今日の早朝、OpenAI の新しいシリーズモデル GPT-4.1 がついに登場しました!
このシリーズには、GPT-4.1、GPT-4.1 mini、GPT-4.1 nano の3つのモデルが含まれており、すべて開発者に向けて API 経由で公開されています。このモデル群は、特に重要な機能において GPT-4o や GPT-4o mini を超える性能を提供しつつ、コストと遅延も削減されています。そのため、OpenAI は三ヶ月後(2025 年 7 月 14 日)に GPT-4.5 のプレビュー版を API から廃止することを決定しました。OpenAI によれば、この三つのモデルは全体的な性能が GPT-4o および GPT-4o mini を上回り、プログラミングや指示に従う能力が大幅に向上しています。さらに、これらのモデルは最大 100 万トークンのコンテキストウィンドウを持ち、改良された長期的なコンテキスト理解を通じて、より良いコンテキストの活用が可能です。知識のカットオフ日は 2024 年 6 月に更新されています。総合的に見て、GPT-4.1 は以下の業界標準指標において優れた性能を示しています:
- プログラミング:GPT-4.1 は SWE-bench Verified テストで 54.6% のスコアを達成し、GPT-4o より 21.4%、GPT-4.5 より 26.6% 向上しました。これにより、リーディングプログラミングモデルとなりました。
- 指示遵守:Scale の MultiChallenge ベンチマーク(指示遵守能力を測る指標)の中で、GPT-4.1 は 38.3% のスコアを得て、GPT-4o より 10.5% 向上しました。
- 長期的コンテキスト:マルチモーダル長期コンテキスト理解ベンチマーク Video-MME において、GPT-4.1 は長文無字幕テストで 72.0% の新しい最高記録を樹立し、GPT-4o より 6.7% 向上しました。
これらのテストスコアは非常に優れたものですが、OpenAI はこれらのモデルを訓練する際に実際の有用性に重点を置きました。開発者コミュニティとの密接な協力とパートナーシップを通じて、OpenAI は開発者アプリケーションに最も関連性の高いタスクに対する最適化を行いました。これにより、GPT-4.1 モデル系列は低コストで卓越した性能を提供しました。これらのモデルは、遅延曲線の各ポイントにおいて性能向上を達成しています。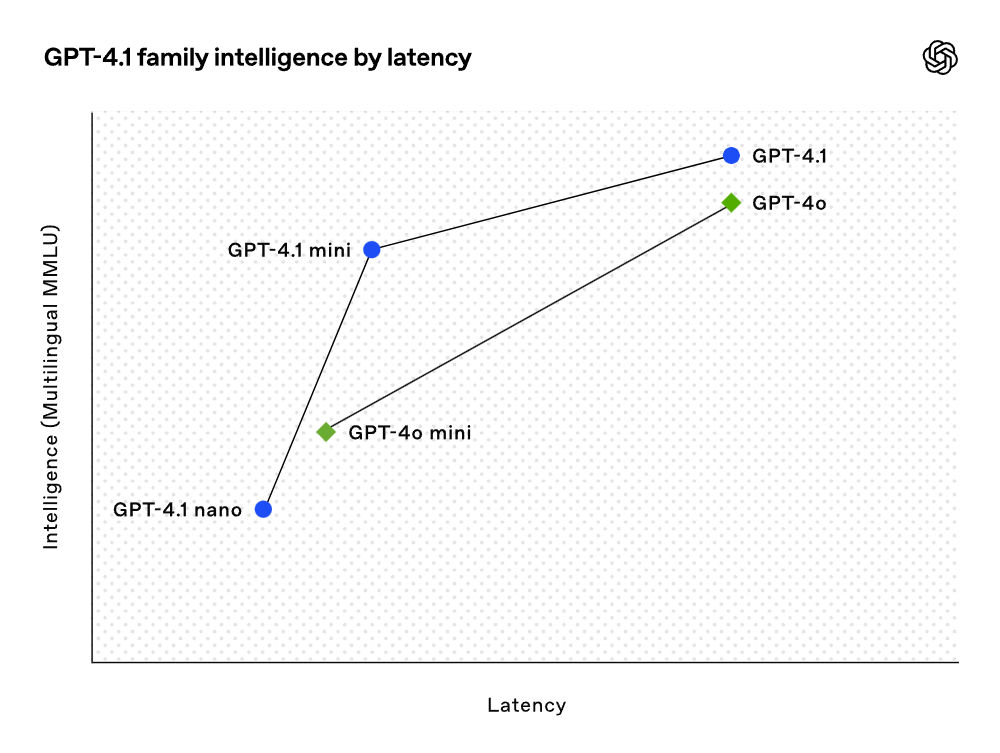
GPT-4.1 miniは、小型モデルの性能において顕著な飛躍を遂げ、さまざまなベンチマークで GPT-4o を上回りました。このモデルは、スマートな評価において GPT-4o に匹敵するか、それを凌駕しながら、遅延をほぼ半分に削減し、コストを 83% 削減しました。低遅延タスクを要求する場合、GPT-4.1 nano は OpenAI の中で最も速く、コストが最も低いモデルです。このモデルのコンテキストウィンドウは 100 万トークンであり、小規模なタスクにおいても卓越した性能を提供し、MMLU テストで 80.1%、GPQA テストで 50.3%、Aider の多言語コーディングテストで 9.8% を獲得しました。これは GPT-4o mini を上回る結果です。このモデルは、分類や自動補完などのタスクに理想的な選択肢です。指示遵守の信頼性や長期的コンテキスト理解の改善により、GPT-4.1 モデルは、自立的にユーザーのタスクを完了できるシステムであるインテリジェントエージェントをより効率的に駆動することが可能になりました。Responses API などの原語を組み合わせることで、開発者は実際のソフトウェア工学においてより有用で信頼性の高いエージェントを構築できるようになり、大規模なドキュメントから洞察を得るために最小限の手動操作で顧客のリクエストを解決し、他の複雑なタスクを実行することができます。同時に、推論システムの効率を向上させることで、OpenAI は GPT-4.1 シリーズの価格を引き下げることができました。GPT-4.1 の中規模クエリコストは GPT-4o より 26% 低く、GPT-4.1 nano は OpenAI の最も安価で高速なモデルです。同様に、同じコンテキストを繰り返し伝えるクエリに対して、OpenAI は新系列モデルの即時キャッシュ割引を従来の 50% から 75% に引き上げました。さらに、標準のトークンごとのコストに加えて、OpenAI は長期的コンテキストリクエストを提供し、追加の料金なしで利用可能です。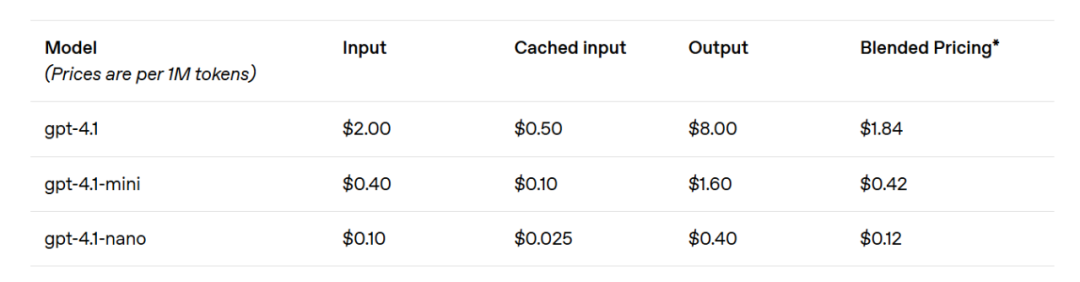
OpenAI の CEO サム・オルトマンは、GPT-4.1 が非常に高いベンチマークスコアを持つだけでなく、実世界での実用性にも重点を置いているため、開発者を喜ばせるものになるはずだと述べています。
どうやら、OpenAI は自社のモデル能力において「4.10 > 4.5」を達成したようです。
GPT-4.1 はさまざまなコーディングタスクにおいて、特にインテリジェントエージェントによるコーディングタスクの解決、フロントエンドプログラミング、無関係な編集の削減、diff フォーマットの信頼性の確保、ツール使用の一貫性の保持という点で、GPT-4o よりも顕著に優れています。実世界のソフトウェアエンジニアリングスキルを測定する SWE-bench Verified テストにおいて、GPT-4.1 は 54.6% のタスクを完了し、GPT-4o(2024-11-20)は 33.2% を完了しました。これは、このモデルがコードベースを探査し、タスクを完遂し、実行可能なコードを生成し、テストに合格した結果を反映しています。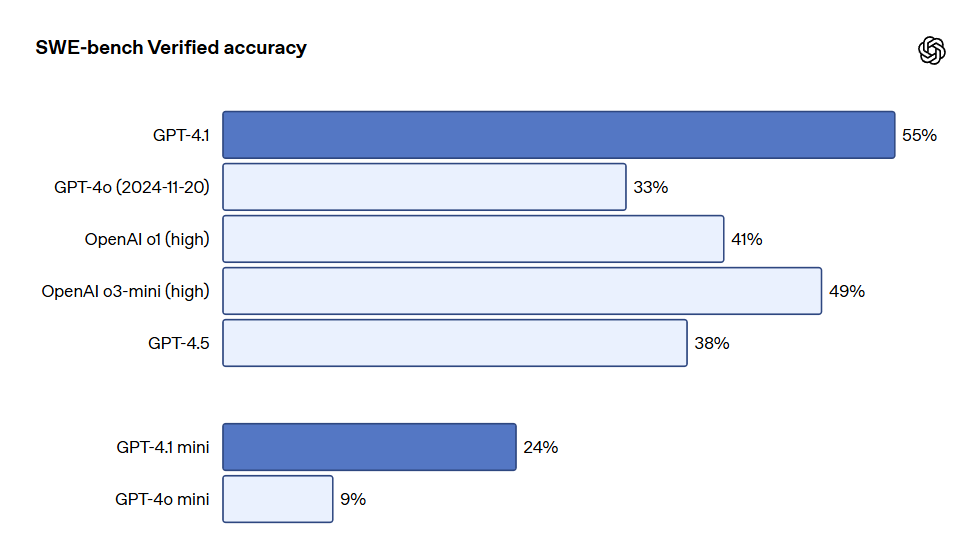
大規模ファイルを編集する API 開発者にとって、GPT-4.1 はさまざまな形式のコード diff を扱う際により信頼性が高いです。Aider の多言語差分ベンチマークにおいて、GPT-4.1 のスコアは GPT-4o の 2 倍以上となり、さらに GPT-4.5 よりも 8% 高い結果となりました。この評価は、さまざまなプログラミング言語にわたるコーディング能力、さらにモデルが全体的および diff フォーマットで変更を生成する能力を測定しています。OpenAI は GPT-4.1 を特に diff フォーマットに従うように訓練しており、そのため開発者は変更行のみを出力し、ファイル全体を再記述する必要がなく、コストと遅延を節約できます。同時に、ファイル全体を再記述することを好む開発者に対して、OpenAI は GPT-4.1 の出力トークン制限を 32,768 トークン(GPT-4o の 16,384 トークンを超えて)に引き上げました。OpenAI はまた、完全なファイルの再記述に要する遅延を減らすために予測出力を使用することを提案しています。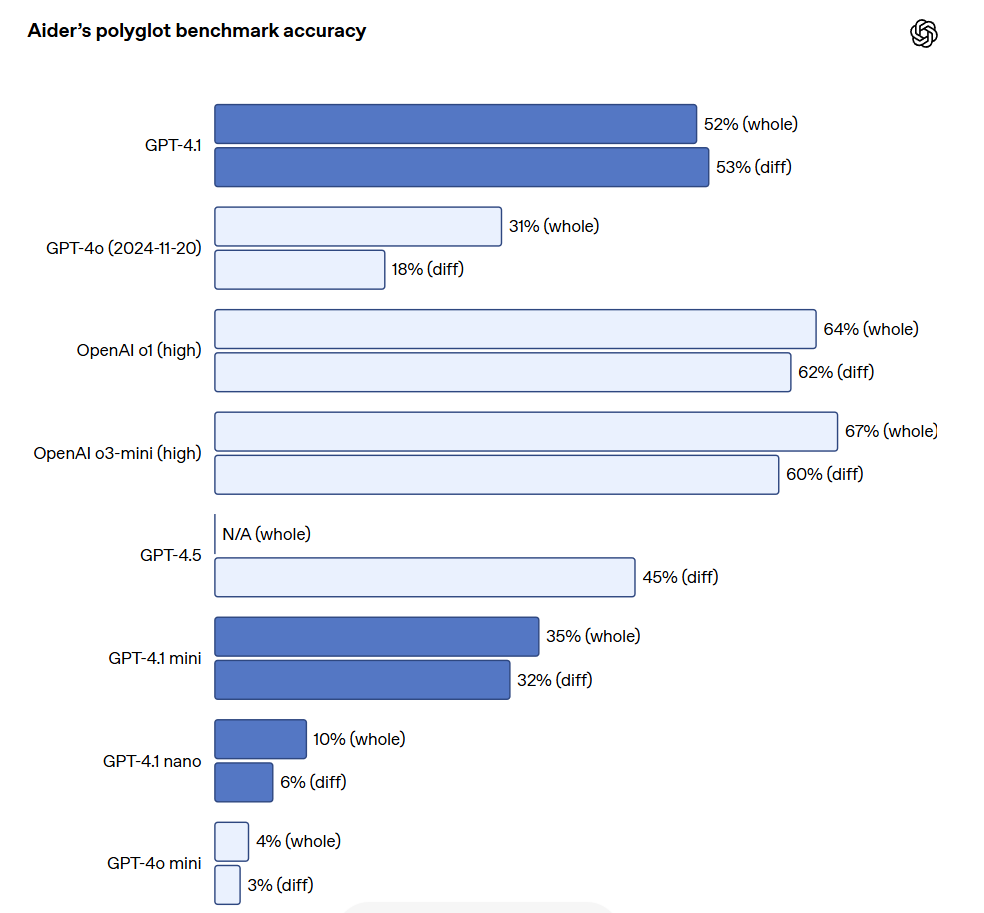
GPT-4.1 はフロントエンドプログラミングにおいても GPT-4o より顕著な向上を見せ、より強力で魅力的な Web アプリケーションを作成できます。直接比較では、ペイドエバリュエーターの 80% のスコアが、GPT-4.1 のウェブサイトが GPT-4o のウェブサイトよりも人気があることを示しています。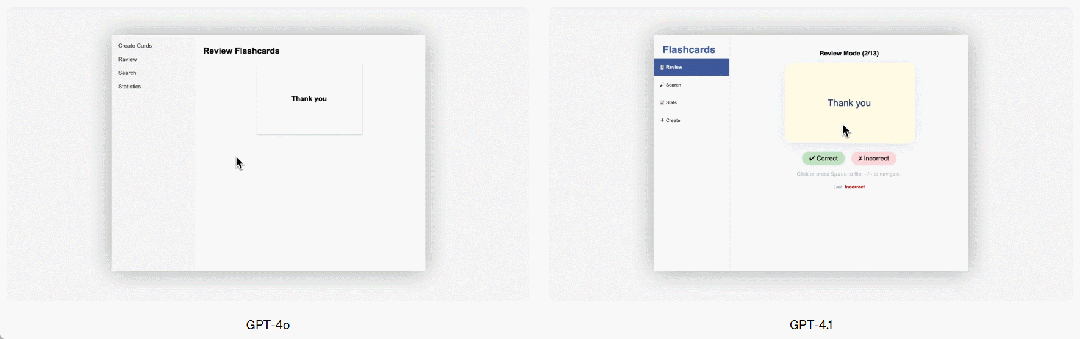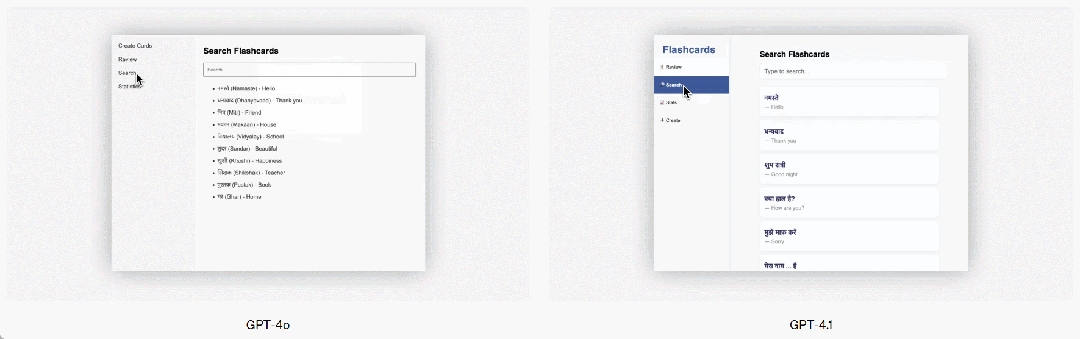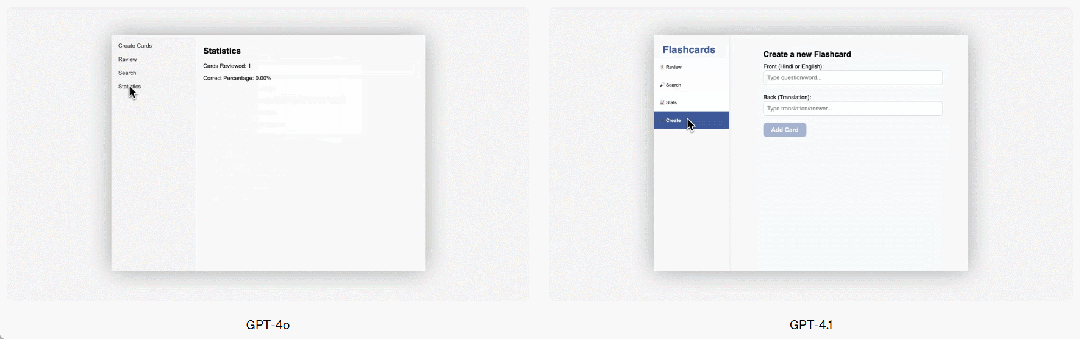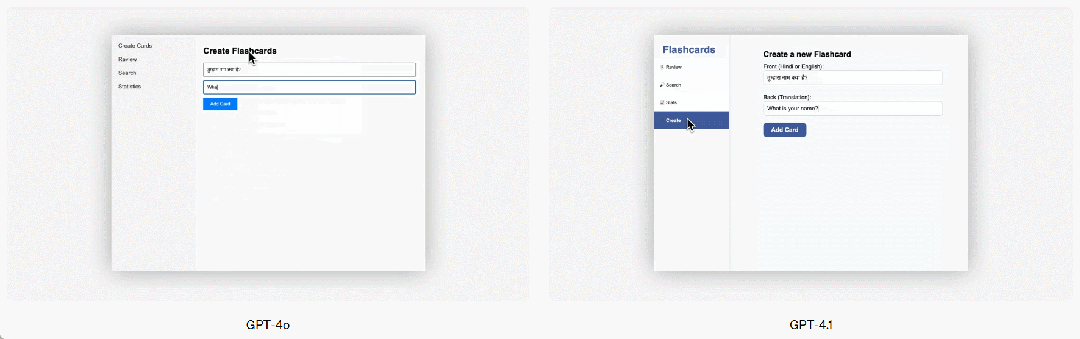
上記のベンチマークに加えて、GPT-4.1 は形式遵守においても優れた性能を発揮し、信頼性が高く、無関係な編集の頻度を減少させています。OpenAI の内部評価では、コード内の無関係な編集が GPT-4o の 9% から GPT-4.1 の 2% に減少しました。指示遵守においても、GPT-4.1 はより信頼性高く指示に従い、さまざまな指示遵守評価において著しい改善を遂げました。OpenAI は、多くの次元といくつかの重要な指示実行カテゴリのパフォーマンスを追跡するために、内部の指示遵守評価システムを開発しました。これには、以下のような項目が含まれています:
- 形式遵守:モデルのレスポンスに特定の形式を指定する指示を提供すること(例:XML、YAML、Markdownなど)。
- ネガティブ指示:モデルに避けてほしい行動を指定する(例:「ユーザーにサポート担当者に連絡するように求めないでください」)。
- 順序指示:モデルが指定された順序に従って一連の指示を提供する(例:「まずユーザーの名前を尋ね、その後にメールアドレスを尋ねてください」)。
- 内容要求:特定の情報を含む出力を要求する(例:「栄養プランを作成する際は、必ずタンパク質含有量を含めてください」)。
- ソート:特定の方式で出力をソートする(例:「人口数でレスポンスをソートしてください」)。
- 過剰自信:情報がない場合やリクエストが特定のカテゴリに属さない場合に「わかりません」と回答するよう指示する(例:「答えがわからない場合はサポートの連絡先メールアドレスを提供してください」)。
これらのカテゴリは、開発者のフィードバックに基づき最も重要かつ関連性の高い指示を特定したものです。それぞれのカテゴリ内で、OpenAI は簡単、中程度、難しいプロンプトのパフォーマンスを分類しました。特に GPT-4.1 は難しいプロンプトにおいて GPT-4o を大きく上回っています。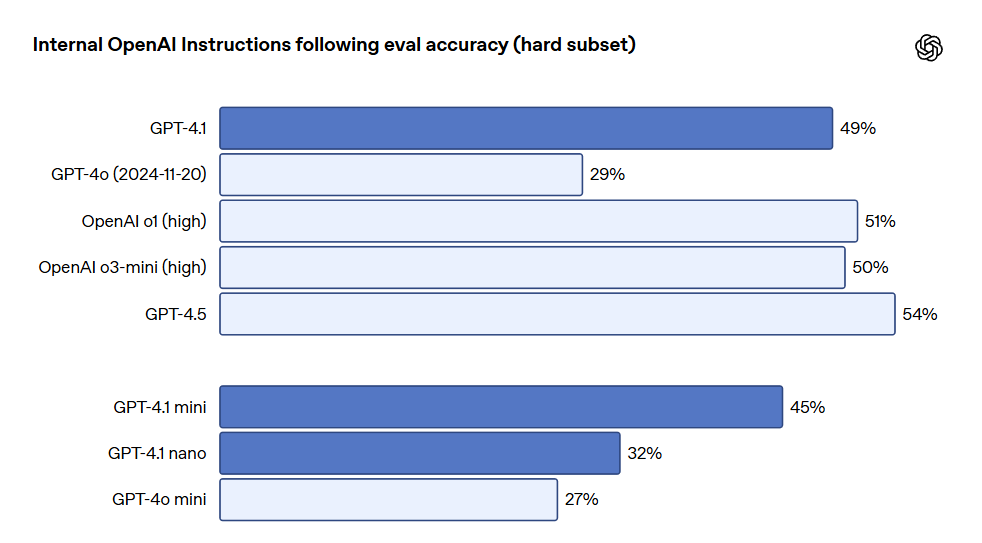
多重指示遵守は多くの開発者にとって非常に重要です。モデルにとって、対話を通して一貫性を保ち、ユーザーの前の入力を追跡することは極めて重要です。GPT-4.1 は、対話中の過去のメッセージから情報をよりよく識別できるため、より自然な対話を実現しています。Scale の MultiChallenge ベンチマークは、この能力を測るための有効な指標であり、GPT-4.1 のパフォーマンスは GPT-4o より 10.5% 向上しています。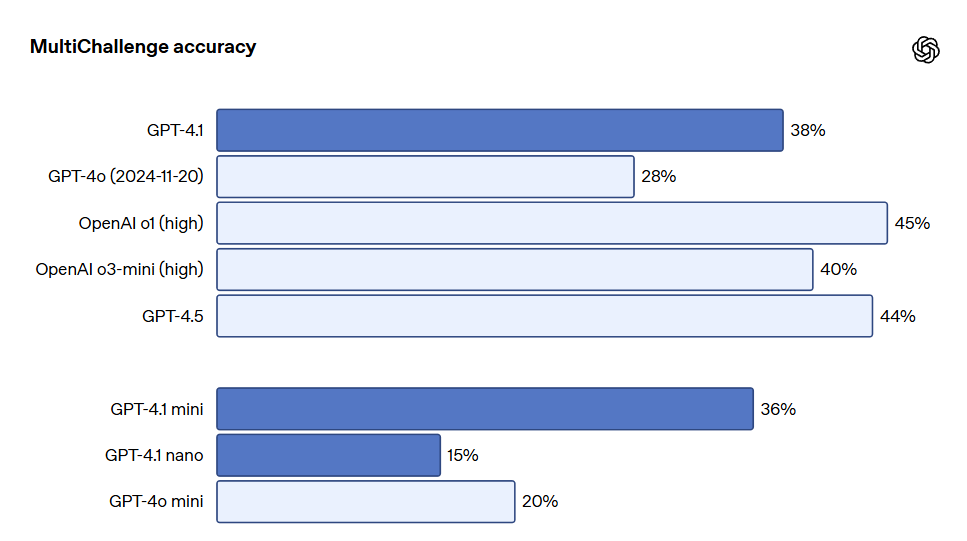
GPT-4.1 は IFEval でも 87.4% のスコアを獲得し、GPT-4o は 81.0% でした。IFEval は特定の内容の長さを指定したり、特定の用語や形式を避けることなど、検証可能な指示を用いたプロンプトを使用します。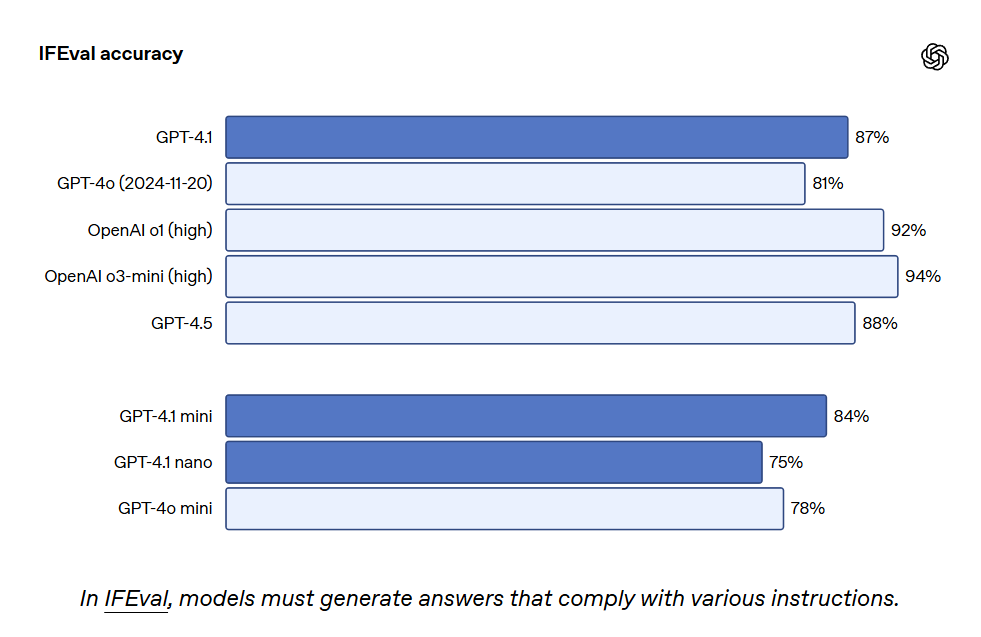
より優れた指示遵守能力は既存のアプリケーションをより信頼性の高いものにし、信頼性の低さが制限となっていた新しいアプリケーションをサポートします。初期のテスターからは、GPT-4.1 がより直感的であるとの指摘があり、OpenAI ではプロンプトをより明確かつ具体的にすることを推奨しています。
GPT-4.1、GPT-4.1 mini、GPT-4.1 nano は最大で 100 万トークンのコンテキストを扱うことができ、従来の GPT-4o モデルは最大で 12.8 万トークンでした。100 万トークンは 8 つの完全な React コードベースに相当し、長期的コンテキストは大規模なコードベースや長文書の処理に非常に適しています。GPT-4.1 は、100 万トークンのコンテキスト長の情報を信頼性高く処理し、関連するテキストを注意深く扱いながら長期的なコンテキストの干渉を無視できる能力があります。長期的コンテキスト理解は、法律、プログラミング、顧客サポートをはじめとする多くの分野でのアプリケーションにとって重要な能力です。
OpenAI は、GPT-4.1 がコンテキストウィンドウ内のさまざまなポイントから隠れた小さな情報(needle)を取得する能力をデモンストレーションしました。GPT-4.1 は、すべての位置やすべてのコンテキスト長の needle を持続的に正確に取得でき、最大 100 万トークンの取得量まで対応可能です。これらのトークンが入力内のどの位置にあっても、GPT-4.1 は現在のタスクに関連する詳細を効果的に抽出できます。しかし、現実の世界には、明らかな「needle」な答えを検出するようなシンプルなタスクはほとんど存在しません。OpenAI は、ユーザーがしばしばモデルに対して複数の情報を取得し、その間の相互関係を理解させる必要があることを発見しました。この能力を示すために、OpenAI は新しい評価である OpenAI-MRCR(多重共参照)をオープンソース化しました。OpenAI-MRCR は、ユーザーとアシスタントの間の多重の合成対話をテストし、ユーザーが「貘についての詩を書いて」や「岩石についてのブログ記事を書いて」などの要求をし、その後コンテキスト内に同じリクエストを 2 回、4 回、8 回挿入し、モデルは特定のインスタンスに対する応答(例:「貘についての 3 番目の詩をください」)を取得しなければなりません。これに挑戦するのは、これらのリクエストがコンテキスト内の他の部分に非常に類似しているため、モデルが貘に関する短編小説ではなく詩を求められていると誤解しやすい点です。OpenAI は、GPT-4.1 が最大 128K トークンのコンテキスト長において GPT-4o よりも優れた結果を示し、最大 100 万トークンの長さにおいても強力なパフォーマンスを維持できることを発見しました。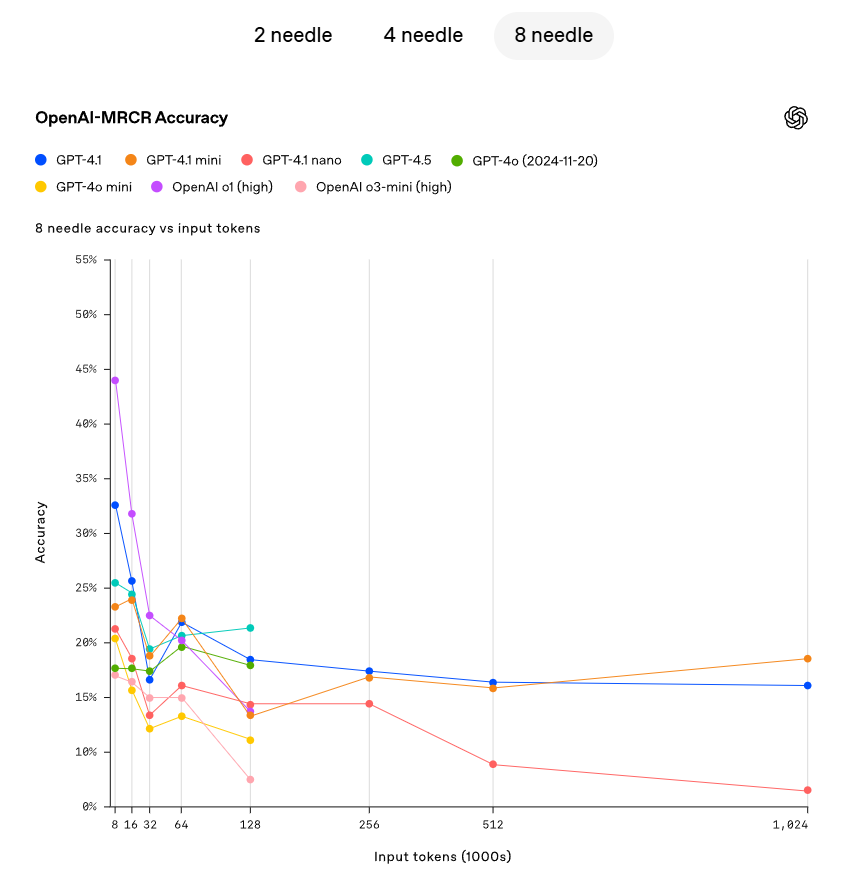
また、OpenAI は長期的コンテキスト推論を評価するためのデータセット Graphwalksも発表しました。多くの開発者が長期的コンテキストユースケースにおいて、複数のファイル間を論理的に飛び越える必要があります。理論的には、モデル(そして人間)も何度もこれらのプロンプトを読んで OpenAI-MRCR の問題を解決できますが、Graphwalks の設計はコンテキスト内の複数の位置で推論することを必要とし、順番に解決することができません。Graphwalks のコンテキストウィンドウは、16進数のハッシュ値で構成された有向グラフで満たされ、モデルはランダムなノードから開始して幅優先探索 (BFS) を実行する必要があります。その後、一定の深さにあるすべてのノードを返す必要があります。結果は、GPT-4.1 がこのベンチマークにおいて 61.7% の精度を達成し、GPT-4o のパフォーマンスと同等であり、GPT-4o を簡単に上回ることが示されました。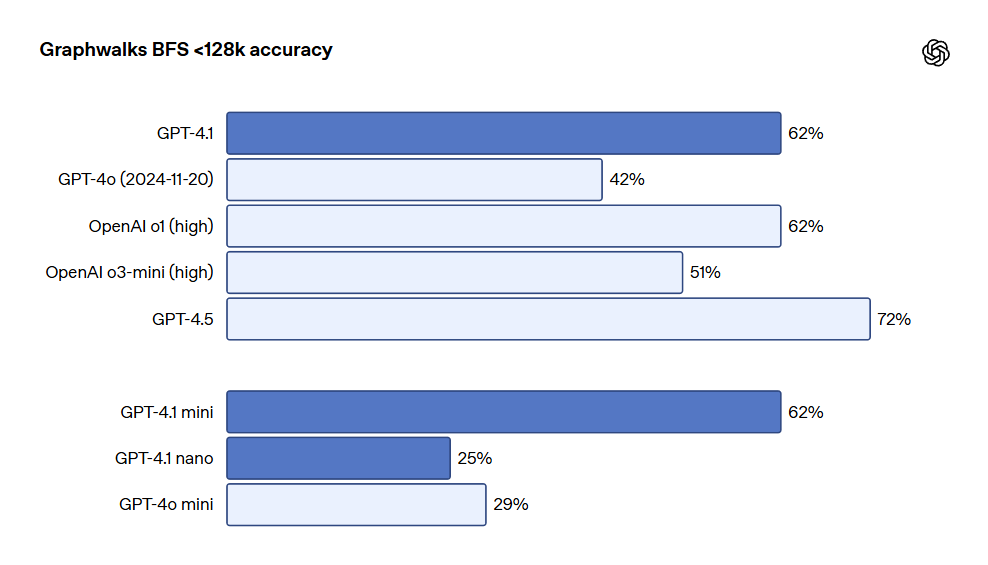
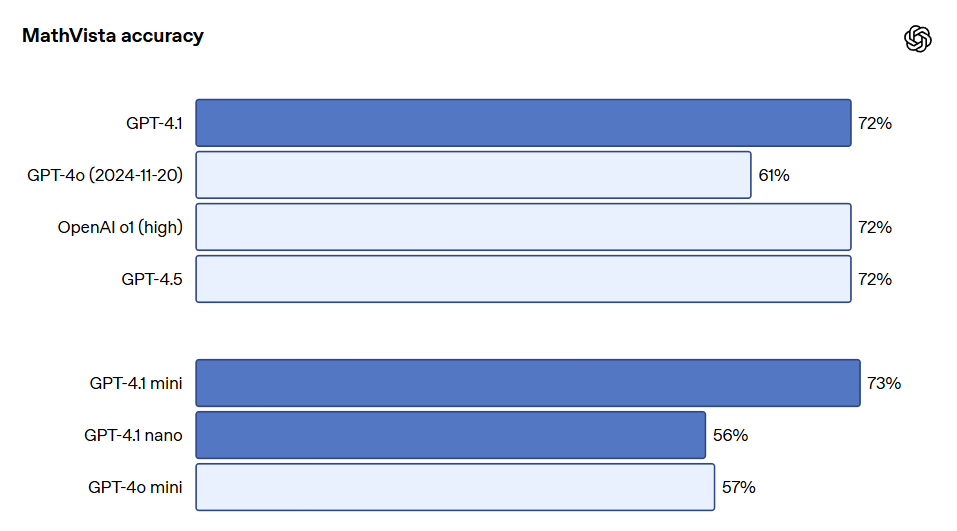
GPT-4.1 シリーズモデルは、特に画像の理解において非常に強力であり、特に GPT-4.1 mini は大きな飛躍を遂げ、画像ベンチマークで頻繁に GPT-4o を上回っています。以下は、MMMU(図表や地図を含む問題への回答)、MathVista(視覚的な数学問題を解決)、CharXiv-Reasoning(科学論文の図表に関する質問への回答)などのベンチマークにおけるパフォーマンス比較です。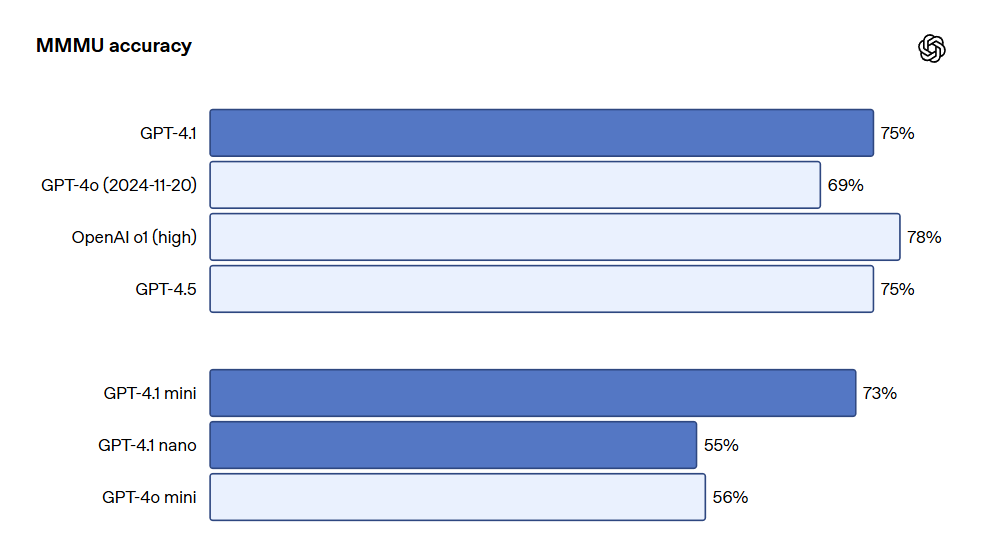
長期的コンテキストの性能は、多モーダルユースケース(例:長いビデオの処理)においても重要です。Video-MME(長い字幕なしのビデオ)において、モデルは 30-60 分の字幕なしビデオに基づいて多肢選択式の質問に回答します。GPT-4.1 は最高のパフォーマンスを達成し、スコアは 72.0%、GPT-4o の 65.3% を上回りました。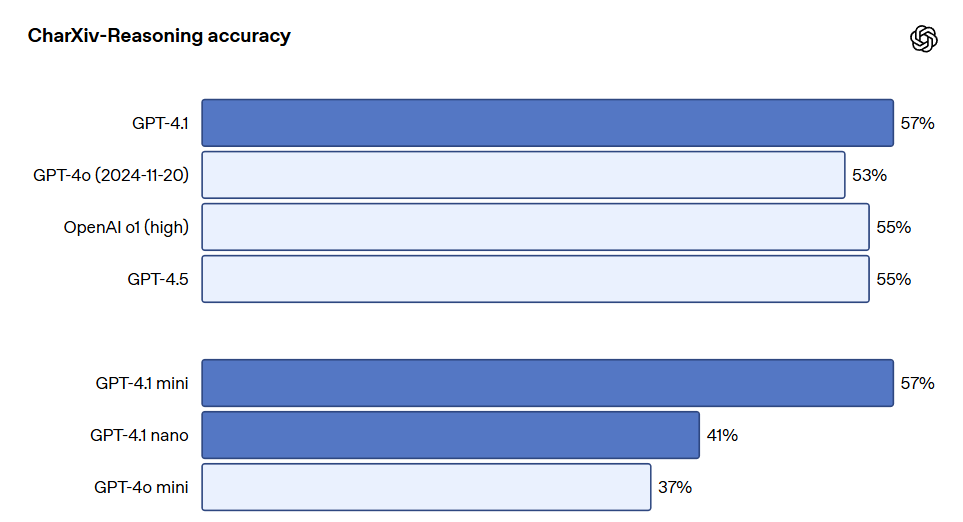
詳しいテスト指標については、OpenAI のブログをご参照ください。ブログアドレス:https://openai.com/index/gpt-4-1/
素晴らしいレビュー


FLUX.1 Kontext: 最強のAI画像生成器で実現する革新的な画像生成と編集
FLUX.1 Kontextモデルは、文脈を考慮した画像生成と編集を実現する画期的なAI技術です。





最高のAI画像生成器: GPT-4oのかわいいフィギュアを作る方法
この記事では、GPT-4oのかわいいフィギュアを生成するための2つのプラットフォームを紹介します。





