Lanzamiento de GPT-4.1 por OpenAI: El Mejor Generador de Imágenes AI
4/16/2025
Hoy por la mañana, OpenAI ha lanzado su nueva serie de modelos GPT-4.1. 
Esta serie incluye tres modelos: GPT-4.1, GPT-4.1 mini y GPT-4.1 nano, todos accesibles a través de llamadas API y disponibles para todos los desarrolladores. Con el desempeño en varias funcionalidades clave similar o superior y a un menor costo y latencia, OpenAI comenzará a descontinuar la versión preliminar de GPT-4.5 en tres meses (14 de julio de 2025) para permitir la transición a los desarrolladores. OpenAI ha indicado que el rendimiento de estos tres modelos supera ampliamente al de GPT-4o y GPT-4o mini, con mejoras significativas en programación y cumplimiento de instrucciones. Además, cuentan con una mayor ventana de contexto, soportando hasta 1 millón de tokens de contexto, y pueden aprovechar mejor esta capacidad a través de una comprensión mejorada del largo contexto. La fecha límite de conocimiento se ha actualizado hasta junio de 2024. En términos generales, GPT-4.1 se ha destacado en los siguientes indicadores estándar de la industria:
Programación: GPT-4.1 obtuvo un puntaje de 54.6% en el test SWE-bench Verified, con un incremento del 21.4% respecto a GPT-4o y 26.6% respecto a GPT-4.5, posicionándose como el modelo de programación líder.
Cumplimiento de instrucciones: En la prueba de referencia MultiChallenge de Scale, que mide la capacidad de cumplimiento de instrucciones, GPT-4.1 obtuvo un puntaje de 38.3%, superando a GPT-4o por un 10.5%.
Largo contexto: En la evaluación Multi-Media MME, GPT-4.1 estableció un nuevo récord con un puntaje de 72.0% en pruebas de texto largo sin subtítulos, superior al 6.7% de GPT-4o.
Aunque los resultados de las pruebas son impresionantes, OpenAI ha priorizado la utilidad práctica al entrenar estos modelos. A través de una estrecha colaboración con la comunidad de desarrolladores y asociaciones, OpenAI ha optimizado estos modelos para las tareas más relevantes para los desarrolladores. Como resultado, la serie de modelos GPT-4.1 ofrece un rendimiento excepcional a un costo más bajo. Estos modelos han mejorado su rendimiento en cada punto de la curva de latencia. 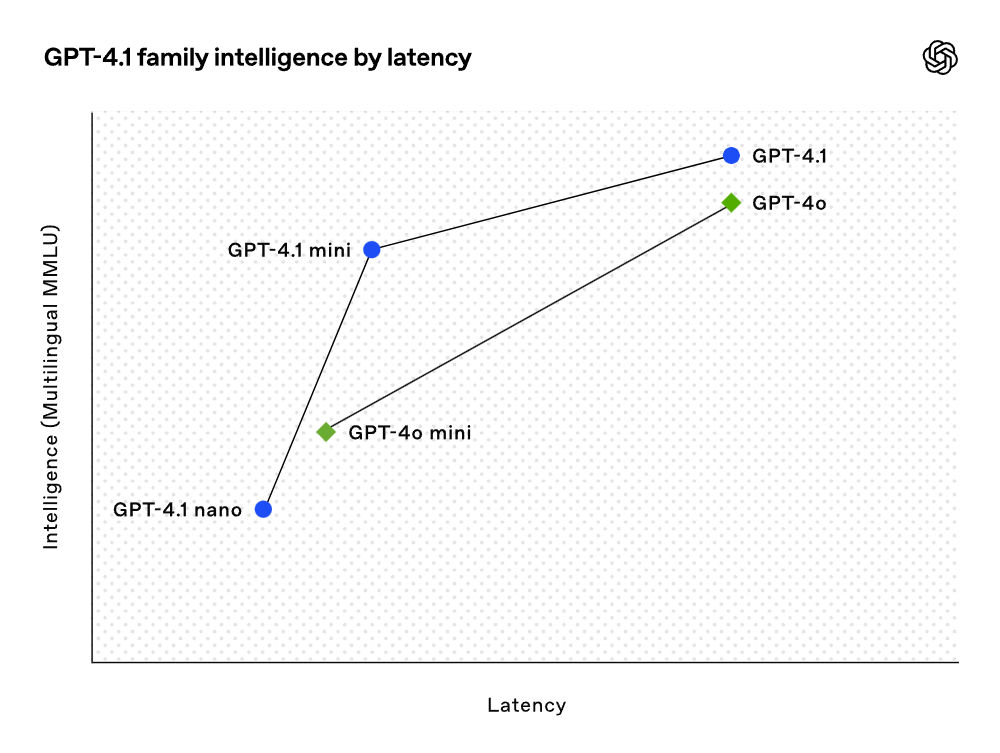
El modelo GPT-4.1 mini ha logrado un avance significativo en el rendimiento de modelos pequeños, superando incluso a GPT-4o en varias pruebas de referencia. Este modelo es comparable a GPT-4o en evaluaciones inteligentes y ha reducido la latencia casi a la mitad, con costos disminuidos en un 83%. Para tareas que requieren baja latencia, GPT-4.1 nano es el modelo de OpenAI más rápido y económico hasta la fecha. Este modelo cuenta con una ventana de contexto de 1 millón de tokens, manteniendo un rendimiento excepcional incluso a escalas menores, obteniendo un puntaje de 80.1% en pruebas MMLU, 50.3% en pruebas GPQA y 9.8% en pruebas de codificación multilingüe Aider, superando a GPT-4o mini. Este modelo es ideal para tareas como clasificación o autocompletado. Las mejoras en confiabilidad de seguimiento de instrucciones y comprensión de largo contexto también hacen que el modelo GPT-4.1 sea más eficiente para impulsar agentes inteligentes (sistemas que pueden completar tareas de manera independiente en nombre de los usuarios). Combinado con APIs como Responses, los desarrolladores ahora pueden construir agentes más útiles y confiables en ingeniería de software, extrayendo información útil de documentos extensos con un mínimo esfuerzo manual para resolver solicitudes de clientes y realizar otras tareas complejas. Al mismo tiempo, al mejorar la eficiencia del sistema de razonamiento, OpenAI ha podido reducir los precios de la serie GPT-4.1. El costo de consultas de tamaño mediano para GPT-4.1 es 26% más bajo que el de GPT-4o, y GPT-4.1 nano es el modelo más barato y rápido de OpenAI hasta ahora. Para consultas que reenvían el mismo contexto repetidamente, OpenAI ha aumentado el descuento por caché instantáneo del nuevo modelo de un 50% a un 75%. Además, más allá del costo estándar por token, OpenAI también ofrece solicitudes de largo contexto sin tarifa adicional. 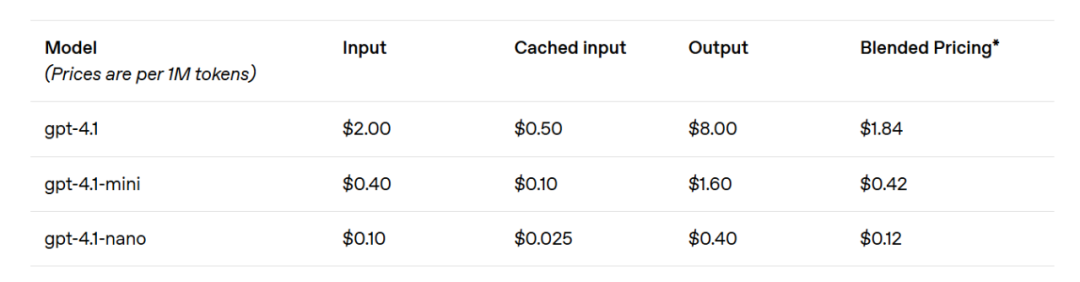
El CEO de OpenAI, Sam Altman, ha comentado que GPT-4.1 no solo ha sobresalido en las pruebas de referencia, sino que también se enfoca en la utilidad del mundo real, lo cual seguramente alegrará a los desarrolladores. 
Parece que OpenAI ha logrado un avance en las capacidades de su modelo, con un desempeño de "4.10>4.5". 
El historial visual sugiere que GPT-4.1 ha superado notablemente a GPT-4o en diversas tareas de codificación, incluyendo la resolución de tareas de codificación por parte de agentes, programación front-end, reducción de ediciones irrelevantes y lograr adherencia fiable al formato diff, así como consistencia en el uso de herramientas. En el examen SWE-bench Verified, que mide habilidades de ingeniería de software en el mundo real, GPT-4.1 completó 54.6% de las tareas, mientras que GPT-4o (2024-11-20) completó 33.2%. Esto refleja la capacidad del modelo para explorar bibliotecas de código, completar tareas y generar código ejecutable y validado. 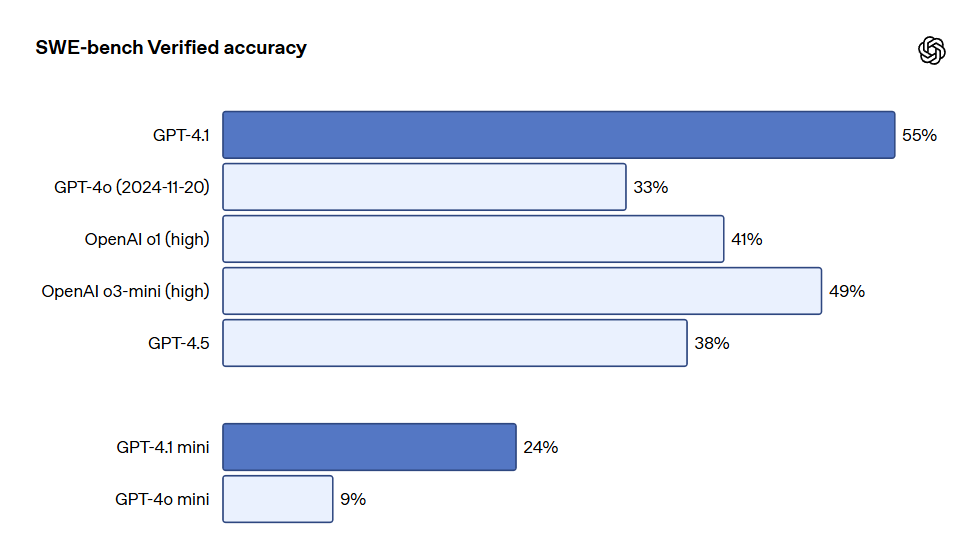
Para los desarrolladores de API que necesitan editar archivos grandes, GPT-4.1 ha demostrado ser más confiable en el manejo de diversas formas de diffs de código. En el benchmark Aider, GPT-4.1 tuvo un puntaje más de dos veces superior al de GPT-4o, superando incluso por un 8% a GPT-4.5. Esta evaluación medía la capacidad de codificación en múltiples lenguajes de programación y la habilidad para generar cambios tanto en formato general como diff. OpenAI ha entrenado a GPT-4.1 específicamente para que siga de forma más confiable el formato diff, permitiendo a los desarrolladores simplemente output cambios de líneas sin tener que reescribir todo el archivo, ahorrando así en costos y latencia. Al mismo tiempo, para aquellos desarrolladores que prefieren reescribir todo el archivo, OpenAI ha incrementado el límite de tokens de salida de GPT-4.1 a 32,768 tokens (superando los 16,384 tokens de GPT-4o). OpenAI también sugiere la utilización de la salida predictiva para reducir la latencia de reescritura de archivos completos. 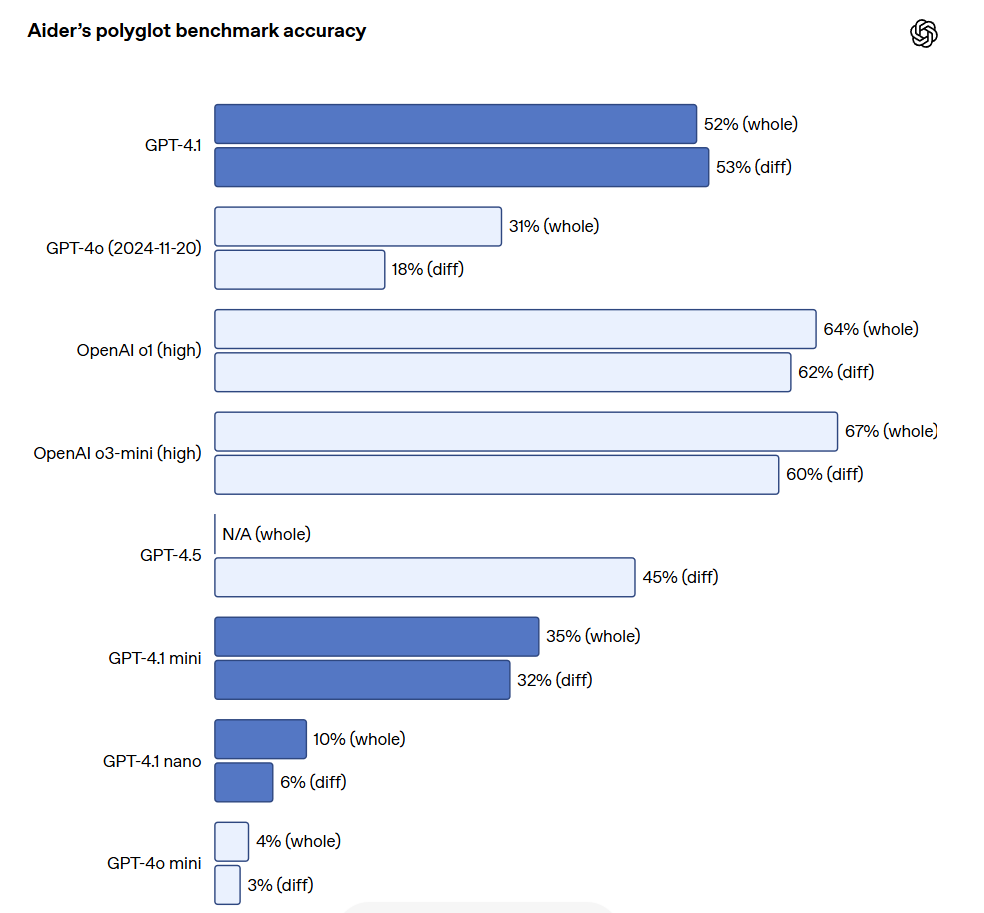
GPT-4.1 también ha mostrado mejoras significativas en la programación front-end en comparación con GPT-4o, permitiendo la creación de aplicaciones web más potentes y estéticamente atractivas. En comparaciones directas, el 80% de los puntajes de evaluadores humanos remunerados mostraron que los sitios web creados por GPT-4.1 eran más bien recibidos que los de GPT-4o. 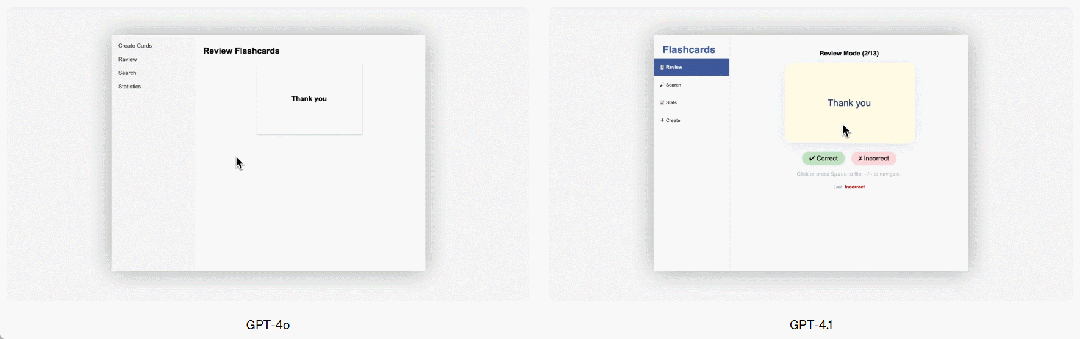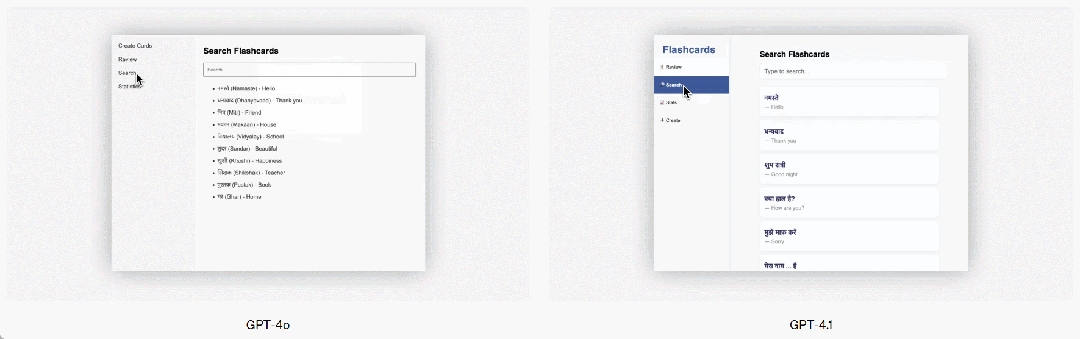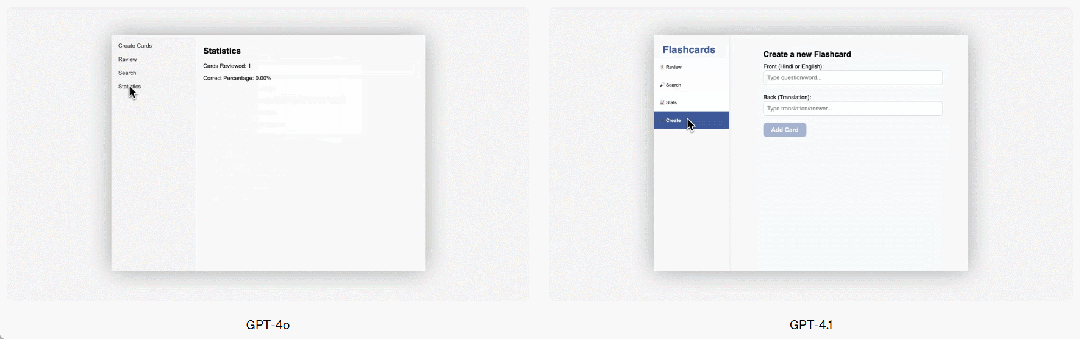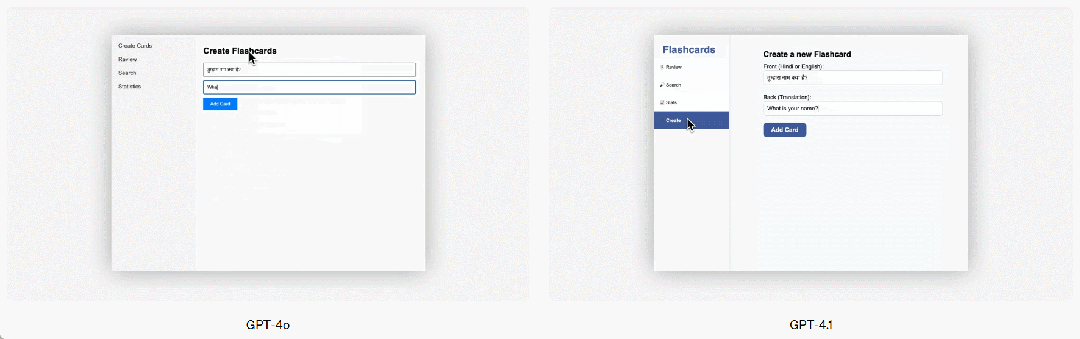
Más allá de los benchmarks mencionados, GPT-4.1 ha demostrado un mejor seguimiento de formatos, mayor confiabilidad y reducción en la frecuencia de ediciones irrelevantes. En evaluaciones internas de OpenAI, las ediciones irrelevantes en el código bajaron del 9% en GPT-4o al 2% en GPT-4.1.
GPT-4.1 es más confiable al seguir instrucciones y ha logrado mejoras significativas en varias evaluaciones de cumplimiento de instrucciones. OpenAI desarrolló un sistema interno de evaluación de cumplimiento de instrucciones para rastrear el rendimiento del modelo en múltiples dimensiones y en varias categorías de ejecución de instrucciones clave, tales como:
- Cumplimiento del formato. Proporcionar instrucciones que especifican el formato de respuesta del modelo, como XML, YAML, Markdown, entre otros.
- Instrucciones negativas. Especificar comportamientos que el modelo debe evitar, como "no solicitar al usuario que se ponga en contacto con el soporte".
- Instrucciones ordenadas. Proporcionar un conjunto de instrucciones que el modelo debe seguir en el orden dado, como "primero preguntar el nombre del usuario, luego preguntar su dirección de correo electrónico".
- Requerimientos de contenido. Generar contenido que contenga información específica, como "asegúrese de incluir el contenido de proteínas al escribir un plan nutricional".
- Clasificación. Clasificar las salidas de la respuesta de una manera específica, como "ordenar las respuestas por población".
- Sobreconfianza. Indicar al modelo que responda "no sé" o algo similar cuando la información solicitada no esté disponible o no pertenezca a la categoría dada, como "si no sabe la respuesta, proporcione la dirección de correo electrónico de contacto de soporte".
Estas categorías fueron derivadas del feedback de los desarrolladores, indicando qué instrucciones de cumplimiento eran más relevantes e importantes para ellos. Dentro de cada categoría, OpenAI las clasificó en indicaciones simples, medias y difíciles. GPT-4.1 se desempeñó especialmente bien en los indicios difíciles. 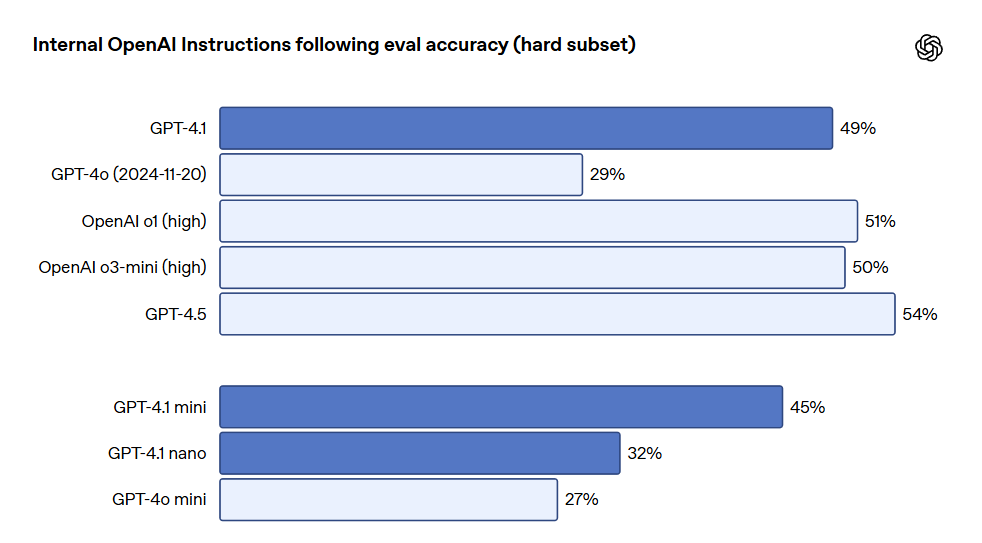
El seguimiento de instrucciones en múltiples turnos es crucial para muchos desarrolladores. Para el modelo, es fundamental mantener la coherencia en conversaciones y rastrear lo que los usuarios han ingresado anteriormente. GPT-4.1 es capaz de identificar información de mensajes anteriores en la conversación, logrando una interacción más natural. La evaluación MultiChallenge de Scale es un indicador efectivo de esta capacidad, donde GPT-4.1 mostró un 10.5% de mejora sobre GPT-4o. 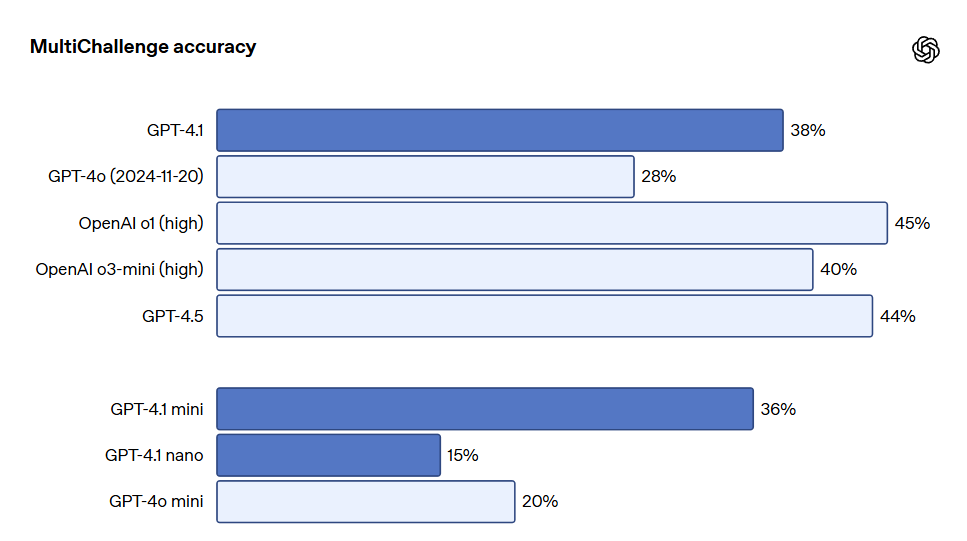
GPT-4.1 también obtuvo un puntaje de 87.4% en IFEval, mientras que GPT-4o alcanzó un 81.0%. IFEval utiliza indicaciones con instrucciones verificables, como especificar la longitud del contenido o evitar el uso de ciertos términos o formatos. 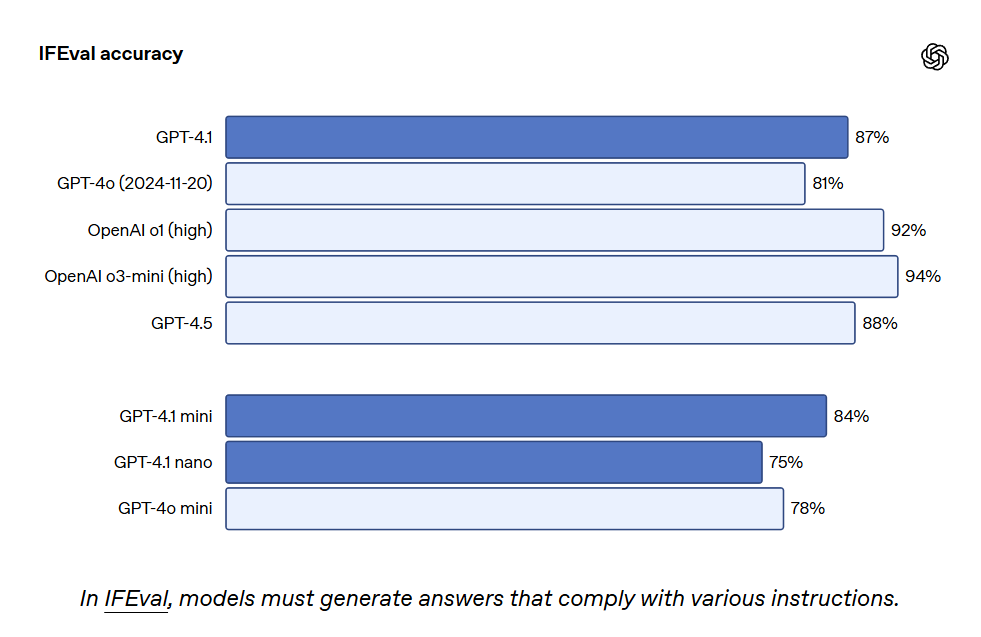
Las capacidades mejoradas de cumplimiento de instrucciones hacen que las aplicaciones existentes sean más confiables y también permiten apoyar nuevas aplicaciones que anteriormente se veían limitadas por la baja confiabilidad. Los primeros probadores señalaron que GPT-4.1 puede ser más intuitivo, por lo que OpenAI recomienda ser más explícito y específico en las indicaciones.
GPT-4.1, GPT-4.1 mini y GPT-4.1 nano pueden manejar hasta 1 millón de tokens de contexto, mientras que el modelo anterior GPT-4o solo podía manejar hasta 128,000. 1 millón de tokens equivale a 8 bibliotecas de código completas de React, por lo que la capacidad de largo contexto es ideal para manejar grandes bibliotecas de código o grandes documentos extensos. GPT-4.1 puede manejar de manera confiable información con una longitud de contexto de 1 millón de tokens y, en comparación con GPT-4o, es más confiable en atender texto relevante y en ignorar interferencias de contexto largo y corto. La comprensión de largo contexto es una capacidad clave en campos como derechos, programación, y atención al cliente, entre muchos otros. 
OpenAI ha demostrado la capacidad de GPT-4.1 para recuperar pequeñas informaciones ocultas (needle) ubicadas en diferentes puntos dentro de la ventana de contexto. GPT-4.1 es capaz de recuperar de manera continua con precisión needles de todas las posiciones y longitudes de contexto, con un volumen máximo de recuperación de hasta 1 millón de tokens. Sin importar dónde se encuentren esos tokens en la entrada, GPT-4.1 puede extraer de manera efectiva detalles relacionados con la tarea actual. Sin embargo, las tareas en el mundo real rara vez son tan sencillas como buscar una respuesta obvia de un "needle". OpenAI ha encontrado que los usuarios a menudo necesitan que el modelo recupere y comprenda varias cadenas de información, además de entender las relaciones entre ellas. Para demostrar esta capacidad, OpenAI ha lanzado una nueva evaluación: OpenAI-MRCR (referencia multivocal). OpenAI-MRCR evalúa la habilidad del modelo para reconocer y eliminar múltiples needles ocultos en el contexto. La evaluación incluye diálogos sintéticos de múltiples turnos entre un usuario y un asistente, en los que el usuario pide al asistente que escriba un artículo sobre un tema específico, como "escribe un poema sobre un tapir" o "escribe un blog sobre rocas", y luego se insertan dos, cuatro u ocho solicitudes iguales en el contexto a lo largo, al final, el modelo debe recuperar la respuesta correspondiente a una instancia específica (por ejemplo, "dame el tercer poema sobre un tapir"). El desafío radica en la similitud de estas solicitudes con el resto del contexto, donde el modelo puede verse fácilmente confundido por matices, como una historia corta sobre un tapir en lugar de un poema, o en lugar de un poema sobre un tapir, uno sobre una rana. OpenAI ha descubierto que GPT-4.1 se desempeña mejor que GPT-4o con longitudes de contexto de hasta 128,000 tokens, y mantiene un rendimiento robusto incluso con longitudes de hasta 1 millón de tokens. 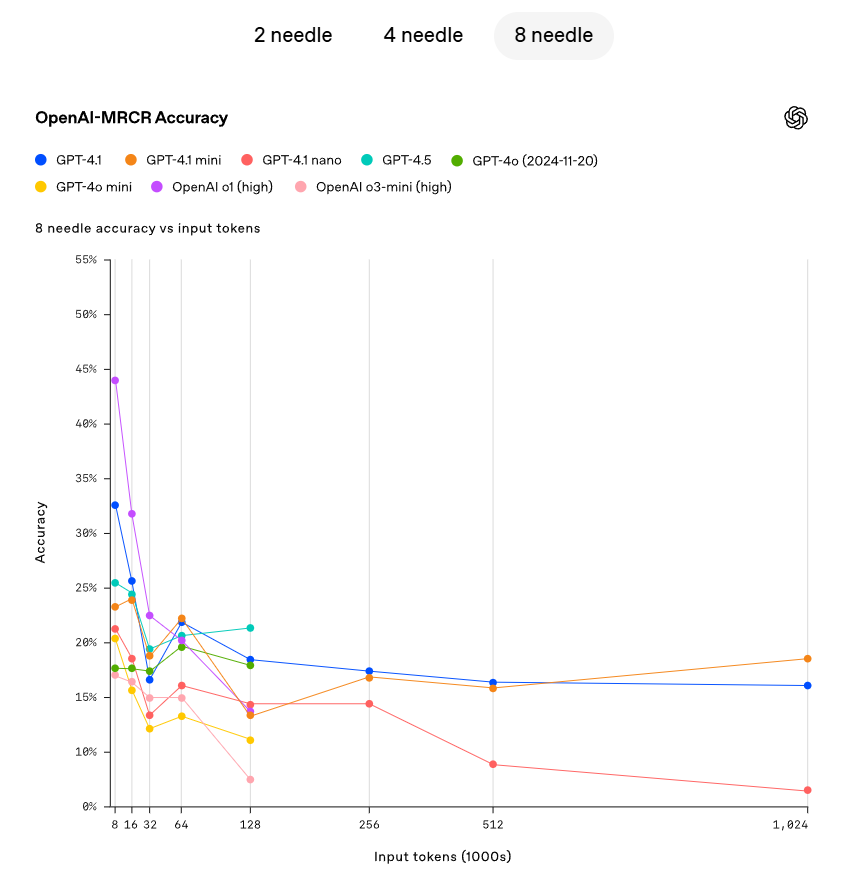
OpenAI también ha lanzado Graphwalks, un conjunto de datos para evaluar el razonamiento en contextos largos de múltiples saltos. Muchos desarrolladores necesitan realizar múltiples saltos lógicos en contextos largos, como al cambiar entre múltiples archivos al escribir código o al referenciar documentos complejos al resolver problemas legales. En teoría, un modelo (e incluso un humano) podría resolver los problemas de OpenAI-MRCR leyendo repetidamente la indicación, pero el diseño de Graphwalks requiere razonamiento en varios puntos dentro del contexto y no se puede resolver secuencialmente. Graphwalks llena la ventana de contexto con un gráfico dirigido compuesto de valores hash en hexadecimal, y luego pide al modelo realizar una búsqueda en amplitud (BFS) comenzando desde nodos aleatorios en el gráfico. Luego se le pide que devuelva todos los nodos a una profundidad determinada. Los resultados muestran que GPT-4.1 alcanzó una precisión del 61.7% en esta evaluación, comparable al rendimiento de o1, superando claramente a GPT-4o. 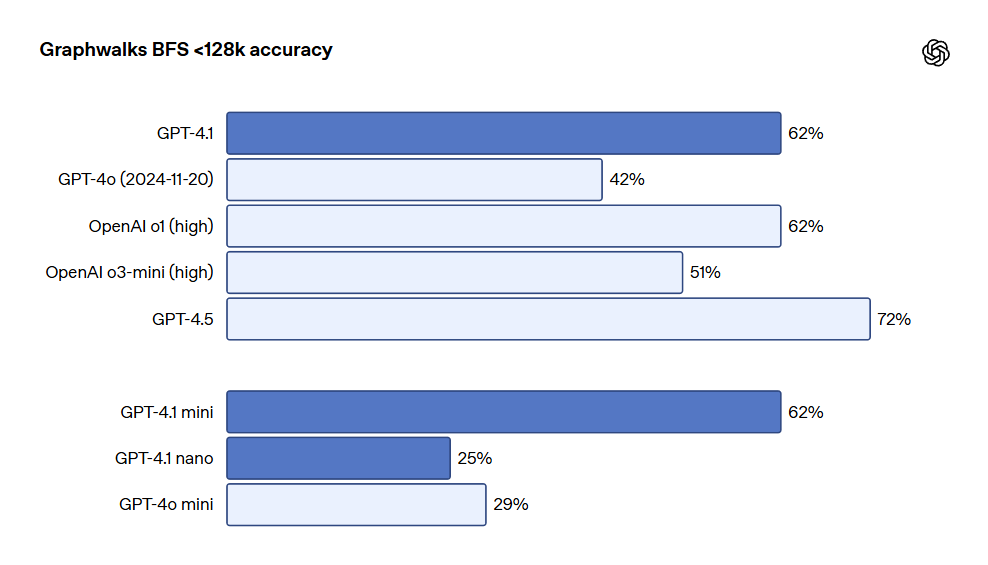
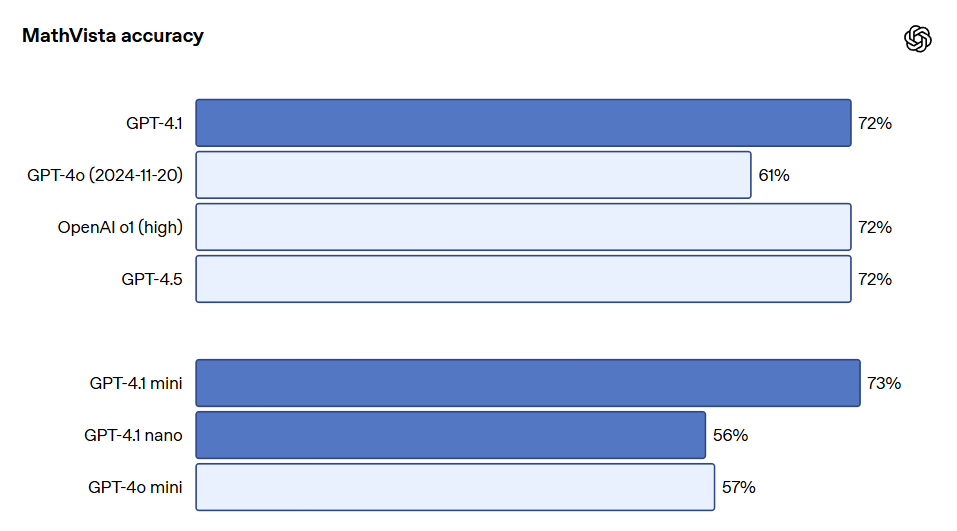
La serie de modelos GPT-4.1 también es extremadamente potente en la comprensión de imágenes, especialmente GPT-4.1 mini, que ha logrado un avance significativo, superando frecuentemente a GPT-4o en pruebas de imágenes. A continuación se presentan comparaciones de rendimiento en benchmarks como MMMU (responder preguntas que contienen gráficos, ilustraciones, mapas, etc.), MathVista (resolver problemas matemáticos visuales), y CharXiv-Reasoning (responder preguntas sobre gráficos en documentos científicos). 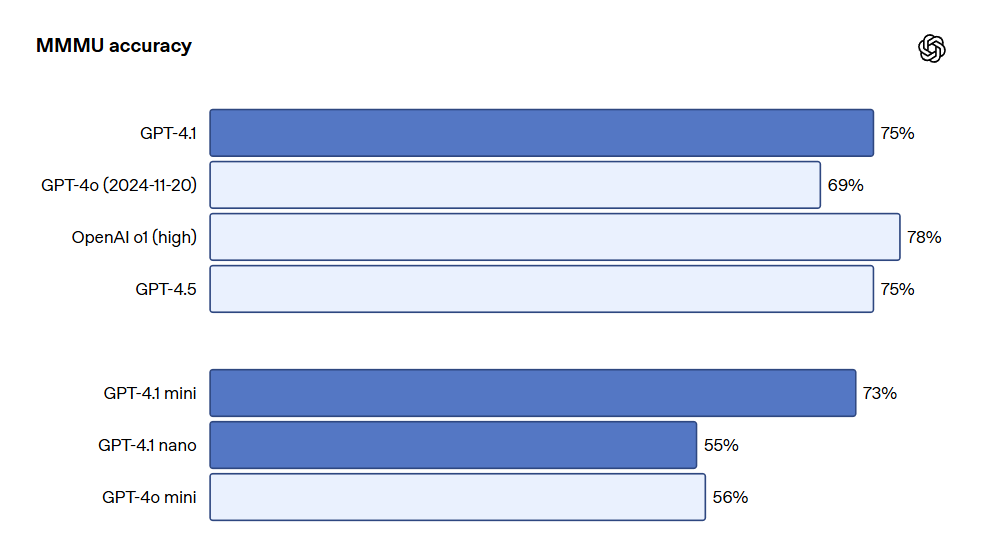
El rendimiento de largo contexto también es crucial para casos de uso multimodal (por ejemplo, al manejar videos largos). En Video-MME (videos largos sin subtítulos), el modelo responde a preguntas de opción múltiple basadas en videos silenciosos de 30 a 60 minutos. GPT-4.1 ha logrado el mejor rendimiento hasta la fecha, con un puntaje de 72.0%, superior al 65.3% de GPT-4o. 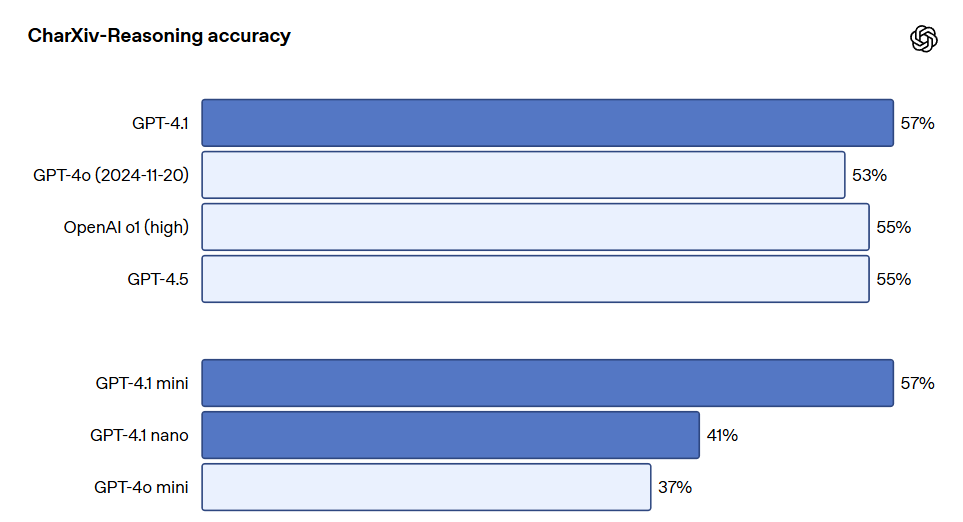
Para más detalles sobre métricas de pruebas, consulte el blog original de OpenAI. Blog: https://openai.com/index/gpt-4-1/
Nuestras Increíbles Reseñas

FLUX Kontext: El Mejor Generador de Imágenes AI para Editar y Crear
Descubre cómo FLUX Kontext revoluciona la edición de imágenes con su potente modelo de generación y edición.

FLUX.1 Kontext: El Mejor Generador de Imágenes AI para Creación y Edición
FLUX.1 Kontext es un modelo innovador de generación y edición de imágenes AI que ofrece capacidades avanzadas de creación contextual.

Mejor Generador de Imágenes AI: Qwen3 Revoluciona el Modelo Local
Qwen3 lanza modelos AI de alto rendimiento, permitiendo una fácil implementación local y generando sorprendentes resultados.

HiDream: El Mejor Generador de Imágenes AI del Futuro
HiDream ha capturado rápidamente la atención de los entusiastas de la pintura AI de código abierto en todo el mundo con su capacidad innovadora para generar imágenes de alta calidad.

Vidu Q1: El Mejor Generador de Videos AI del Mercado
Vidu Q1 permite generar videos en alta calidad a partir de textos o imágenes, destacándose por su innovadora tecnología y precios competitivos.

El Mejor Generador de Imágenes AI: Cómo Usar GPT-4o para Crear Imágenes Asombrosas
Descubre cómo usar el generador de imágenes AI GPT-4o para crear imágenes impresionantes con solo un prompt.

Mejor Generador de Imágenes AI: Crea Arte al Estilo de Studio Ghibli con Liblib AI
Descubre cómo crear imágenes al estilo de Studio Ghibli fácilmente con Liblib AI.

Los Mejores Generadores de Imágenes AI: Raphael AI y MiaoHua
Explora dos herramientas de generación de imágenes AI completamente gratuitas: Raphael AI y MiaoHua, que ofrecen calidad impresionante sin costos ocultos.

CatPony: El Mejor Generador de Imágenes AI de Estilo Pony
Recomendamos un modelo excepcional de estilo Pony, destacando sus características visuales y detalles únicos.

Los Mejores Generadores de Imágenes AI: Crea Figuras Lindas con GPT-4o
Descubre dos plataformas para generar figuras adorables de GPT-4o: ① Duìyǒu; ② liblibAI.

FLUX nunchaku: ¡El Mejor Generador de Imágenes de IA con Velocidad en Tiempo Real!
Descubre el revolucionario nunchaku FLUX, un generador de imágenes de IA que mejora velocidad y calidad.

Lanzamiento de GPT-4.1 por OpenAI: El Mejor Generador de Imágenes AI
OpenAI ha lanzado el nuevo modelo GPT-4.1, que incluye mejoras significativas en programación, seguimiento de instrucciones y comprensión de contextos largos.

La Revolución de la Edición de Fotos AI: ¡Transforma tus Imágenes en 3 Segundos con AIEASE, el Mejor Generador de Imágenes AI!
Descubre AIEASE, una herramienta revolucionaria de edición de fotos AI que transforma cómo manipulamos imágenes.

Explorando los Mejores Generadores de Imágenes AI: Estilo Único de Animales y Humanos
Descubre un estilo de modelo especial que combina animales y humanos, revelando la absurdidad en la realidad.