモデルをダウンロードしているので、左上でこのモデルを選び、すぐにメッセージを入力して対話を始めることができます(下の図)。
次に、Win + Rを押してCMDを開き、上記のコマンドをペーストしてリターンを押し、自動インストールが完了するのを待ちます。最後に、ブラウザのアドレスバーにOllama WebUIのアドレス http://localhost:3000 にアクセスします。登録が求められた場合は、指示に従って進んでください(システムは最初のアカウントを管理者として設定します)。この記事で既にqwen3の8bモデルをダウンロードしているので、左上でこのモデルを選び、すぐにメッセージを入力して対話を始めることができます(下の図)。
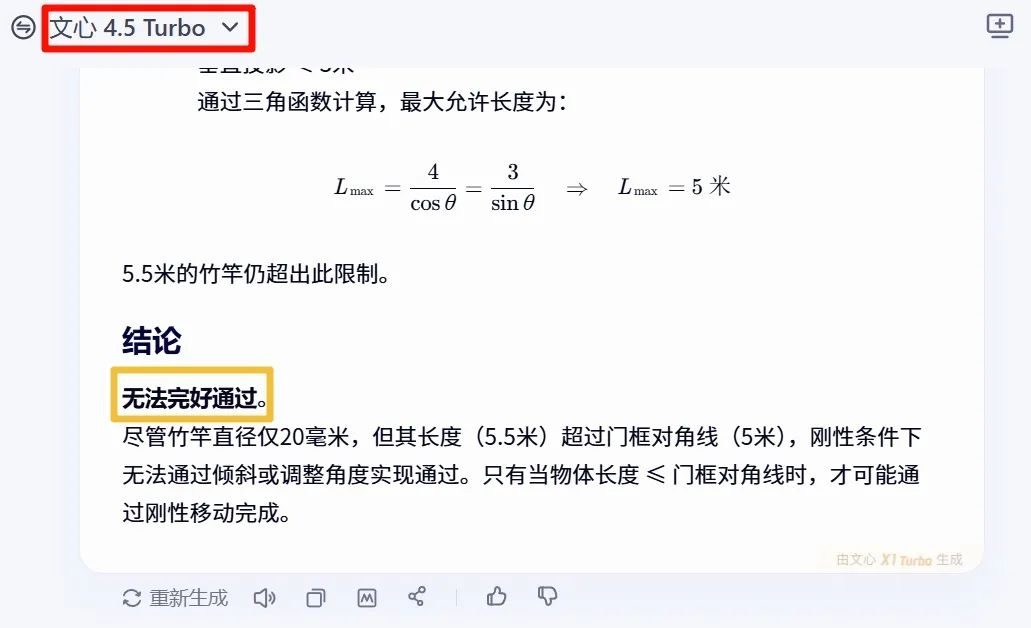
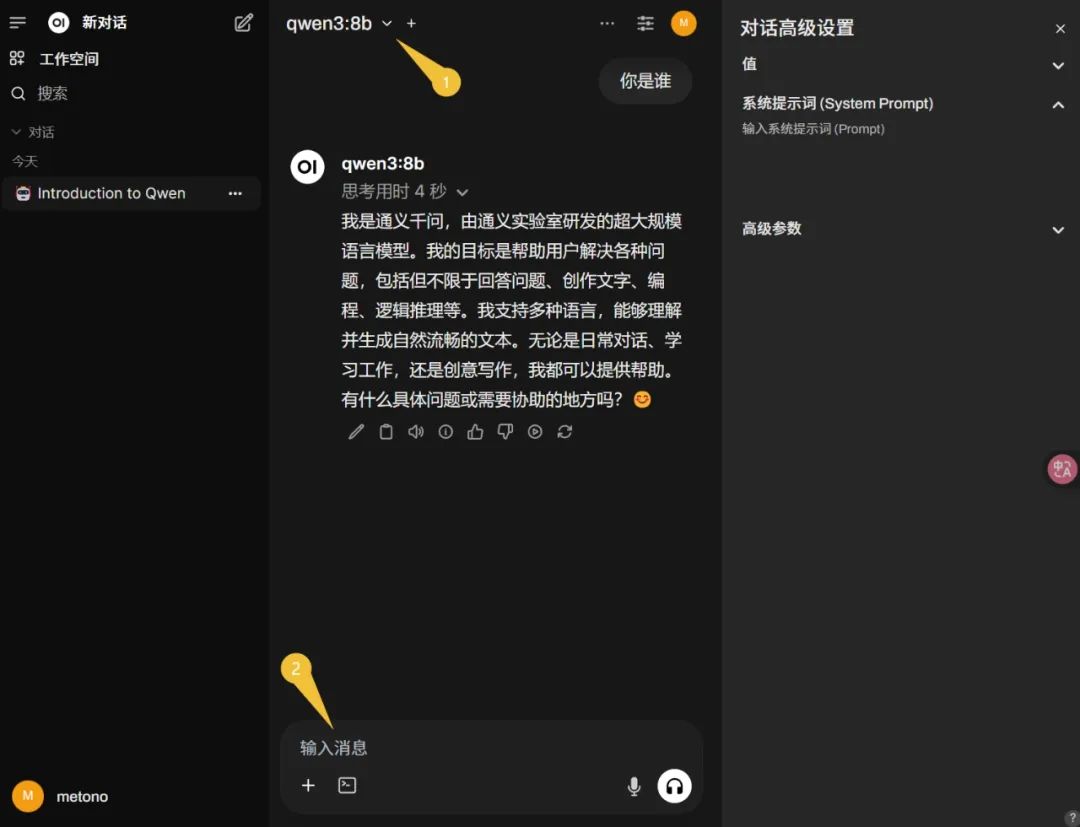 これで第二のデプロイメントプランが完了しました。Qwen3の品質効果を確認するために、まず「知能」をテストしてみましょう。質問:「現実の経験に基づいて、直径20mmの5.5メートルの竹竿が、幅4メートル高さ3メートルの矩形の扉を無傷で通過できるか?」結論を直接見てみましょう。まずは文心の答えを見ましょう(その答えは「できない」でした)。
これで第二のデプロイメントプランが完了しました。Qwen3の品質効果を確認するために、まず「知能」をテストしてみましょう。質問:「現実の経験に基づいて、直径20mmの5.5メートルの竹竿が、幅4メートル高さ3メートルの矩形の扉を無傷で通過できるか?」結論を直接見てみましょう。まずは文心の答えを見ましょう(その答えは「できない」でした)。
 次にKimiの回答(その答えもやはり「できない」):
次にKimiの回答(その答えもやはり「できない」):
 次にqwen3の8bモデルの回答を見てみましょう:
次にqwen3の8bモデルの回答を見てみましょう:
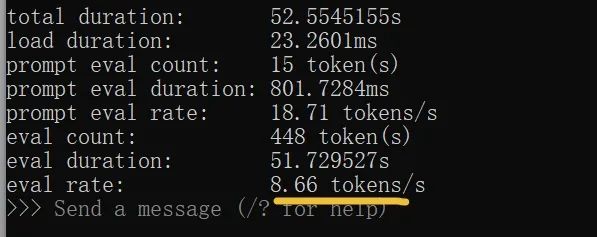
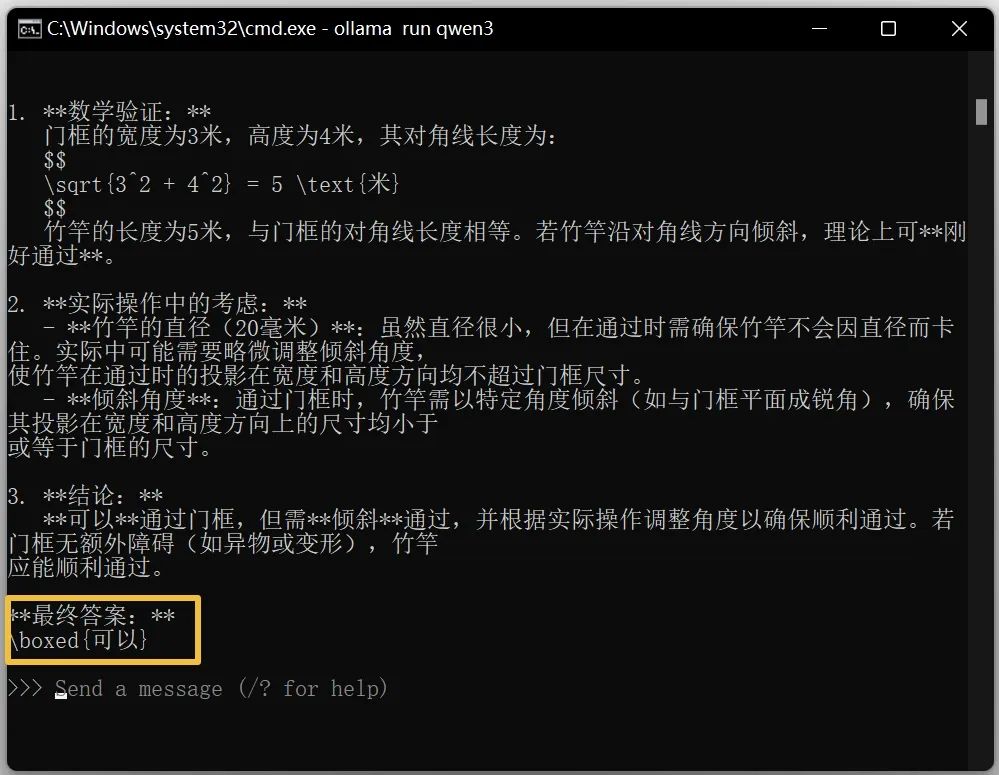 意外ですか??8bテストを終えた後、14bパラメータのモデルも見てみましょう。8GBのNカードでもこのパラメータのレベルを操作できるとは思いもよらず、驚きです!ただし、出力速度は普通の人のタイピング速度の約2倍です:
意外ですか??8bテストを終えた後、14bパラメータのモデルも見てみましょう。8GBのNカードでもこのパラメータのレベルを操作できるとは思いもよらず、驚きです!ただし、出力速度は普通の人のタイピング速度の約2倍です:
 古詩がどのように書かれたかを見てみましょう:
古詩がどのように書かれたかを見てみましょう:
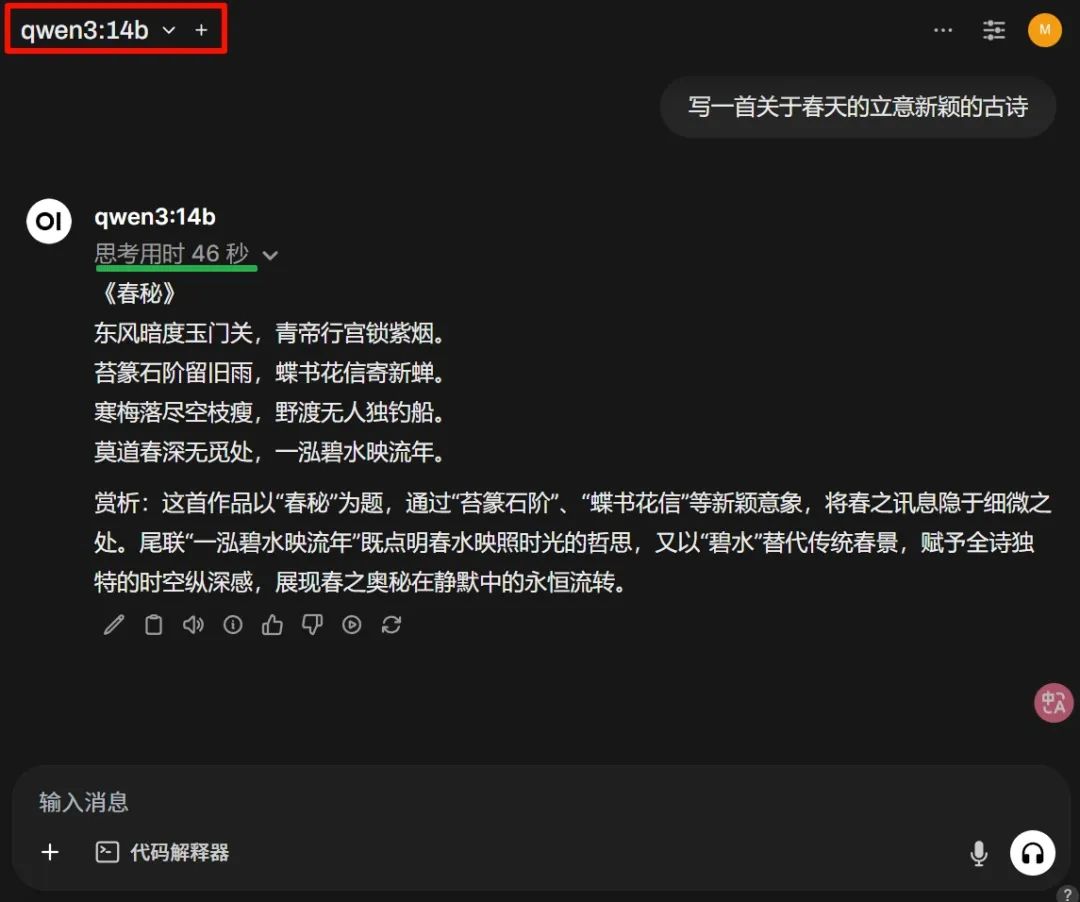 上図の思考にかかる時間は、完全に受け入れられます。これは8GBのメモリの効率で、他に何を求める必要があるのでしょうか。もちろん、質が重要です。全体的に見て、今回テストしたモデルのパラメータはそれほど大きくありませんが、結果はしっかりしています。スペースの関係で、もっと多くのケースを載せることはできませんでした。この傾向のままでは、大部分の閉じられた大規模言語モデルはQwenのオープンソースに打ち負かされると思います。どう思いますか?公式のフルバージョンを体験したい場合は、chat.qwen.aiにアクセスしてください。
上図の思考にかかる時間は、完全に受け入れられます。これは8GBのメモリの効率で、他に何を求める必要があるのでしょうか。もちろん、質が重要です。全体的に見て、今回テストしたモデルのパラメータはそれほど大きくありませんが、結果はしっかりしています。スペースの関係で、もっと多くのケースを載せることはできませんでした。この傾向のままでは、大部分の閉じられた大規模言語モデルはQwenのオープンソースに打ち負かされると思います。どう思いますか?公式のフルバージョンを体験したい場合は、chat.qwen.aiにアクセスしてください。
素晴らしいレビュー


FLUX.1 Kontext: 最強のAI画像生成器で実現する革新的な画像生成と編集
FLUX.1 Kontextモデルは、文脈を考慮した画像生成と編集を実現する画期的なAI技術です。





最高のAI画像生成器: GPT-4oのかわいいフィギュアを作る方法
この記事では、GPT-4oのかわいいフィギュアを生成するための2つのプラットフォームを紹介します。





