Lançamento do GPT-4.1: O Melhor Gerador de Imagens AI
4/16/2025
Hoje de madrugada, a nova série de modelos da OpenAI, o GPT-4.1, foi lançada conforme prometido.  Esta série inclui três modelos: GPT-4.1, GPT-4.1 mini e GPT-4.1 nano, que estão disponíveis apenas através de chamadas de API, liberadas para todos os desenvolvedores. Com este lançamento, a série de modelos oferece um desempenho similar ou superior em muitas funcionalidades-chave, com custos e latências mais baixos, levando a OpenAI a decidir descontinuar a versão beta do GPT-4.5, com um prazo de três meses após o lançamento (14 de julho de 2025), para dar tempo de transição aos desenvolvedores.
Esta série inclui três modelos: GPT-4.1, GPT-4.1 mini e GPT-4.1 nano, que estão disponíveis apenas através de chamadas de API, liberadas para todos os desenvolvedores. Com este lançamento, a série de modelos oferece um desempenho similar ou superior em muitas funcionalidades-chave, com custos e latências mais baixos, levando a OpenAI a decidir descontinuar a versão beta do GPT-4.5, com um prazo de três meses após o lançamento (14 de julho de 2025), para dar tempo de transição aos desenvolvedores.
A OpenAI informou que o desempenho desses três modelos supera amplamente o do GPT-4o e GPT-4o mini, com melhorias significativas em programação e obediência a instruções. Eles também apresentam uma janela de contexto maior — suportando até 1 milhão de tokens de contexto — e conseguem fazer um melhor uso desse contexto por meio de uma compreensão aprimorada de longos contextos. A data limite de conhecimento foi atualizada até junho de 2024. No geral, o GPT-4.1 se destacou em vários indicadores de referência da indústria:
- Programação: O GPT-4.1 teve uma pontuação de 54.6% no teste SWE-bench Verified, aumentando 21.4% em relação ao GPT-4o e 26.6% em relação ao GPT-4.5, tornando-se o modelo de programação líder.
- Obediência a Instruções: No benchmark MultiChallenge da Scale (indicador de obediência a instruções), o GPT-4.1 obteve uma pontuação de 38.3%, superando o GPT-4o em 10.5%.
- Longo Contexto: No benchmark de compreensão de longo contexto multimodal, Video-MME, o GPT-4.1 estabeleceu um novo recorde, alcançando 72.0% na avaliação de vídeo longo sem legendas, uma melhoria de 6.7% em relação ao GPT-4o.
Embora os resultados dos benchmarks sejam muito bons, a OpenAI focou na utilidade prática dos modelos durante o treinamento. Por meio de uma colaboração próxima com a comunidade de desenvolvedores, a OpenAI otimizou esses modelos para as tarefas mais relevantes para aplicações. Como resultado, a série de modelos GPT-4.1 oferece um desempenho excepcional a um custo mais baixo. Esses modelos mostram melhorias em cada ponto da curva de latência. 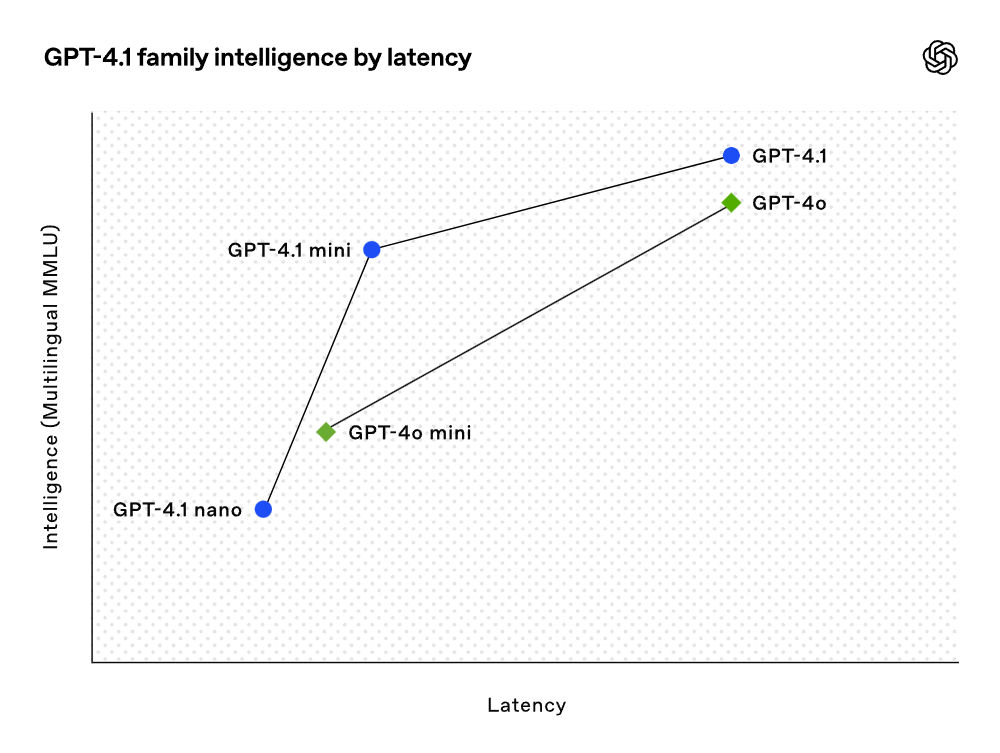
O GPT-4.1 mini apresenta um salto significativo no desempenho de modelos pequenos, superando o GPT-4o em várias avaliações de benchmark. Este modelo iguala ou supera o GPT-4o na avaliação de inteligência, enquanto reduz a latência em quase metade e o custo em 83%. Para tarefas que exigem baixa latência, o GPT-4.1 nano é o modelo mais rápido e acessível da OpenAI até agora. Com uma janela de contexto de 1 milhão de tokens, ele ainda oferece desempenho excepcional em escalas menores, com pontuações de 80.1% no teste MMLU, 50.3% no GPQA e 9.8% no teste de codificação multilíngue Aider, superando até o GPT-4o mini. Este modelo é uma escolha ideal para tarefas como classificação ou preenchimento automático. As melhorias na confiabilidade da obediência a instruções e na compreensão de longo contexto tornam o modelo GPT-4.1 mais eficiente para dirigir agentes inteligentes (ou seja, sistemas que podem completar tarefas de forma independente para os usuários). Combinando com primitivos como a API de Respostas, os desenvolvedores agora podem construir agentes mais úteis e confiáveis em engenharia de software real, extraindo insights de documentos extensos com a menor intervenção manual possível e executando outras tarefas complexas. Simultaneamente, ao melhorar a eficiência do sistema de raciocínio, a OpenAI conseguiu reduzir os preços da série GPT-4.1. O custo das consultas de tamanho médio do GPT-4.1 é 26% menor do que o do GPT-4o, enquanto o GPT-4.1 nano é o modelo mais barato e rápido já lançado pela OpenAI. Para consultas que requerem a repetição do mesmo contexto, a OpenAI elevou o desconto de cache instantâneo da nova série de modelos de 50% para 75%. Além disso, além do custo padrão por token, a OpenAI agora também oferece solicitações de longo contexto sem custo adicional. 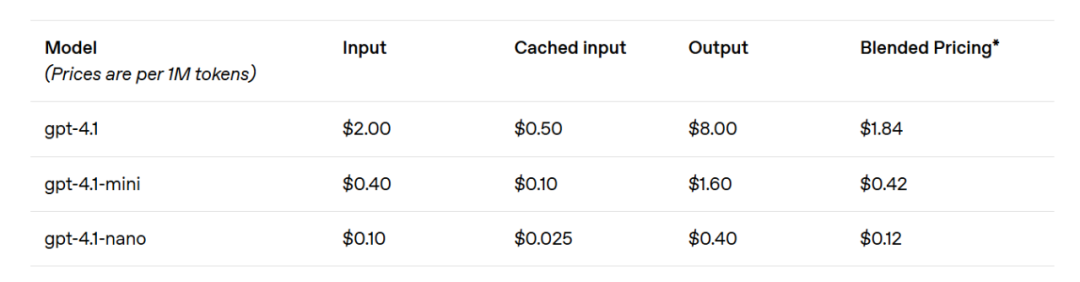
O CEO da OpenAI, Sam Altman, afirmou que o GPT-4.1 não apenas apresenta resultados de benchmark excepcionais, mas também foca na utilidade prática no mundo real, algo que deve deixar os desenvolvedores satisfeitos. 
Parece que a OpenAI alcançou uma melhora significativa em suas capacidades de modelo com "4.10﹥4.5". 
Na programação, o GPT-4.1 supera o GPT-4o em várias tarefas de codificação, incluindo resolução de tarefas por agentes, programação front-end, redução de edições irrelevantes, obediência consistente a formatos de diff, e garantia de consistência no uso de ferramentas. No teste SWE-bench Verified, que mede habilidades de engenharia de software no mundo real, o GPT-4.1 completou 54.6% das tarefas, em comparação com 33.2% do GPT-4o (2024-11-20). Isso reflete melhorias na capacidade do modelo de explorar bibliotecas de código, completar tarefas e gerar código executável que passe nos testes. 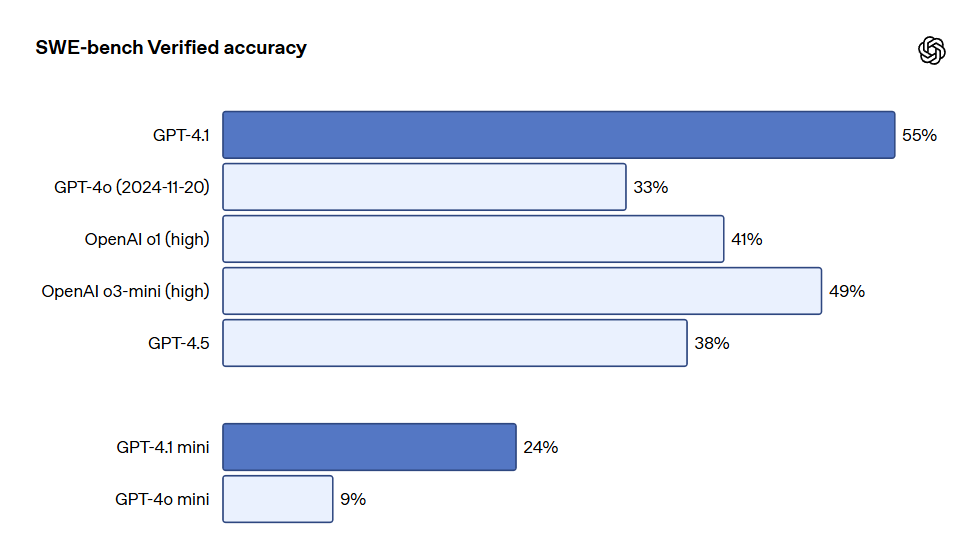
Para desenvolvedores de API que precisam editar arquivos grandes, o GPT-4.1 é mais confiável ao lidar com diffs de código em vários formatos. No benchmark de diferenças multilíngues da Aider, o GPT-4.1 obteve pontuação mais de duas vezes superior à do GPT-4o, além de ser 8% superior ao GPT-4.5. Essa avaliação mede tanto a capacidade de codificação em várias linguagens de programação quanto a habilidade do modelo de gerar mudanças em formatos geral e diff. A OpenAI treinou especificamente o GPT-4.1 para seguir formatos de diff de forma mais confiável, permitindo que os desenvolvedores apenas especifiquem as linhas que mudaram, sem necessidade de reescrever o arquivo inteiro, economizando custo e latência. Além disso, para desenvolvedores que preferem reescrever todo o arquivo, a OpenAI aumentou o limite de tokens de saída do GPT-4.1 para 32.768 tokens (acima dos 16.384 tokens do GPT-4o). A OpenAI também sugere o uso de previsões para reduzir a latência em reescritas de arquivos completos. 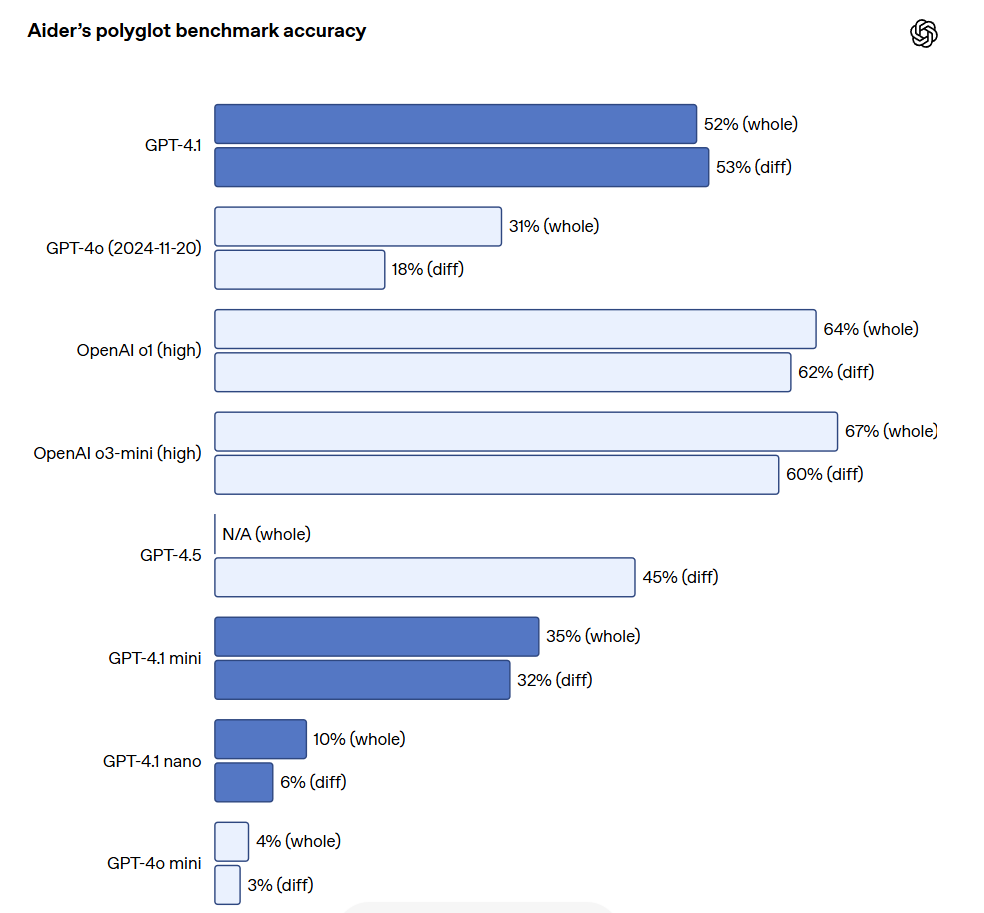
O GPT-4.1 também apresentou melhorias significativas em programação front-end, sendo capaz de criar aplicações web mais poderosas e estéticas. Em comparações diretas, 80% dos avaliadores pagos demonstraram que os sites gerados pelo GPT-4.1 eram mais populares do que os do GPT-4o. 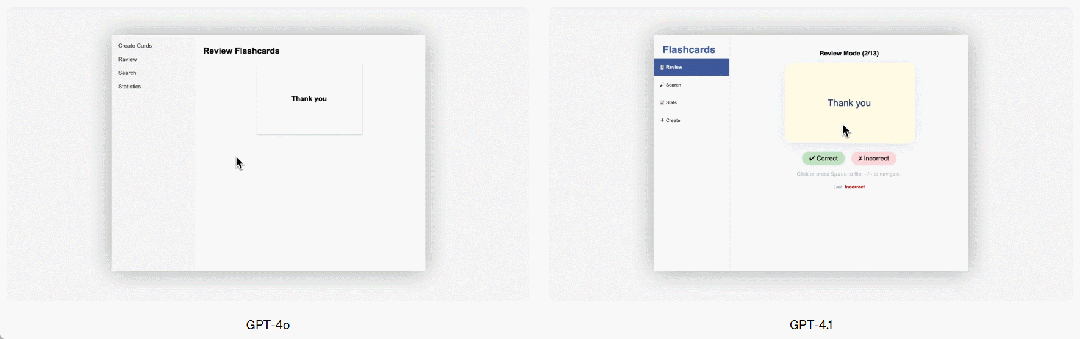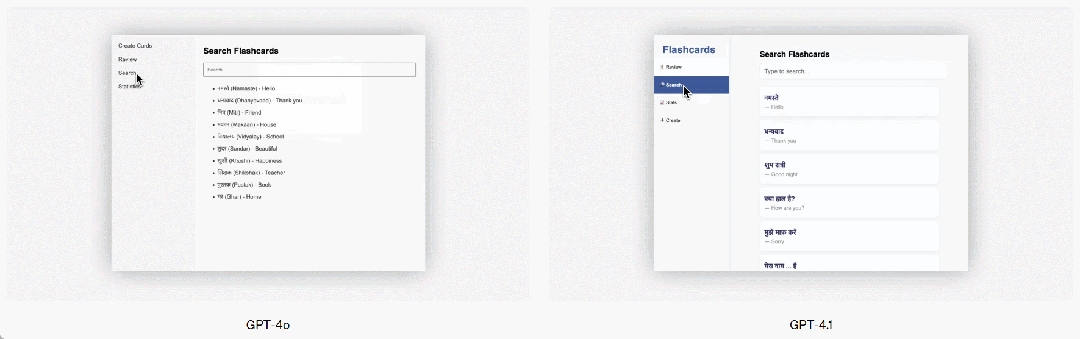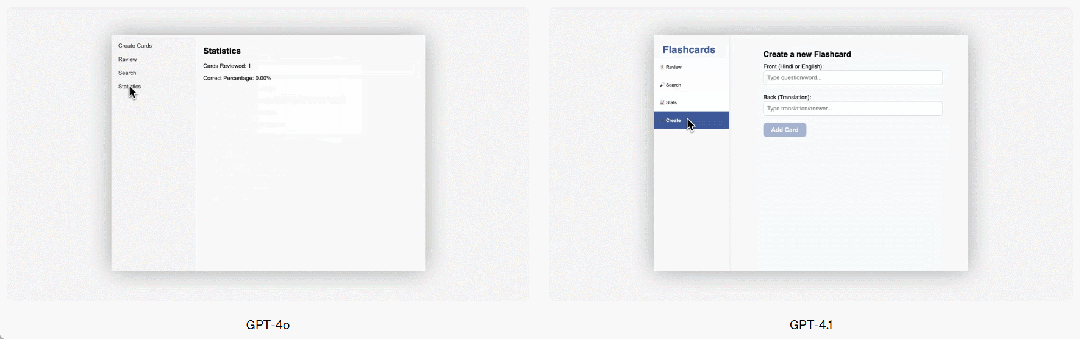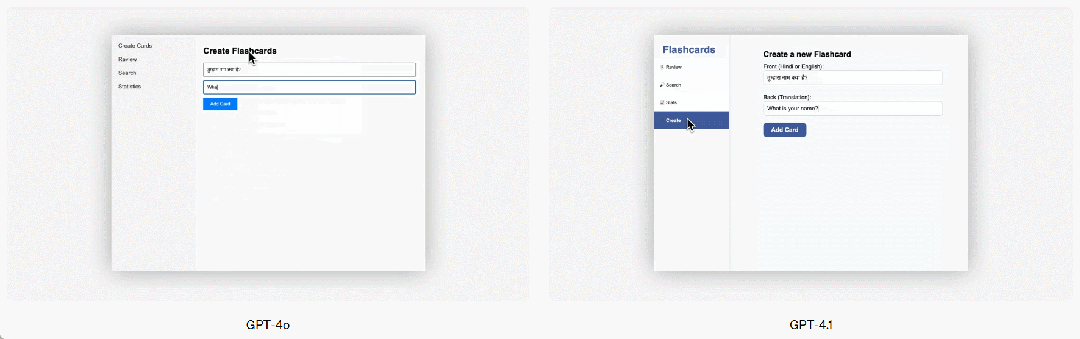
Além dos benchmarks mencionados, o GPT-4.1 também se destacou em seguir formatos, com maior confiabilidade e redução na frequência de edições irrelevantes. Em uma avaliação interna da OpenAI, a quantidade de edições irrelevantes no código diminuiu de 9% no GPT-4o para 2% no GPT-4.1.
Obediência a Instruções
O GPT-4.1 demonstrou ser mais confiável ao seguir instruções, alcançando melhorias significativas em várias avaliações de obediência. A OpenAI desenvolveu um sistema interno de avaliação de obediência, que rastreia o desempenho do modelo em múltiplas dimensões e categorias de execução de instruções-chave, incluindo: seguir formatos. Fornecer instruções que especifiquem o formato de resposta da modelo, como XML, YAML, Markdown, etc. instruções negativas. Especificar comportamentos a serem evitados, como "não peça ao usuário para entrar em contato com o suporte". instruções ordenadas. Fornecer um conjunto de instruções que o modelo deve seguir em uma ordem específica, como "primeiro pergunte o nome do usuário, depois pergunte o endereço de e-mail". requisitos de conteúdo. Produzir conteúdo que contenha informações específicas, como "ao redigir um plano nutricional, não se esqueça de incluir a quantidade de proteína". ordenação. Ordenar a saída de uma forma específica, como "classificar a resposta por população". confiança excessiva. Incentivar o modelo a responder "não sei" ou algo semelhante quando a informação solicitada não está disponível ou o pedido não se enquadra na categoria dada, como "se você não souber a resposta, forneça um e-mail de contato do suporte". Essas categorias foram desenvolvidas com base no feedback dos desenvolvedores, mostrando quais instruções eram mais relevantes e importantes para eles. Dentro de cada categoria, a OpenAI as classificou em solicitações simples, medianas e desafiadoras. O GPT-4.1 se destacou especialmente em solicitações desafiadoras. 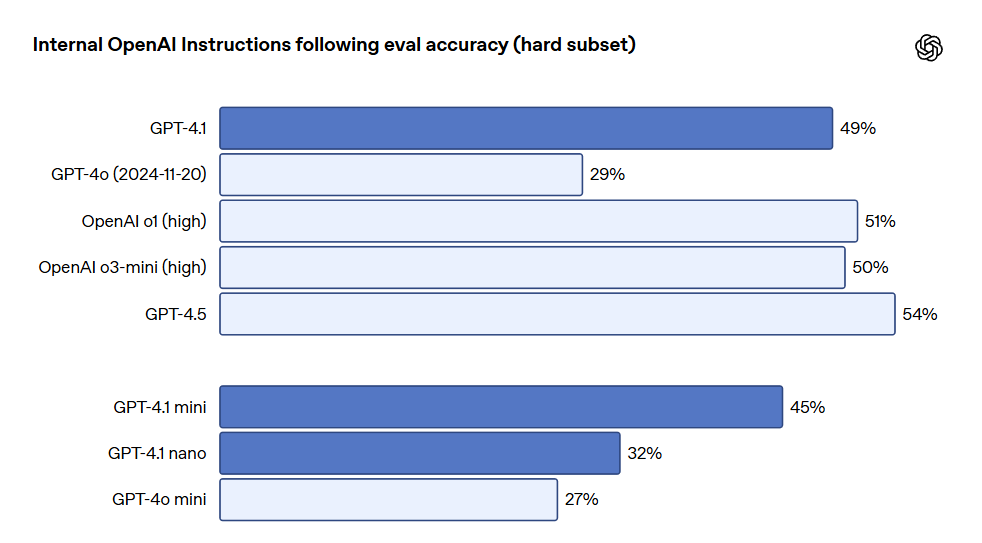
A obediência a instruções em múltiplas etapas é crucial para muitos desenvolvedores. Para o modelo, é importante manter a coerência em um diálogo e acompanhar o que o usuário inseriu anteriormente. O GPT-4.1 se saiu melhor ao identificar informações em mensagens passadas de diálogos, permitindo conversas mais naturais. O benchmark MultiChallenge da Scale é um indicador eficaz dessa capacidade, com o GPT-4.1 superando o GPT-4o em 10.5%. 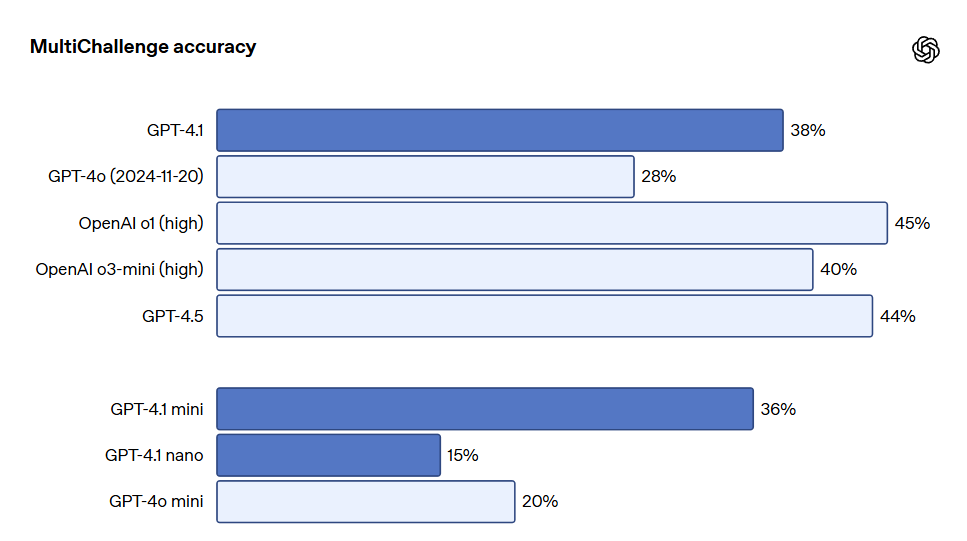
O GPT-4.1 também alcançou 87.4% no IFEval, enquanto o GPT-4o obteve 81.0%. O IFEval utiliza prompts com instruções verificáveis, como especificar o comprimento do conteúdo ou evitar o uso de certos termos ou formatos. 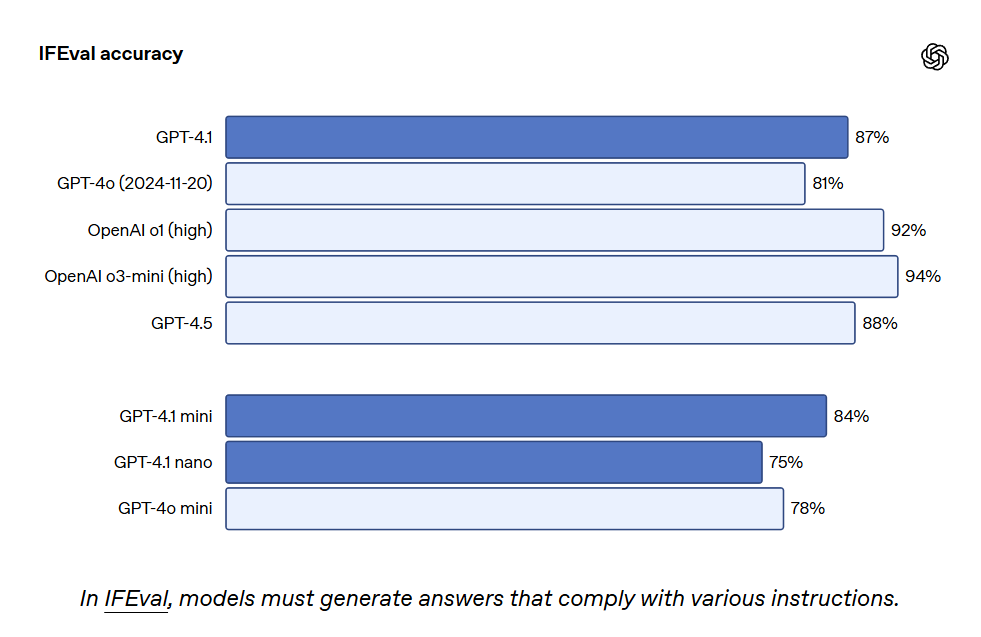
Melhores habilidades de obediência a instruções tornam os aplicativos existentes mais confiáveis e ajudam a facilitar o desenvolvimento de novos aplicativos que antes eram limitados pela baixa confiabilidade. Testadores iniciais notaram que o GPT-4.1 pode ser mais intuitivo; portanto, a OpenAI recomenda ser mais claro e específico nas solicitações.
Longo Contexto
O GPT-4.1, GPT-4.1 mini e GPT-4.1 nano podem processar até 1 milhão de tokens de contexto, enquanto o anterior GPT-4o lidava com no máximo 128 mil. 1 milhão de tokens equivalem a 8 repositórios de código React completos, tornando o longo contexto ideal para trabalhar com grandes bibliotecas de código ou documentos extensos. O GPT-4.1 consegue lidar de maneira confiável com a informação de 1 milhão de tokens de comprimento, sendo mais eficaz em notar textos relevantes e ignorar interferências de contexto longo e curto do que o GPT-4o. A compreensão do longo contexto é uma habilidade chave em aplicações jurídicas, programação, suporte ao cliente e muitas outras áreas. 
A OpenAI demonstrou a capacidade do GPT-4.1 de recuperar pequenas informações ocultas (agulhas) localizadas em diferentes pontos dentro da janela de contexto. O GPT-4.1 consegue continuamente extrair com precisão pequenas informações em todos os locais e comprimentos de contexto, recuperando até 1 milhão de tokens. Não importa onde esses tokens estejam em uma entrada, o GPT-4.1 pode efetivamente extrair detalhes relevantes para a tarefa atual. No entanto, na vida real, é raro que uma tarefa seja tão simples quanto encontrar a resposta para uma pergunta óbvia como encontrar uma "agulha". A OpenAI descobriu que os usuários frequentemente precisavam que o modelo recuperasse e compreendesse várias informações, além de entender as interconexões entre esses dados. Para demonstrar essa capacidade, a OpenAI lançou uma nova avaliação: OpenAI-MRCR (Recuperação Conjunta de Múltiplas Rodadas). O OpenAI-MRCR testa a capacidade do modelo de identificar e eliminar múltiplas "agulhas" ocultas no contexto. A avaliação envolve diálogos sintéticos entre usuário e assistente, com o usuário solicitando ao assistente que escreva um artigo sobre um determinado tema, como "escreva um poema sobre um tapiro" ou "escreva um artigo de blog sobre rochas", com inserções de duas, quatro ou oito solicitações iguais ao longo do contexto; então o modelo deve recuperar a resposta associada a instâncias específicas (por exemplo, "me dê o terceiro poema sobre um tapiro"). O desafio se concentra na semelhança das solicitações com o restante do contexto, onde o modelo pode ser facilmente levado a erro por pequenas variações, como uma história curta sobre um tapiro em vez de um poema ou um poema sobre uma rã ao invés de um tapiro. A OpenAI observou que o GPT-4.1 teve um desempenho superior ao GPT-4o em contextos com até 128K tokens e manteve um forte desempenho mesmo com longitudes de até 1 milhão de tokens. 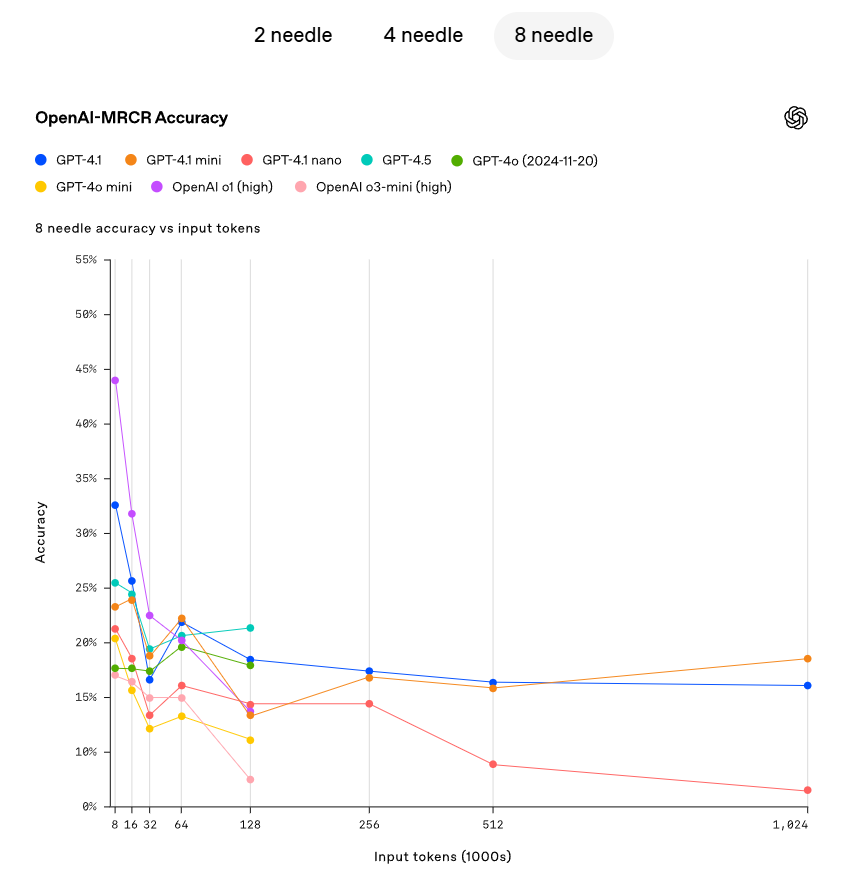
A OpenAI também lançou o Graphwalks, um conjunto de dados para avaliar o raciocínio de longo contexto com múltiplos saltos. Muitos desenvolvedores precisam realizar múltiplos saltos lógicos no contexto para casos de uso de longo contexto, como saltar entre vários arquivos ao escrever código ou referenciar documentos ao responder questões legais complexas. Teoricamente, um modelo (ou mesmo um ser humano) pode resolver questões de OpenAI-MRCR por meio de leituras repetidas das instruções, mas o Graphwalks foi projetado para exigir raciocínio em múltiplos pontos dentro do contexto e não pode ser resolvido sequencialmente. O Graphwalks preenche a janela de contexto com um gráfico orientado formado por valores hash hexadecimais e, em seguida, pede ao modelo para realizar uma busca em largura (BFS) começando em um nó aleatório do gráfico. Em seguida, ele deve retornar todos os nós até uma certa profundidade. Os resultados mostraram que o GPT-4.1 alcançou 61.7% de precisão nesse benchmark, comparable ao desempenho do GPT-4o, e facilmente superou o GPT-4o. 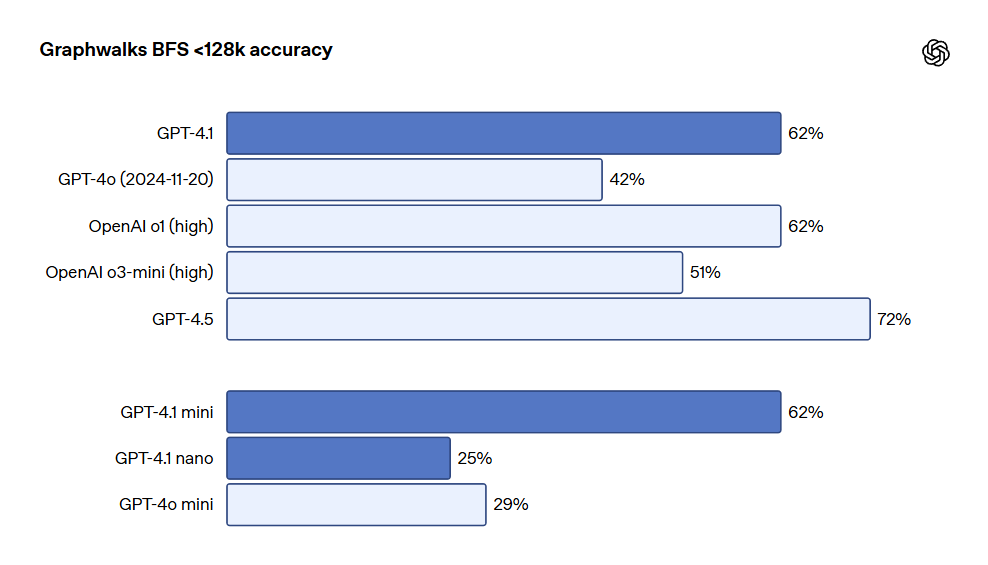
Visual
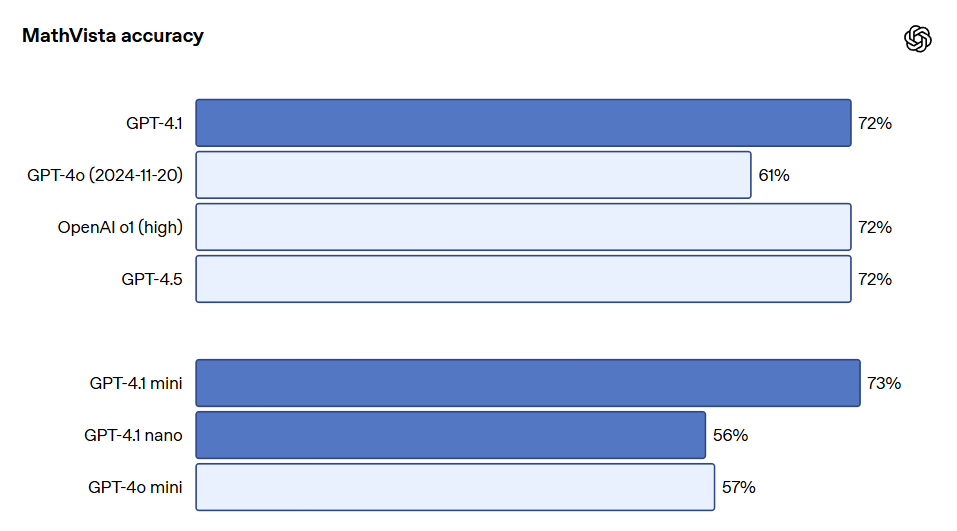
Os modelos da série GPT-4.1 também se destacam na compreensão de imagens, especialmente o GPT-4.1 mini, que alcançou uma grande evolução, frequentemente superando o GPT-4o em benchmarks de imagem. Abaixo estão comparações de desempenho em benchmarks como MMMU (responder perguntas que incluem gráficos, diagramas, mapas, etc.), MathVista (resolver problemas matemáticos visuais) e CharXiv-Reasoning (responder questões sobre gráficos em artigos científicos). 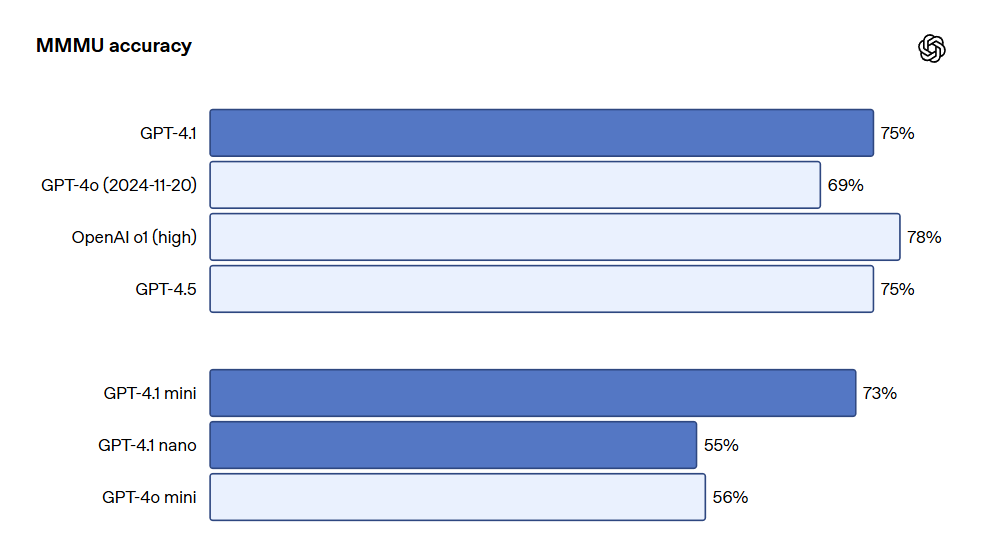
O desempenho em contextos longos é também crucial para casos de uso multimodal (como a manipulação de longos vídeos). No Video-MME (vídeo longo sem legendas), o modelo responde perguntas de múltipla escolha com base em vídeos sem legendas com duração de 30 a 60 minutos. O GPT-4.1 superou o desempenho anterior, alcançando uma pontuação de 72.0%, acima dos 65.3% do GPT-4o. 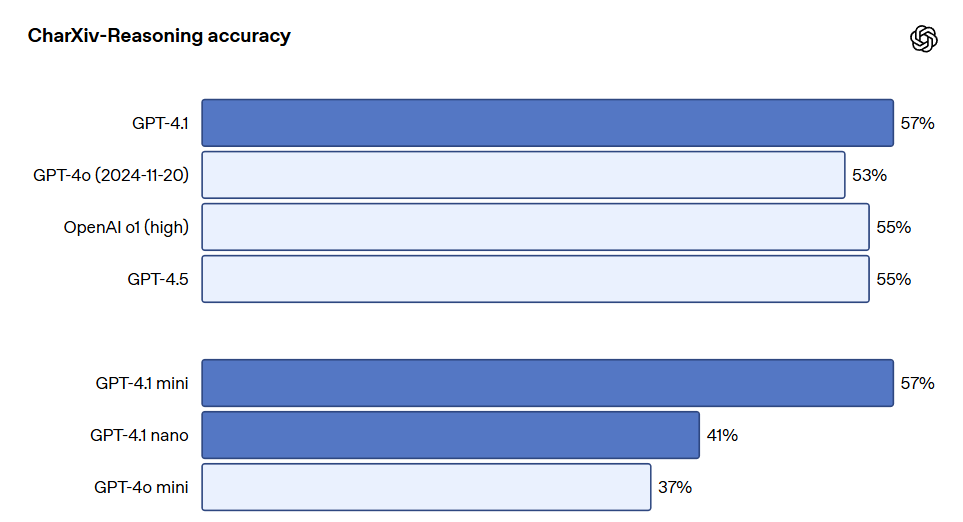
Para mais métricas de teste, consulte o blog original da OpenAI. O endereço do blog é: OpenAI Blog
Nossas Avaliações Incríveis

FLUX Kontext: O Melhor Gerador de Imagens AI para Edição e Personalização
FLUX Kontext é um modelo poderoso para edição de imagens, permitindo modificações detalhadas e criação de novos conteúdos visuais com facilidade.

FLUX.1 Kontext: O Melhor Gerador de Imagens AI com Geração e Edição de Contexto
A FLUX.1 Kontext é uma inovadora solução de geração e edição de imagens AI que marca um avanço significativo na criação de imagens contextuais.

Qwen3: O Melhor Gerador de Imagens AI com Desempenho Impressionante
Explore o Qwen3, um modelo poderoso de IA com uma performance impressionante, disponível para implementação em hardware comum.

Vidu Q1: O Melhor Gerador de Vídeo AI para Criar Conteúdos Impressionantes
O Vidu Q1 é o mais recente modelo de geração de vídeo AI, permitindo a criação automática de vídeos de alta qualidade a partir de descrições de texto ou imagens.

O Melhor Gerador de Imagens AI: Descubra Como Criar Imagens Incríveis com GPT-4o
Aprenda a criar imagens realistas usando o novo modelo GPT-4o com dicas e truques práticos.

O Melhor Gerador de Imagem AI: Criação de Estilo Ghibli com Liblib AI
Descubra como criar imagens estilizadas como as de Ghibli usando Liblib AI e DeepSeek.

Os Melhores Geradores de Imagens AI: Raphael AI e MiaoHua
Explore ferramentas gratuitas de geração de imagens AI, Raphael AI e MiaoHua, que oferecem qualidade impressionante sem custo.

CatPony: O Melhor Gerador de Imagens AI de Estilo Realista
Uma análise do modelo de imagem realista CatPony, destacando suas características únicas e qualidade.

Melhores Geradores de Imagens AI: Conheça os Modelos de Bonecos GPT-4o
Descubra dois plataformas para criar bonecos fofos usando GPT-4o, além de um guia passo a passo para personalizar suas figuras.

Gerador de Imagens AI: FLUX e Nunchaku - O Melhor Gerador de Imagens AI
Descubra como a tecnologia Nunchaku está transformando o FLUX em uma ferramenta de produtividade para geração de imagens AI.

Lançamento do GPT-4.1: O Melhor Gerador de Imagens AI
Neste artigo, discutimos o lançamento do GPT-4.1 da OpenAI, que inclui novos modelos e melhorias significativas em desempenho e custo.

Revolução na Edição de Fotos com AIEASE: O Melhor Gerador de Imagens de IA
Descubra como o AIEASE transforma suas fotos em segundos com ferramentas de edição de imagem baseadas em IA.

Modelo Grande de Estilo Especial para Animais e Humanos: O Melhor Gerador de Imagens AI
Este artigo apresenta um modelo grande de estilo especial que combina animais e humanos, analisando suas representações artísticas.