Le Meilleur Générateur d'Images IA : OpenAI Lance GPT-4.1 avec des Nouvelles Améliorations
4/16/2025
Le matin de ce jour, OpenAI a lancé comme prévu sa nouvelle série de modèles GPT-4.1 !  Cette série comprend trois modèles : GPT-4.1, GPT-4.1 mini et GPT-4.1 nano, accessibles uniquement par API et désormais ouverts à tous les développeurs. Avec ces modèles offrant des performances similaires ou supérieures dans de nombreuses fonctionnalités clés, ainsi qu'une réduction des coûts et des délais, OpenAI commencera à déprécier la version bêta de GPT-4.5 dans l'API. La période de dépréciation s’étendra sur trois mois (jusqu'au 14 juillet 2025), permettant ainsi une transition en douceur pour les développeurs. OpenAI affirme que les performances de ces trois modèles surpassent largement celles de GPT-4o et GPT-4o mini, avec des améliorations significatives en matière de programmation et de respect des instructions. Ils disposent également d'une plus grande fenêtre contextuelle, prenant en charge jusqu'à 1 million de tokens contextuels, permettant une meilleure utilisation de ces contextes grâce à une compréhension améliorée des longs contextes. La date limite des connaissances a été mise à jour au 30 juin 2024. En somme, GPT-4.1 se distingue dans les indicateurs standard de l'industrie suivants :
Cette série comprend trois modèles : GPT-4.1, GPT-4.1 mini et GPT-4.1 nano, accessibles uniquement par API et désormais ouverts à tous les développeurs. Avec ces modèles offrant des performances similaires ou supérieures dans de nombreuses fonctionnalités clés, ainsi qu'une réduction des coûts et des délais, OpenAI commencera à déprécier la version bêta de GPT-4.5 dans l'API. La période de dépréciation s’étendra sur trois mois (jusqu'au 14 juillet 2025), permettant ainsi une transition en douceur pour les développeurs. OpenAI affirme que les performances de ces trois modèles surpassent largement celles de GPT-4o et GPT-4o mini, avec des améliorations significatives en matière de programmation et de respect des instructions. Ils disposent également d'une plus grande fenêtre contextuelle, prenant en charge jusqu'à 1 million de tokens contextuels, permettant une meilleure utilisation de ces contextes grâce à une compréhension améliorée des longs contextes. La date limite des connaissances a été mise à jour au 30 juin 2024. En somme, GPT-4.1 se distingue dans les indicateurs standard de l'industrie suivants :
- Programmation : GPT-4.1 a obtenu un score de 54,6% dans le test SWE-bench Verified, soit une amélioration de 21,4% par rapport à GPT-4o et de 26,6% par rapport à GPT-4.5, en faisant le modèle de programmation leader.
- Respect des instructions : dans le benchmark MultiChallenge de Scale, qui mesure la capacité de suivre les instructions, GPT-4.1 a obtenu un score de 38,3%, soit une amélioration de 10,5% par rapport à GPT-4o.
- Long contexte : dans le benchmark de compréhension de long contexte multimodal Video-MME, GPT-4.1 a établi un nouveau record avec un score de 72,0% dans le test sans sous-titres de longue durée, une amélioration de 6,7% par rapport à GPT-4o.
Bien que les résultats des tests soient impressionnants, OpenAI a mis l'accent sur l'utilité réelle lors de la formation de ces modèles. Grâce à une collaboration étroite avec la communauté des développeurs, OpenAI a optimisé ces modèles pour les tâches les plus pertinentes pour les applications des développeurs. Dans cette optique, la série de modèles GPT-4.1 offre des performances remarquables à coût réduit. Ces modèles ont réalisé des gains de performance à chaque point de la courbe de latence. 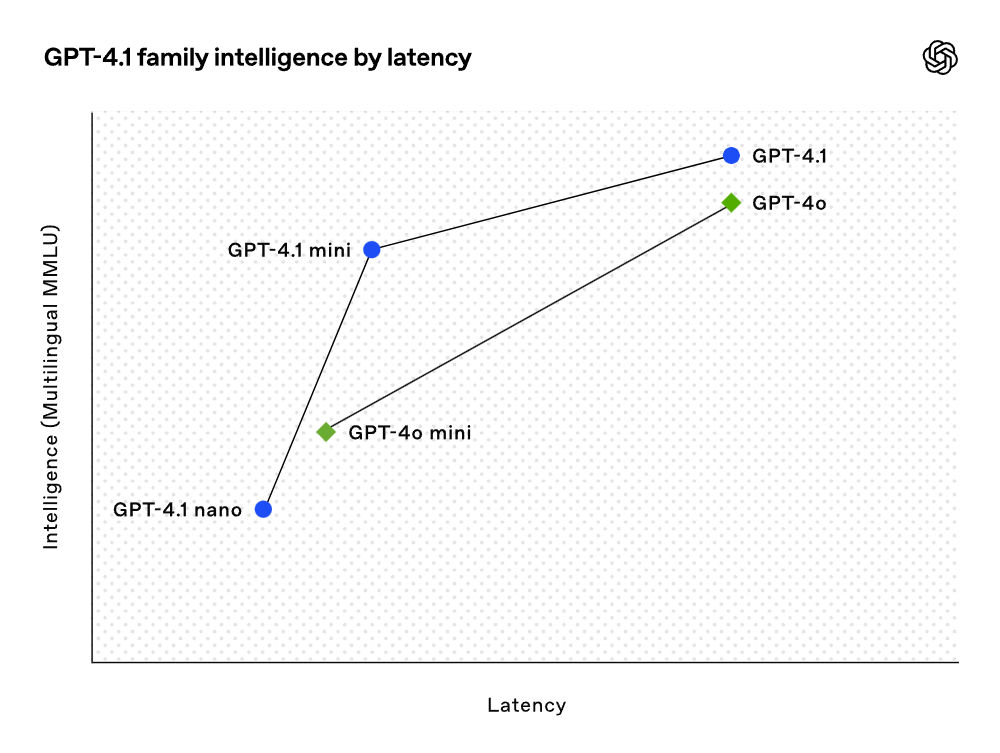
Le modèle GPT-4.1 mini a réalisé un bond significatif en termes de performance pour les modèles de petite taille, surpassant même GPT-4o dans plusieurs benchmarks. Ce modèle a des performances d'évaluation intelligentes équivalentes, voire supérieures, à celles de GPT-4o, tout en réduisant la latence de près de moitié et les coûts de 83%. Pour les tâches nécessitant une faible latence, GPT-4.1 nano est actuellement le modèle le plus rapide et le moins cher d'OpenAI. Ce modèle a une fenêtre contextuelle de 1 million de tokens et offre des performances excellentes même à petite échelle, obtient un score de 80,1% dans le test MMLU, de 50,3% dans le test GPQA et de 9,8% dans le test de codage multilingue Aider, surpassant même GPT-4o mini. Ce modèle est idéal pour les tâches telles que la classification ou l'auto-complétion. Les améliorations en matière de fiabilité des instructions et de compréhension de longs contextes rendent également le modèle GPT-4.1 plus efficace dans la conduite d'agents intelligents (c'est-à-dire des systèmes capables d'effectuer des tâches indépendamment pour le compte de l'utilisateur). En combinant cela avec des primitives telles que l'API Responses, les développeurs peuvent désormais construire des agents plus utiles et fiables dans l'ingénierie logicielle réelle, extrayant des insights de documents volumineux, répondant aux demandes clients avec un minimum d'interventions manuelles, et exécutant d'autres tâches complexes. En même temps, en améliorant l'efficacité du système de raisonnement, OpenAI a pu réduire les prix de la série GPT-4.1. Le coût des requêtes de taille moyenne de GPT-4.1 est 26% inférieur à celui de GPT-4o, tandis que GPT-4.1 nano est le modèle le moins cher et le plus rapide d'OpenAI à ce jour. Pour les requêtes répétées nécessitant le même contexte, OpenAI a porté la remise sur le cache instantané des nouveaux modèles de 50% à 75%. De plus, au-delà du coût par token standard, OpenAI propose des requêtes de long contexte sans frais supplémentaires. 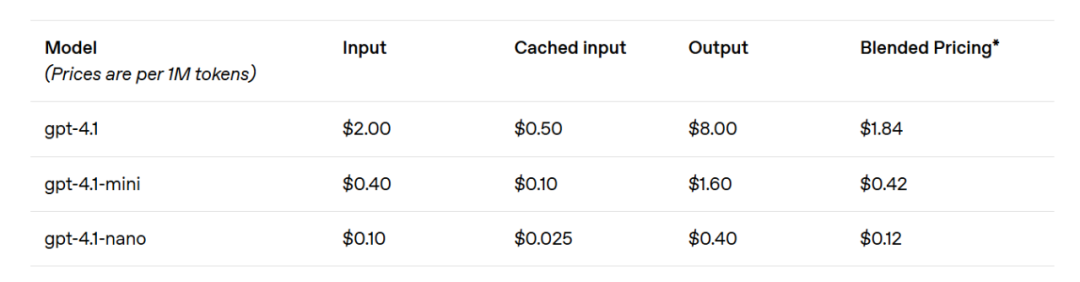
Le PDG d'OpenAI, Sam Altman, a déclaré que GPT-4.1 non seulement a d'excellents résultats dans les benchmarks mais se concentre également sur l'utilité pratique dans le monde réel, ce qui devrait réjouir les développeurs. 
Il semble qu'OpenAI ait réalisé des avancées significatives dans les capacités de ses modèles, sur la base de leur progression « 4.10 > 4.5 ». 
Dans le domaine de la programmation, GPT-4.1 surpasse largement GPT-4o dans diverses tâches de codage, y compris la résolution de tâches de codage par des agents, la programmation frontale, la réduction de l'édition non pertinente, la fiabilité du respect du format diff et l'assurance de la cohérence de l'utilisation des outils. Dans le test SWE-bench Verified, qui évalue les compétences en génie logiciel dans le monde réel, GPT-4.1 a réussi 54,6% des tâches contre 33,2% pour GPT-4o (mise à jour du 20 novembre 2024). Cela reflète l'amélioration des capacités du modèle en matière d'exploration des bases de code, de finalisation des tâches, et de génération de code exécutable et testé. 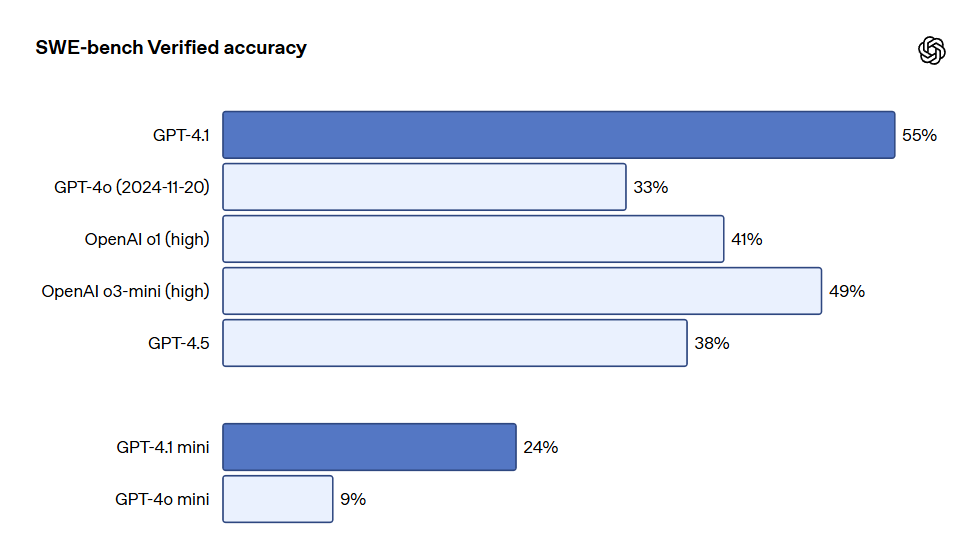
Pour les développeurs d'API ayant besoin d'éditer de grands fichiers, GPT-4.1 montre une plus grande fiabilité dans le traitement des diffs de code de divers formats. Dans le benchmark de différence multilingue d'Aider, le score de GPT-4.1 était plus du double de celui de GPT-4o et même 8% supérieur à celui de GPT-4.5. Cette évaluation mesure non seulement la capacité de coder à travers plusieurs langages, mais aussi celle du modèle à générer des modifications dans les formats global et diff. OpenAI a spécifiquement entraîné GPT-4.1 pour qu'il suive de manière plus fiable le format diff, de sorte que les développeurs n'ont qu'à sortir les lignes modifiées sans avoir à réécrire tout le fichier, ce qui permet d'économiser coûts et latence. De plus, pour les développeurs préférant réécrire l'ensemble du fichier, OpenAI a augmenté la limite de tokens de sortie de GPT-4.1 à 32 768 tokens (contre 16 384 tokens pour GPT-4o). OpenAI recommande également d'utiliser la sortie prédictive pour réduire la latence lors de la réécriture complète de fichiers. 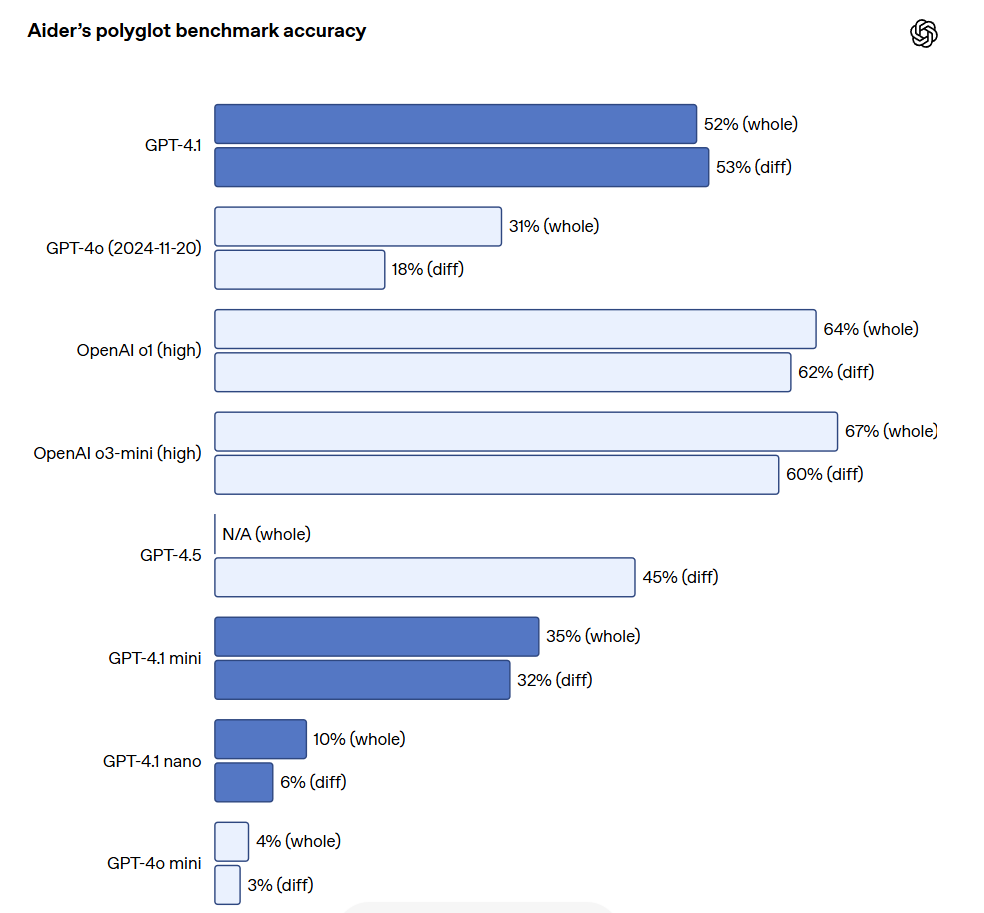
GPT-4.1 a également fait des progrès significatifs dans la programmation frontale, capable de créer des applications Web plus puissantes et plus esthétiques. Dans les comparaisons tête-à-tête, 80% des résultats des évaluateurs humains payés montrent que les sites Web créés par GPT-4.1 sont plus attrayants que ceux de GPT-4o. 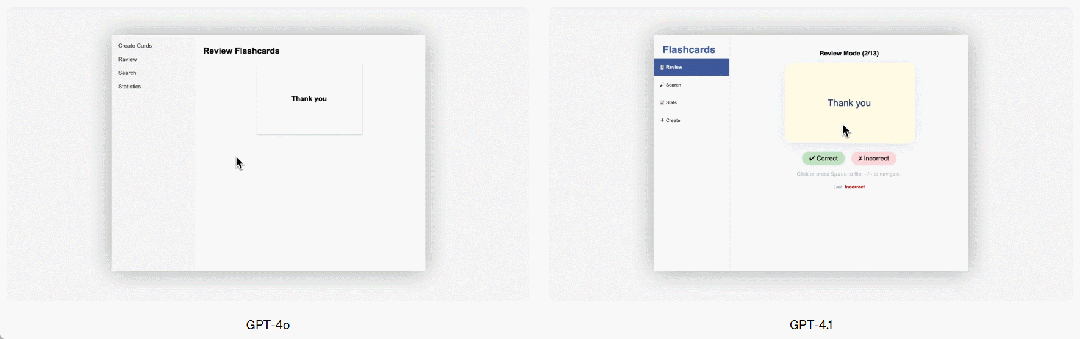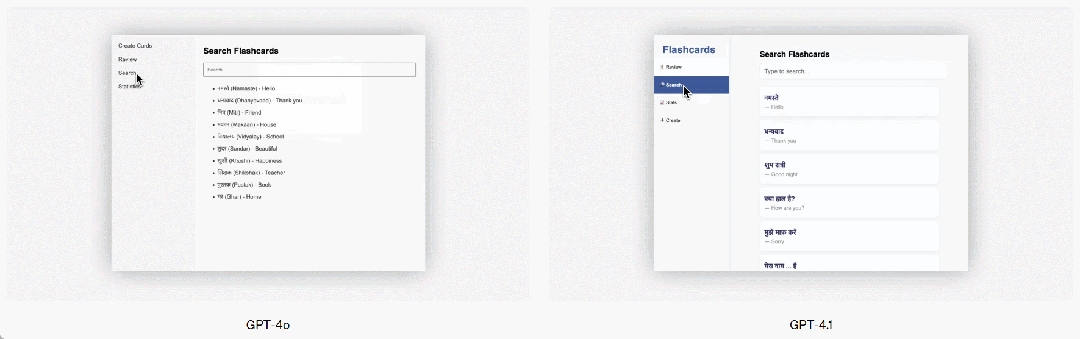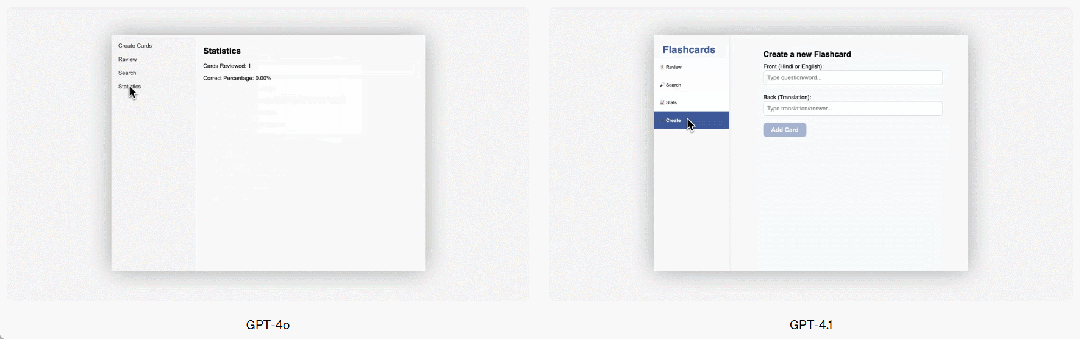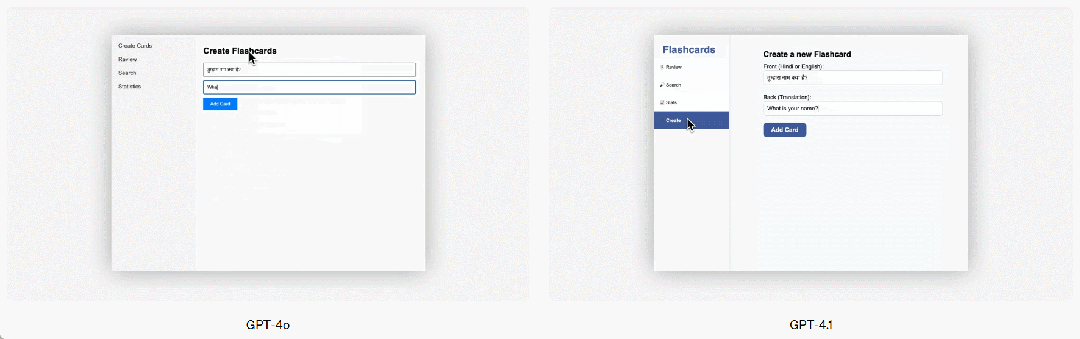
En dehors des benchmarks mentionnés, GPT-4.1 a également montré de meilleures performances de respect des formats, une fiabilité accrue et a réduit la fréquence des éditions non pertinentes. Dans une évaluation interne d'OpenAI, les éditions non pertinentes dans le code ont diminué de 9% pour GPT-4o à 2% pour GPT-4.1. Respect des instructions, GPT-4.1 peut suivre les instructions de manière plus fiable, ayant réalisé des améliorations significatives dans divers évaluations de respect des instructions. OpenAI a développé un système d'évaluation interne pour suivre les performances des modèles sur plusieurs dimensions et plusieurs catégories clés d'exécution des instructions, y compris : respect du format, instructions à fournir, instructions négatives, instructions ordonnées, exigences de contenu, ordre de sortie et excès de confiance. Ces catégories ont été définies en fonction des retours des développeurs, indiquant les instructions les plus pertinentes et importantes pour eux. Dans chaque catégorie, OpenAI les a classées en prompts simples, moyens et difficiles. GPT-4.1 a particulièrement excellé sur les prompts difficiles. 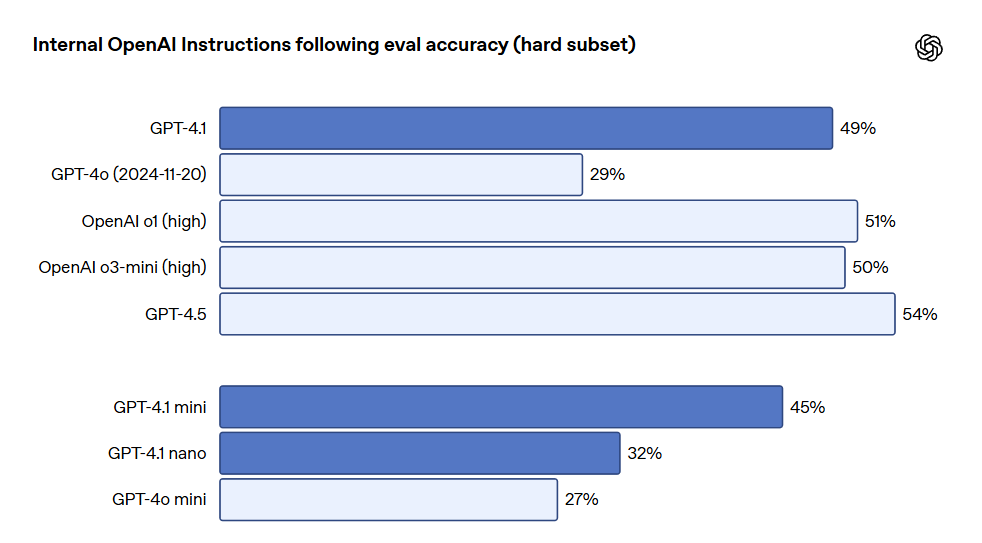
Le respect des instructions multiround est essentiel pour de nombreux développeurs. Pour un modèle, il est crucial de maintenir une cohérence dans une conversation et de suivre ce que l'utilisateur a précédemment entré. GPT-4.1 est capable de mieux reconnaître les informations issue des messages passés dans une conversation, permettant ainsi de mener des dialogues plus naturels. Le benchmark MultiChallenge de Scale est un indicateur efficace pour mesurer cette capacité, et les performances de GPT-4.1 sont supérieures de 10,5% à celles de GPT-4o. 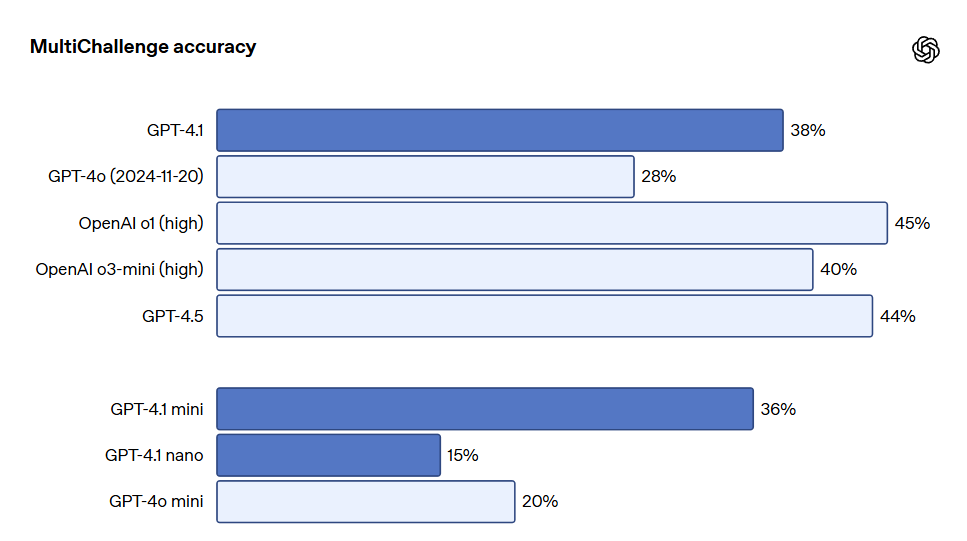
GPT-4.1 a également obtenu un score de 87,4% sur IFEval, tandis que GPT-4o a obtenu 81,0%. IFEval utilise des invites avec des instructions vérifiables, telles que la spécification de la longueur du contenu ou l'évitement de certains termes ou formats. 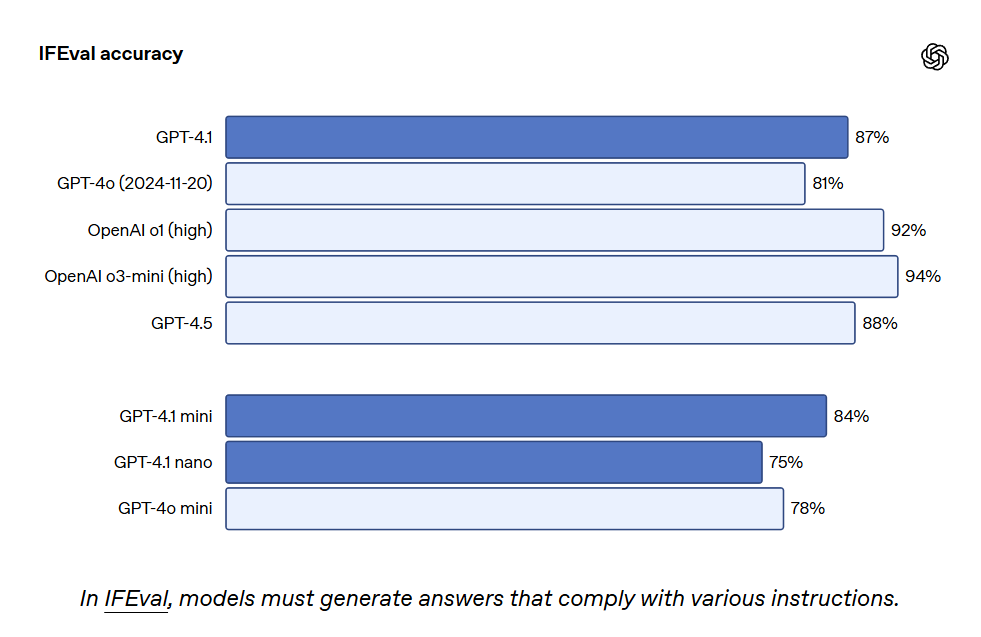
Une meilleure capacité de respect des instructions rend les applications existantes plus fiables et prend en charge de nouvelles applications qui auparavant étaient limitées par un faible niveau de fiabilité. Les premiers testeurs ont souligné que GPT-4.1 est plus intuitif, c’est pourquoi OpenAI recommande d’être plus clair et spécifique dans les invites. Long contexte, GPT-4.1, GPT-4.1 mini et GPT-4.1 nano peuvent gérer jusqu'à 1 million de tokens contextuels, tandis que le modèle GPT-4o précédent ne pouvait en gérer que 128 000. Un million de tokens équivaut à 8 bibliothèques de code React complètes, donc un long contexte est particulièrement adapté pour traiter de grandes bases de code ou de nombreux longs documents. GPT-4.1 traite de manière fiable des informations avec une longueur contextuelle de 1 million de tokens, étant plus fiable que GPT-4o dans l'attention aux textes pertinents tout en ignorant les distractions des longs et courts contextes. La compréhension des longs contextes est une capacité clé dans les applications juridiques, de programmation, de support client, et de nombreux autres domaines. 
OpenAI a démontré la capacité de GPT-4.1 à suivre et récupérer des informations cachées (aiguille) à divers endroits dans la fenêtre contextuelle. GPT-4.1 peut de manière continue et précise retrouver des aiguilles à toutes les positions et à toutes les longueurs contextuelles, avec une récupération maximale atteignant 1 million de tokens. Quelle que soit la position de ces tokens dans l'entrée, GPT-4.1 peut efficacement extraire les détails pertinents pour la tâche en cours. Cependant, dans le monde réel, peu de tâches sont aussi simples que de récupérer une réponse évidente comme une aiguille. OpenAI a découvert que les utilisateurs ont souvent besoin que le modèle récupère et comprenne plusieurs informations, et qu'il comprenne les interrelations entre ces informations. Pour illustrer cette capacité, OpenAI a open-sourcé une nouvelle évaluation : OpenAI-MRCR (co-référence multiple). OpenAI-MRCR teste la capacité d'un modèle à identifier et éliminer les多个的"针"445的能力,性能中的“针”的位置,而不是只跟随其中的某一个。“针”的位置可能会影响众多应用程序,从大型软件的开发到复杂的法律问题的解答。OpenAI发现,当GPT-4.1的上下文长度达到128K个tokens时,其表现优于GPT-4o,并且即使在长度高达1百万tokens时,仍然保持了良好的性能。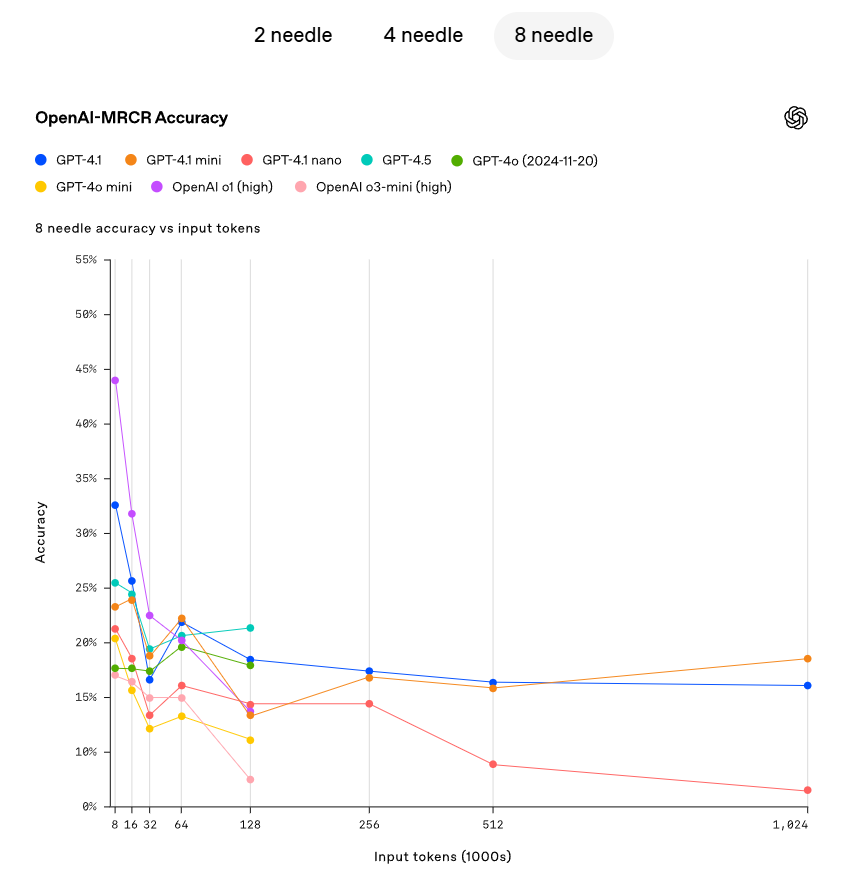
OpenAI还发布了Graphwalks,这是一个用于评估多跳长上下文推理的数据集。许多开发者在长上下文用例中需要在上下文中进行多个逻辑跳跃,例如在编写代码时在多个文件之间跳转,或在回答复杂的法律问题时交叉引用文档。理论上,模型(甚至人类)可以通过反复阅读提示词来解决OpenAI-MRCR问题,但Graphwalks的设计要求在上下文中的多个位置进行推理,并且无法按顺序求解。Graphwalks会用由十六进制哈希值组成的有向图填充上下文窗口,然后要求模型从图中的随机节点开始执行广度优先搜索(BFS)。然后要求它返回一定深度的所有节点。结果显示,GPT-4.1在此基准测试中达到了61.7%的准确率,与o1的性能相当,并轻松击败了GPT-4o。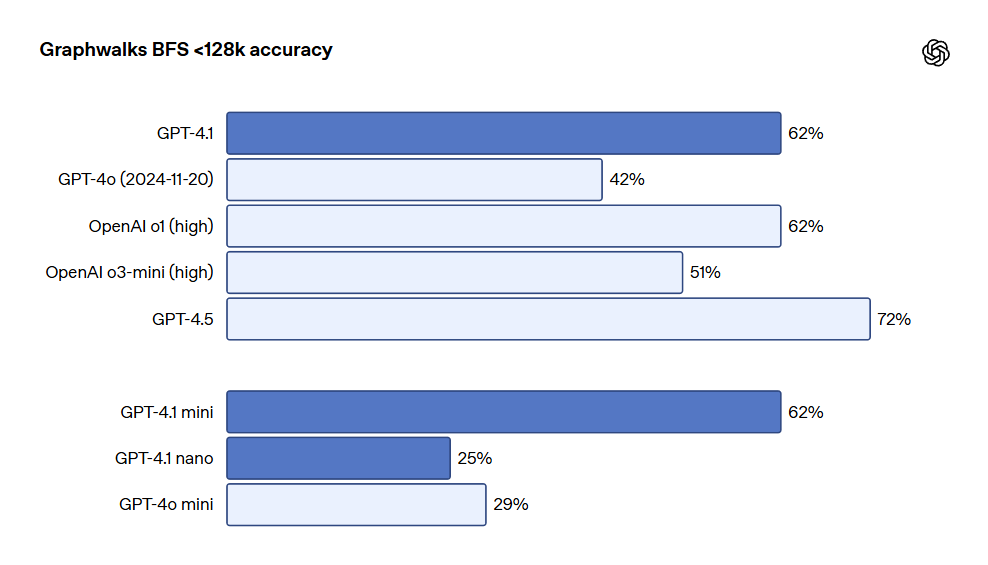
在视觉方面,GPT-4.1系列模型在图像理解方面同样表现出色,特别是GPT-4.1 mini在图像基准测试中表现出色,经常击败GPT-4o。以下是MMMU(回答包含图表、图解、地图等的问题)、MathVista(解决视觉数学问题)、CharXiv-Reasoning(回答科学论文中关于图表的问题)等基准上的表现对比。 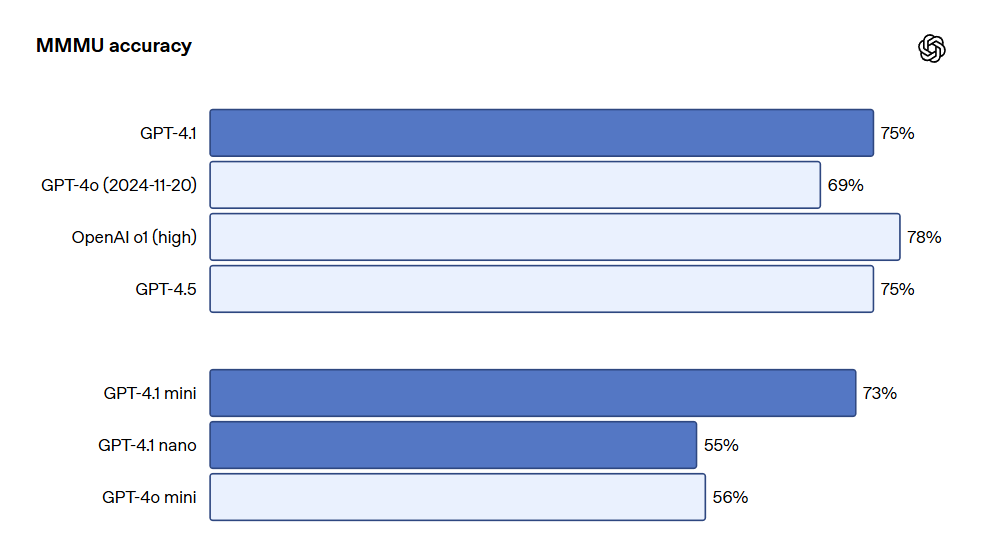
长上下文性能对于多模态用例(例如处理长视频)也至关重要。在Video-MME(长视频无字幕)中,模型基于30-60分钟长的无字幕视频回答多项选择题。GPT-4.1达到了最佳性能,得分为72.0%,高于GPT-4o的65.3%。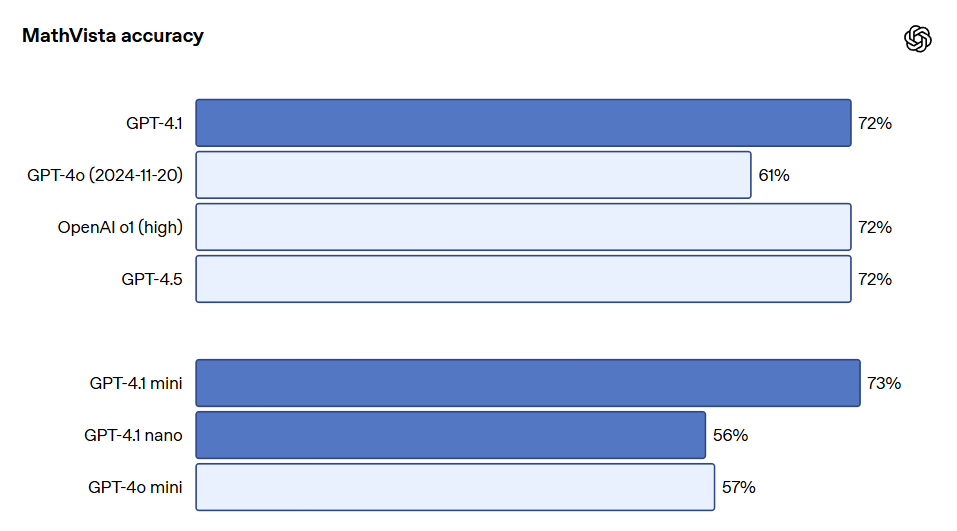
更多测试指标请参考OpenAI原博客。博客地址:https://openai.com/index/gpt-4-1/ © 结束
Nos Avis Exceptionnels

FLUX Kontext : Le Meilleur Générateur d'Images AI pour Éditer et Créer des Visuels
Découvrez le modèle génératif FLUX Kontext qui révolutionne la retouche photo en conservant l'intégrité des éléments non modifiés.

Découvrez FLUX.1 Kontext : le meilleur générateur d'images AI du marché
FLUX.1 Kontext est un modèle révolutionnaire de génération et d'édition d'images basé sur une architecture de flux génératif qui permet une manipulation créative incroyable.

Le Meilleur Générateur d'Images AI : Qwen3 Redéfinit la Performance
Découvrez comment le modèle Qwen3 ouvre de nouvelles possibilités en matière de génération d'images AI, avec des performances impressionnantes.

Meilleur Générateur d'Images IA : Découvrez HiDream et ses Innovations
HiDream, un modèle de génération d'images AI, émerge rapidement comme un leader dans le domaine avec des fonctionnalités innovantes et une qualité d'image impressionnante.

Vidu Q1 : Le meilleur générateur d'images AI pour des vidéos de qualité professionnelle
Découvrez les capacités avancées de Vidu Q1, le dernier modèle de génération vidéo AI qui révolutionne la création de contenus.

Générateur d'images AI : Le Meilleur Générateur d'Images AI en 2025
Découvrez comment GPT-4o révolutionne la génération d'images AI avec des instructions simples.

Le Meilleur Générateur d'Images AI : Créez des Œuvres dans le Style de Ghibli
Découvrez comment créer facilement des images dans le style de Ghibli grâce à Liblib AI et DeepSeek.

Les Meilleurs Générateurs d'Images AI Gratuits : Test de Raphael AI et Secao
Une revue des outils gratuits de génération d'images AI : Raphael AI et Secao.

Découvrez CatPony : le Meilleur Générateur d'Images AI de Style Pony
Un modèle Pony exceptionnel qui allie réalisme et esthétique.

Meilleur Générateur d'Image IA : Créez vos Figurines Chéries avec GPT-4o
Découvrez deux plateformes pour créer des figurines adorables avec GPT-4o.

Meilleur Générateur d'Images AI : Accélérez votre Flux avec Nunchaku
Découvrez le modèle Nunchaku pour une génération d'images AI ultra-rapide et de haute qualité.

Le Meilleur Générateur d'Images IA : OpenAI Lance GPT-4.1 avec des Nouvelles Améliorations
OpenAI a dévoilé sa nouvelle série de modèles GPT-4.1, offrant des performances supérieures et des coûts réduits pour les développeurs.

AIEASE : Le Meilleur Générateur d'Images IA pour Transformer vos Photos en 3 Secondes !
Découvrez AIEASE, un outil révolutionnaire d'édition de photos IA qui transforme vos images en un éclair.

Meilleur générateur d'images AI : style unique d'animaux et d'humains
Explorez des modèles d'images fascinants combinant des caractéristiques animales et humaines.